شركة Uber بتستعمل Docstore وهو عبارة عن قاعدة البيانات الموزعة بتاعتهم واللي مبنية على MySQL و Docstore بتخزن عشرات الـ PetaBytes من البيانات وبتخدم عشرات الملايين من ال Requests في الثانية.
شركة Uber بتستعمل Docstore وهو عبارة عن قاعدة البيانات الموزعة بتاعتهم واللي مبنية على MySQL و Docstore بتخزن عشرات الـ PetaBytes من البيانات وبتخدم عشرات الملايين من ال Requests في الثانية.
ودي واحدة من أكبر محركات قواعد البيانات عند Uber واللي بتستخدمها كتير من الـ Microservices في كل القطاعات التجارية أو اللي بنسميها Business Verticals عندهم.
والكلام ده من ساعة ما بدأت في 2020، عدد المستخدمين وحالات الاستخدام بتاعت Docstore في ازدياد، وكمان حجم الطلبات والبيانات في زيادة.
المطالب المتزايدة من القطاعات التجارية واحتياجاتهم بتضطر تقدم Microservices معقدة جدًا. وبالتالي، التطبيقات بتطلب زمن استجابة قليل Latency، وأداء عالي High Performance، وقابلية توسع من قاعدة البيانات Scalability، وفي نفس الوقت الكلام ده بيولد Workloads وأحمال عالية.
التحديات
معظم الـ Microservices في Uber بتستخدم قواعد بيانات مدعومة بتخزين على الـ Disk عشان تحافظ على البيانات والـ Durability بتاعتها. ومع ذلك، كل قاعدة بيانات بتواجه تحديات في خدمة التطبيقات اللي بتحتاج زمن استجابة قليل وقدرة توسع عالية.
ده وصل لدرجة الأزمة لما في حالة من الحالات طلبت معدل قراءة أعلى بكتير من أي مستخدم حالي. وكان ممكن Docstore تلبى احتياجاتهم لأنها مدعومة بـ NVMe SSDs، ,اللي بدورها بتوفر زمن استجابة قليل ومعدل نقل عالي. بس استخدام Docstore في الحالة دي كان هيبقى مكلف جدًا وكان هيطلب كتير من التوسع Scalability والتحديات التشغيلية اللي هي الـ Operational Challenges.
