Indexing - Query Plan and Performance Optimisation
هل الـ Indexing مهم كما درسناه ؟
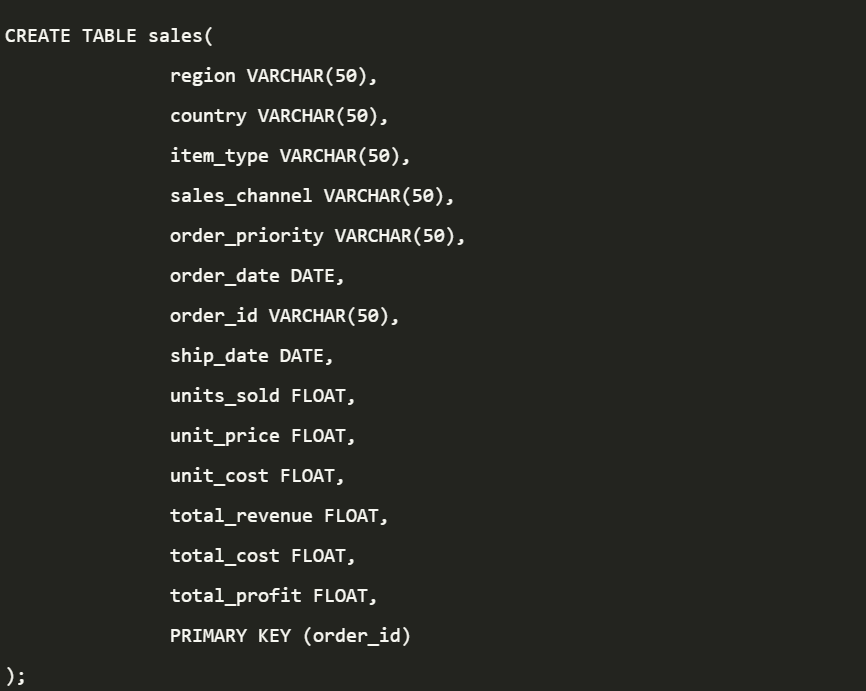
أردت أن أجرب بنفسي تطبيق ذلك من خلال عمل الـ Indexing في الـ Database حتى أتابع سلوكه على أرض الواقع بدلاً من الكلام النظري الذي درسه معظمنا .. فقمت بتحميل Datasets فيها 1,000,000(مليون) Records حتى ابدا بقياس الـ Performance الخاص بالـ Queries وكانت الـ Database: PostgreSQL ..
قمت بانشاء Table في الـ Database وسميته Sales وعمل Import للـ CSV File اللي فيه الـ Datasets .. فما الذي حدث ؟
وحتى اتأكد من أن كل شيء يسير على ما يرام قمت بتنفيذ الـ Query:
وكان نتيجة الـ Query هي أنها رت بالـ 1,048,575 Records وأخذت وقت يقارب 2.5 Seconds لكي تـ Return Responses .. وهذا نوعًا ما منطقي لإني طلبت من الـ Database أن تعيد لي كل الـ Records اللي موجودة .. ولكن ماذا لو أردت أن افهم اكثر ما الذي حدث فكيف يمكنني ذلك ؟
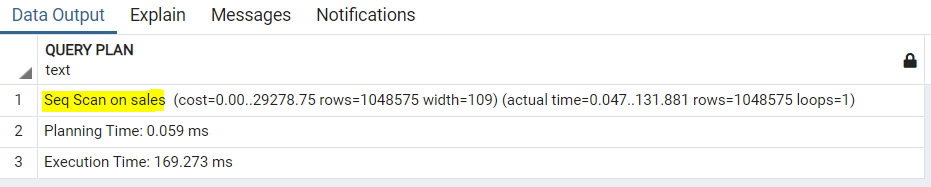
الاجابة وبكل بساطة هي في زيادة كلمتين قبل الـ Query وهم الـ EXPLAIN ANALYZE ولكن لماذا ؟
حتى أستطيع فهم الـ Query Plan التي ستتبعها الـ DBMS حتى تنفذ الـ Query.