فقبل ما ندخل في التحديات، خلينا نفهم الـ High-Level Architecture لـ Docstore.
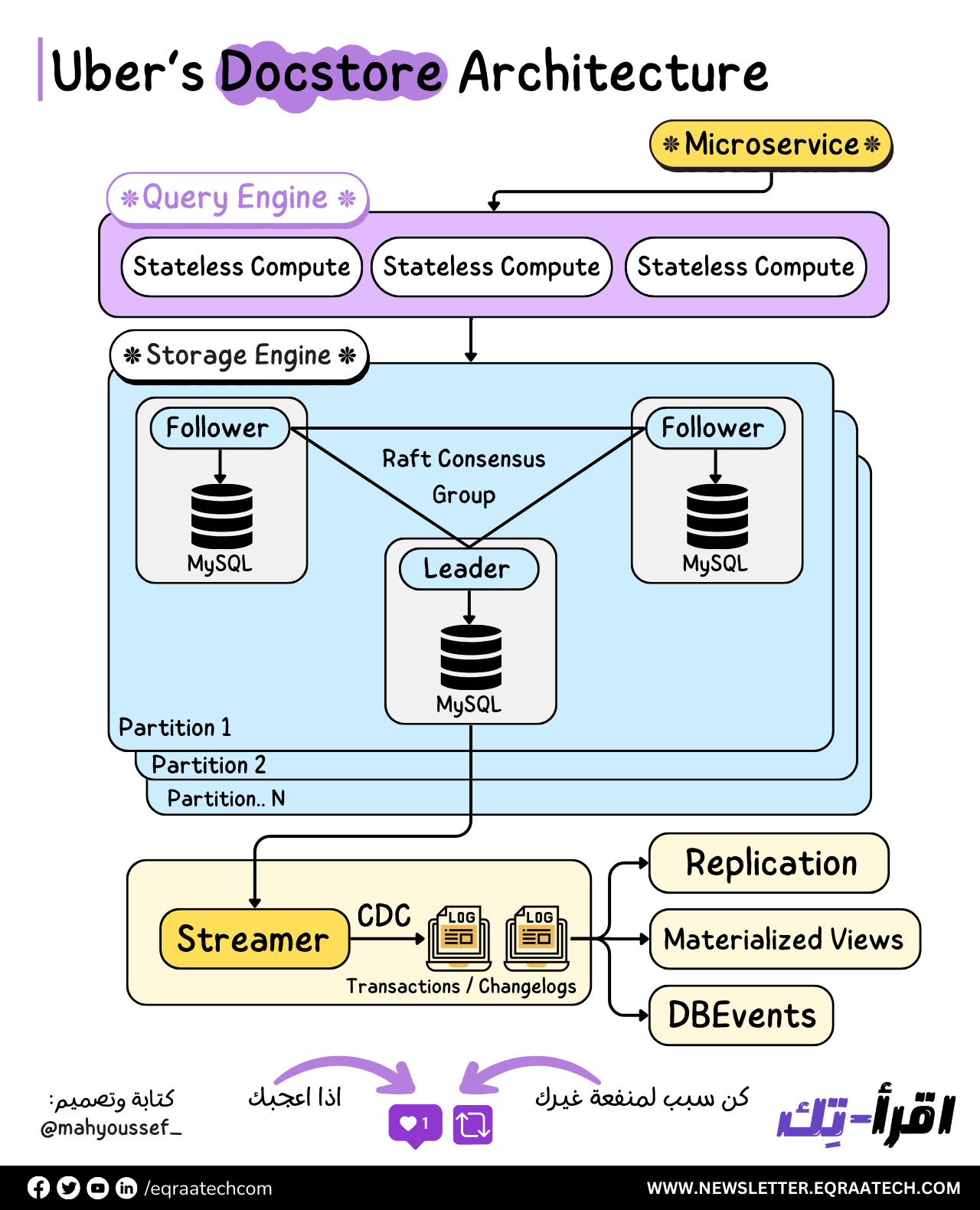
Docstore Architecture
هنلاقي أن Docstore متقسمة بشكل رئيسي لثلاث أجزاء أو طبقات Layers : 1- الـ Stateless Query Engine Layer 2- الـ Stateful Storage Engine Layer 3- الـ Control Plane
Docstore Architecture
وللتذكير Stateless من اسمها يعني مش مسئولة عن الاحتفاظ بأي State نهائيًا أو معلومات ، بينما الـ Stateful فهي بتحتفظ بالـ State أو بعض المعلومات عشان تستفيد منها في أداء شغلها.
واحنا هنركز كلامنا فقط على الجزئين الأول والثاني من الـ 3 طبقات دول.
الـ Stateless Query Engine مسئول بشكل أساسي عن الـ Query Planning والـ Routing والـ Sharding والـ Schema Management وكمان الـ Node Health Monitoring والـ Request Parsing والـ Validation والـ AuthN/AuthZ.
والـ AuthN اللي هي اختصار لـ Authentication والـ AuthZ اختصار للـ Authorization.
بينما الـ Stateful Storage Engine مسئول بشكل أساسي عن تحقيق الـ Consensus من خلال Raft وده طبعًا بيتم استعماله بشكل أساسي في النظم الموزعة لضمان تحقيق الـ Replication بكفاءة واتساق البيانات أو ما يعرف بالـ Consistency.
والـ Storage Engine كذلك مسئول عن الـ Replication والـ Transactions والـ Concurrency Control والـ Load Management.
وزي ماحنا شايفين في الصورة احنا عندنا أكتر من Partition كل جزء بيكون عبارة عن بعض الـ MySQL Nodes مدعومة بـ NVMe SSDs واللي قادرة على انها تتحمل الأحمال الثقيلة في القراءة والكتابة Heavy Read and Write Workloads.
البيانات متقسمة على أكتر من جزء وكل جزء بيكون فيه Leader واحد , و 2 Follower وطبعا من خلال استعمال Raft لتحقيق الـ Consensus.
التحديات لما الخدمات بتطلب قراءات بزمن استجابة قليل وبمعدل عالي:
سرعة استرجاع البيانات من الـ Disk ليها حد: في حد لتحسين الـ Data Models والـ Queries عشان نحسن زمن الاستجابة والأداء. ولكن بعد كده، هنوصل لحيطة سد وده لان تحسين الأداء أكتر من كده مش هيبقى ممكن.
التوسع الرأسي Vertical Scaling: تخصيص موارد أكتر أو استخدام أجهزة أفضل هيكون برضو ليها حدود واللي وقتها هيكون محرك قاعدة البيانات بنفسه هو الـ Bottleneck.
التوسع الأفقي Horizontal Scaling: تقسيم البيانات على مزيد من الأجزاء ممكن يساعد بشكل ما أو بآخر ولكن برضو هيكون محدود وهيبقى عملية معقدة وطويلة. وده لاننا لازم نضمن استمرارية الـ Durability والـ Resilience للبيانات من غير أي Downtime يحصل. وكمان الحل ده مش بيحل المشكلة بالكامل وهيعرضنا لمشاكل تانية زي الـ Hot Keys/Shards/Partitions.
اختلال التوازن بين الـ Requests: كتير من الأحيان معدل طلبات القراءة بيكون أعلى بكتير من الكتابة. في الحالات دي، الـ MySQL Nodes الأساسية بتكافح عشان تواكب الحمل الثقيل اللي متعرضة ليه وده بيأثر على زمن الاستجابة Latency.
التكلفة: التوسع الرأسي والأفقي لتحسين زمن الاستجابة مكلف على المدى الطويل. والتكاليف دي بتتضاعف 6 مرات عشان تتعامل مع كل من الـ 3 Nodes في الـ Regions المختلفة. وكمان، التوسع مش بيحل المشكلة بالكامل.
عشان نحل المشكلة دي، الـ Microservices بتستخدم الـ Caching. وفي Uber بيستعملوا Redis™ كـ Distributed Caching ، ومن أشهر الـ Design Patterns اللي بيتم تطبيقها في الـ Microservices هي الكتابة لقاعدة البيانات والـ Cache في نفس الوقت وتقديم طلبات القراءة Read Request Serving من الـ Cache لتحسين زمن الاستجابة Latency. بس برضو النموذج ده ليه بعض التحديات:
كل فريق لازم يخصص ويـ Maintain الـ Cache Redis الخاص بيه للـ Services بتاعته.
الـ Cache Invalidation Logic متنفذ بشكل لا مركزي في كل الـ Microservices لان كل فريق هيكون مسئول عنه.
في حالة حدوث مشكلة في الـ Region وحصل Failover، الـ Services لازم يا اما تحتفظ بنسخ الـ Cache عشان تكون مستعدة لأي عمليات قراءة تحصل أو تتحمل زمن استجابة أعلى Higher Latencies لغاية مالـ Cache يكون مستعد في الـ Regions التانية اللي هيحصلها الـ Failover.
الفرق الفردية بتبذل مجهود كبير في تنفيذ الـ Caching Solutions الخاصة بيهم مع قاعدة البيانات. ولكن أصبح من الضروري إننا نلاقي حل أفضل وأكثر كفاءة عشان يـ Handle الطلبات بزمن استجابة قليل، ويكون سهل الاستخدام ويزيد كمان من إنتاجية المطورين.
CacheFront
فـ Uber قررت تبني Integrated Caching Solution وهو CacheFront لـ Docstore، بالأهداف التالية:
تقليل الحاجة للتوسع الرأسي أو الأفقي لدعم طلبات القراءة بزمن استجابة قليل.
تقليل تخصيص الموارد أو الـ Resources للـ Database Engine Layer؛ الـ Caching ممكن يتبني من أجهزة رخيصة نسبيًا، وبالتالي كفاءة التكاليف الكلية تتحسن كتير.
تحسين زمن الاستجابة P50 وP99، وتثبيت استقرار زمن الاستجابة خلال الـ Spikes اللي بتحصل في الفترات القصيرة من الضغط.
استبدال معظم الـ Caching Solutions المخصصة اللي كانت بنيتها أو هتبنيها الفرق الفردية لتلبية احتياجاتها، خاصة في الحالات اللي الـ Caching مش هو النشاط الأساسي أو الكفاءة الأساسية للفريق.