فيمكننا رؤية أن الـ DBMS اتبعت الـ Seq Scan، بمعنى أدق قامت الـ DBMS بعمل Iteration على الـ Data كلها واحدة تلو الأخرى لكي ترجعها إليك وهذا هو المطلوب .. ولزيادة التأكيد من الممكن عمل Query تانية لمعرفة عدد الـ Records بالتحديد وهي:
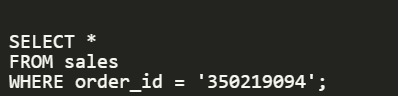
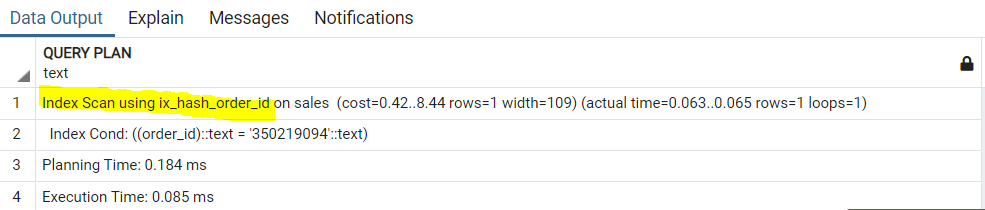
والآن ماذا لو حاولنا ارسال Query للـ Database حتى ترجعلنا الـ Record الخاص بالـ Order Id الذي نريده .. فبكل بساطة سنقوم بكتابة Query بهذا الشكل:
والمفاجاة هنا أن الـ Response هيرجع بسرعة جدًا .. تقريبًا 50ms .. من وسط 1,048,575 قدرت الـ Database انها ترد عليا في 50ms ولكني لا أعرف السبب .. وحتى افهم ذلك بشكل أفضل سنقوم باضافة EXPLAIN ANALYZE ولكننا سنتفاجئ هنا بشيء غريب ألا وهو .. أن في الـ Query Plan الذي سينفذها الـ DBMS نرى أنه سيقوم بعمل Index Scan ولكن هذا غير منطقي ، لاني وبكل بساطة لم أطلب منه بعد عمل Index ..
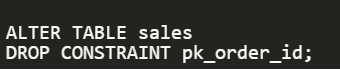
في الحقيقة معظم الـ DBMS ذكية جدًا حتى تفهم وتقوم بجعل الـ Primary Key هو Clustered Index للـ Table وسنفهم بعد قليل ما الذي يعنيه هذا ، وحتى ندرك ما حدث سنقوم بمسح الـ Primary Key من الـ Table ..
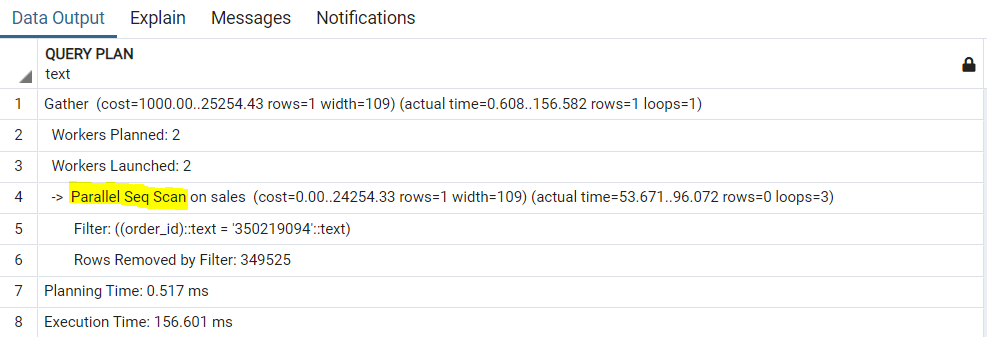
إذا قمنا بارسال نفس الـ Query مرة أخرى الآن .. سنجد انها يتم تنفيذها في وقت سريع ايضًا على الرغم من مسح الـ Primary Key أي أن الـ Clustered Index تم مسحه .. ولكن الـ DBMS مازالت ذكية وتحاول انها تـ Return الـ Response بأسرع شكل ممكن وذلك من خلال استعمال الـ Run Workers حتى يتم تنفيذ الـ Query بشكل أسرع وذلك عن طريق الـ Parallelism ..
فدعونا نقوم بالغاء هذا أيضًا عن طريق: Set Max Parallel workers = 0 حتى نضمن عدم وجود أي سلوك غير مرغوب فيه.
إذا قمنا باعادة المحاولة الآن سنرى أنها أخذت تقريبًا من 300 – 500 ms وهذا مقبول ..
فإذن بدون Index الـ Query ردت بالـ Response في 500ms كاسوأ احتمال ولو أردنا فهم ما الذي تم سنقوم بفعل ما سبق وسنجد انه بالفعل حصل Seq Scan ..
في حين انه عندما كان هنالك Primary Key او بشكل آخر Index كان الـ Response تقريبًا 50ms وهو ما يعادل تقريبًا 10 مرات الـ Response من غير Index ..
وعندما قمت بتكرار الـ Data لجعلها 20 مليون من غير ترتيب كان الاداء عظيم جدًا فبدون الـ Index كانت الـ Query ترد الـ Response بعد 5 ثواني وهذا لإن اللابتوب الذي استعمله امكانياته ممتازة ولكن باستعمال الـ Index الـ Query كان الـ Response تقريبًا 50ms فقط وهذا شيء عظيم جدًا .. فلك ان تتخيل انه من الممكن للـ Result ألا تعود إليك أحيانًا وذلك لان الـ Query حتى تعمل ستاخذ وقت كبير جدًا من الممكن أن يصل إلى ساعة في حين اننا يمكننا تحسين ذلك وجعلها تأخذ بضع ثوان.
ما هو الـ Indexing ؟
النشرة الأسبوعية
اشترك الآن في نشرة اقرأتِك الأسبوعية
لا تدع أي شيء يفوتك. احصل على أحدث المقالات والشروحات البصرية ومدونات الشركات العالمية مباشرة إلى بريدك الإلكتروني — وبشكل مجاني تمامًا.