تحقيق الـ Transparency من خلال إعادة استخدام الـ Docstore Client الحالي من غير أي كود إضافي عشان يستفيدوا من الـ Caching.
زيادة إنتاجية المطورين وتمكينهم من إطلاق ميزات جديدة أو استبدال تقنية الـ Caching الأساسية بشكل شفاف للعملاء.
فصل الـ Caching Solution عن نظام تقسيم Docstore الـ Partitioning عشان نتجنب المشاكل اللي بتنتج من الـ Hot Shards/Keys/Partitions.
امكانية تحقيق التوسع الأفقي للـ Caching Layer بشكل مستقل عن الـ Storage Engine.
نقل مسؤولية صيانة Redis من الفرق المختلفة لفريق Docstore.
تصميم CacheFront
Docstore Query Patterns
الـ Docstore بيدعم طرق مختلفة للـ Query إما من خلال الـ Primary Key أو الـ Partition Key مع إمكانية عمل Filtering للبيانات.
فريق مهندسين Uber قرروا يبنوا الحل بتاعهم بشكل تدريجي، بدءًا من أنماط الاستعلام الأكثر شيوعًا.
اتضح إن أكتر من 50% من الـ Queries اللي بتيجي لـ Docstore هي طلبات ReadRows، وبما إن ده كمان كان أسهل حالة استخدام فكان ده المكان الطبيعي للبدء بدمج الـ Cache.
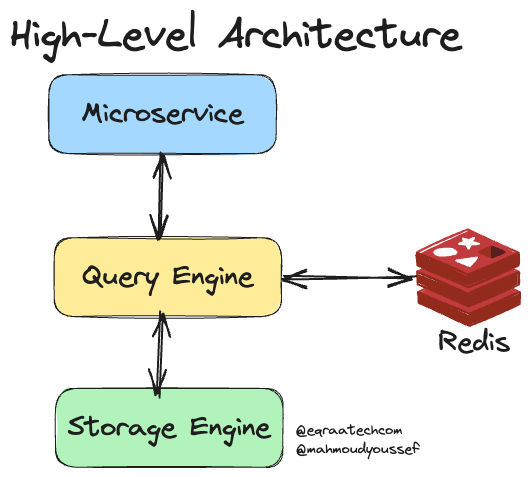
High Level Architecture
بما إن الـ Query Engine في Docstore مسؤولة عن انها تـ Serve الـ Reads / Writes، فهي أفضل مكان مناسب لدمج الـ Caching Layer.
CacheFront High Level Architecture
ده كمان بيفصل الـ Caching عن التخزين المعتمد على الـ Disk واللي مسئول عنه الـ Storage Engine عشان الـ Durability واللي ذكرناها قبل كده، فده بيسمح باننا نـ Scale أي واحد فيهم بشكل مستقل تمامًا عن التاني.
الـ Query Engine بتـ Implement Interface لـ Redis عشان تخزن الـ Cached Data مع وجود آلية نضمن بيها اننا نقدر نـ Invalidate الـ Cached Entries.
وبما أن Docstore هي قاعدة بيانات قوية التوافق أو بنسميها Strongly Consistent.
وعلى الرغم من إن الـ integrated Caching بيوفر استجابات أسرع للـ Queries، الا أن في بعض الحالات اللي الـ Consistency ممكن ما تكونش مقبولة لكل Microservices أثناء استخدام الـ Cache. فعلى سبيل المثال، ممكن الـ Cache Invalidation يحصله مشكلة ويفشل أو يتأخر عن الـ Writes اللي بتحصل في قاعدة البيانات.
فعشان كده، كان الذكاء هنا ان هم يخلوا الـ Integrated Caching Solution ده ميزة اختيارية. والـ Services تقدر تقرر اذا كانت هتستخدم الـ Cache ولا لا من خلال الـ Configuration فممكن الـ Cache يكون على مستوى قاعدة البيانات، الجدول، وحتى على مستوى الـ Request.
فدلوقتي لو في Flows معينة بتتطلب Strong Consistency (زي الحصول على العناصر اللي موجودة في سلة المتسوق) ممكن وقتها نتجاهل ونعدي الـ Cache ولا اكنه موجود، بينما الـ Flows التانية اللي بيكون فيها معدل كتابة قليل (زي اننا نجيب قائمة مطعم يعني نعملها Fetching) هتستفيد جدا من الـ Cache.
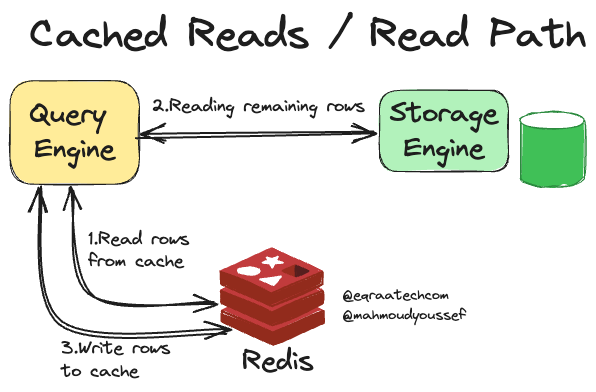
Cached Reads
الـ CacheFront بيستخدم استراتيجية الـ Cache Aside عشان الـ Cached Reads ودي كنا اتكلمنا عنها قبل كده في ورقة وقلم عن الاستراتيجيات المختلفة للـ Caching ولكن عشان نفتكره مع بعض فالـ Cache Aside بيكون كالآتي:
Cached Reads
الـ Query Engine بيستقبل Read Request لـ Row أو أكتر.
لو كان الـ Cache مفعل، بنحاول نجيب الصفوف دي من Redis ونرجع البيانات للـ User.
لو فيه صفوف متبقية في الـ Storage Engine بنجيبها.
وبعدين بنعمل Population للبيانات اللي كانت ناقصة ومش موجودة في Redis بشكل غير متزامن يعني Asynchronous.
وآخيرًا بنبعت الصفوف اللي كانت متبقية للـ Users بعد ما عملنا Update للـ Cache.
“There are only two hard things in Computer Science: cache invalidation and naming things.”
– Phil Karlton
على الرغم من إن استراتيجية الـ Cached Reads اللي في ذكرناها في الجزء اللي فات ممكن تبان بسيطة، الا ان فيه تفاصيل كتير لازم تتاخد في الاعتبار عشان نضمن إن الـ Cache يشتغل بشكفل فعال، خاصة مع الـ Cache Invalidation.
فمن غير أي Cache Invalidation صريح، الـ Cached Entries (بعد 5 دقائق ودي المدة الـ Default) ممكن تبقى قديمة، والعميل ممكن يشوف بيانات قديمة أو في أسوأ الحالات، هيشوف بيانات غير صحيحة.
وعلى الرغم أن ممكن ده يكون مناسب في بعض الحالات الا ان أغلب الـ Users بيكونوا متوقعين ان التغييرات تتأثر بشكل أسرع من مدة الـ TTL.
فالـ Default TTL ممكن تبقى أقل وفي الحالة دي هتقابلنا مشكلة تانية الا وهي ان معدل الـ Cache Hits هيقل ولكن من غير تحسين أي ضمانات للـ Consistency.
والـ Cache Hit للتذكرة معناه انك روحت تجيب الـ Data من الـ Cache ولقيتها موجودة بالفعل بينما الـ Cache Miss هو العكس , فانت حاولت تجيب الـ Data من الـ Cache وما لقيتهاش موجودة.
Conditional Update
زي ماشوفنا في الـ Query Patterns بتاعة Docstore انه بيدعم الـ Filtering فممكن يكون عندنا Conditional Updates زي مثلا انا عاوز اعمل Update للـ Holiday Schedule لكل المطاعم اللي موجودة في المنطقة المعينة.
وبما ان النتائج اللي هتطلع من الـ Conditional Update دي ممكن تتغير مع الوقت , وبما ان الـ Cache ما بيكونش معاه Context كافي زي الـ Storage Engine , فاننا نـ Invalidate Cached Entries بناءًا على الـ Conditional Updates هيبقى شبه مستحيل ، لاننا مش عارفين الـ Rows اللي اتغيرت.
فبالتالي ما بيحصلش Cache Invalidation أو Population للـ Rows اللي بيحصلها Conditional Updates في الـ Query Engine Write Path ، طب نحل المشكلة دي ازاي ؟
Leveraging Change Data Capture for Cache Invalidation