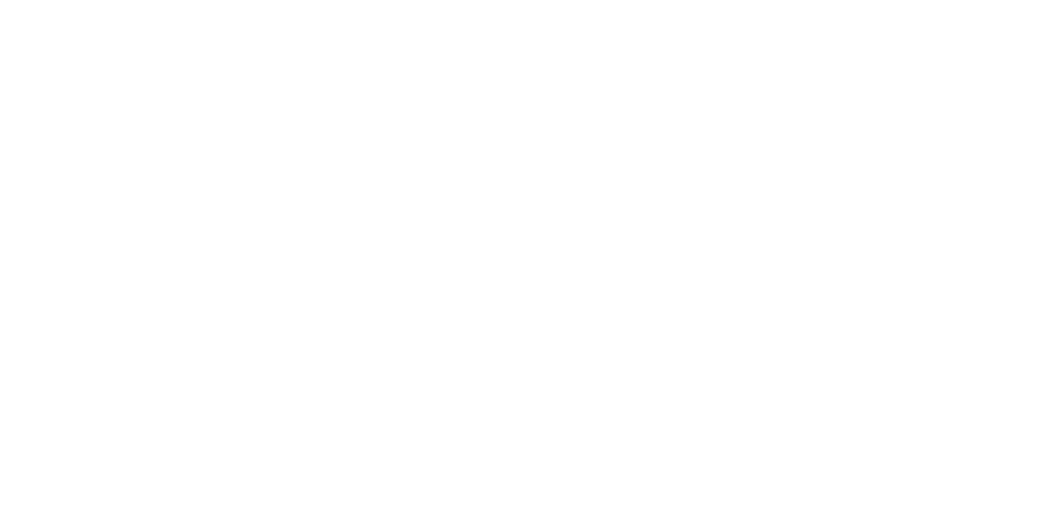


في المقال السابق تحدثنا عن الـData Replication ماهي، فائدتها، ولماذا نحتاج لعمل Replicate للبيانات، وتحدثنا عن أول نوع منها وهو الـ Single Leader، وهذا المقال معتمد عليه فلابد من قراءة وفهم المقال السابق.
تحدثنا عن نهج الـLeader-Based Replication لتحقيق الـhigh availability، وبمراجعة مميزات وعيوب الـsync توصلنا إلى أنه الاعتماد عليها بشكل كلي ليس فعال؛ لأنه يجب على الـFollower Replica عمل وارسال Acknowledgment لـ Leader Replica فإذا حدثت مشكلة تسببت في عدم وصول الـ Ack، ستقوم الـ Leader Replica بإيقاف جميع الـ writes حتى تعمل الـ Follower Replica بشكل طبيعي وذلك يسبب عائق في تحقيق معدل عال من الـavailability كما يبين الرسم هنا.
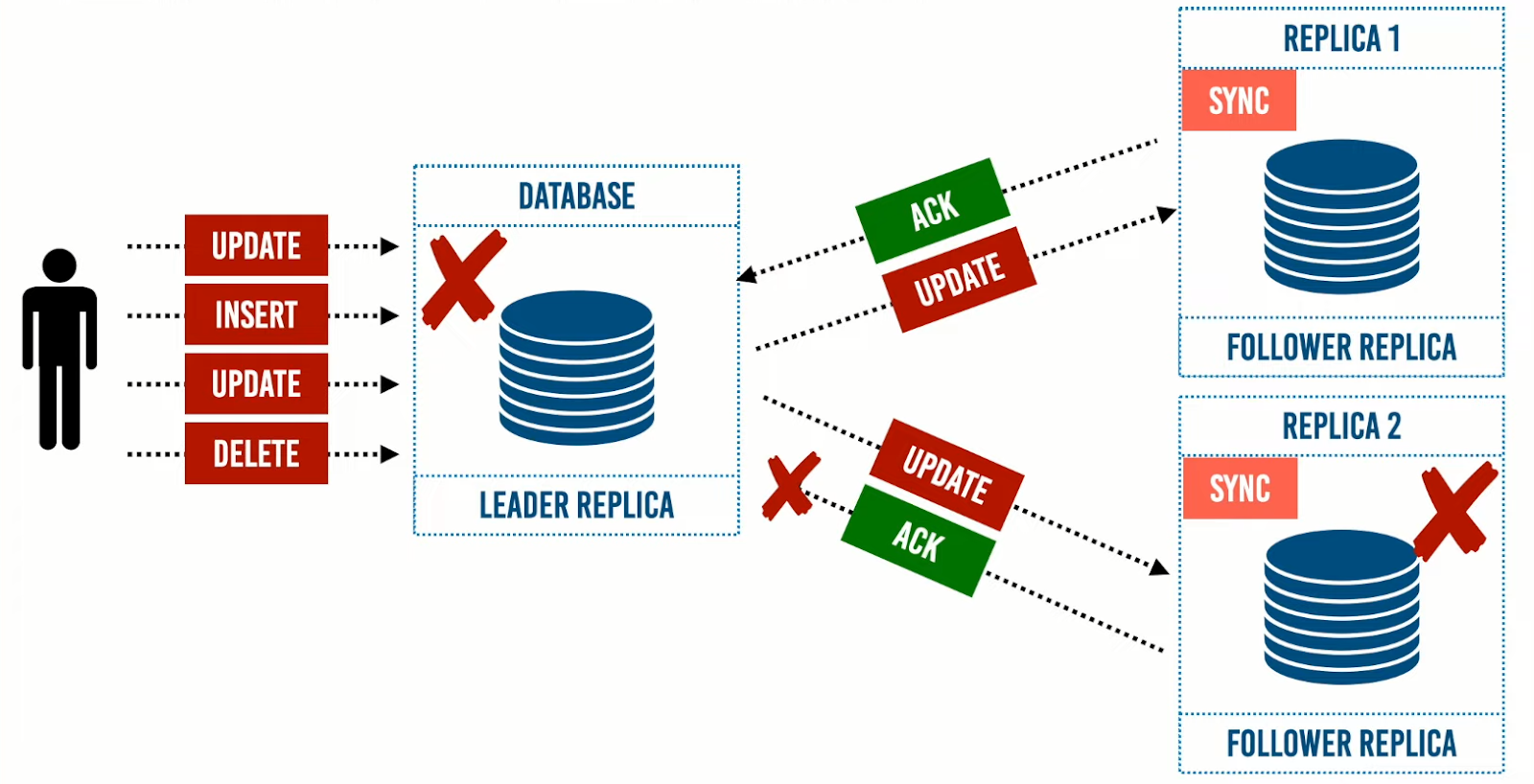
من ذلك استنتجنا أن طريقة الـAsync هي الطريقة الاكثر فاعلية والاكثر عملية: حيث تساعدنا على جعل الـLeader Replica تستقبل الـwrites فقط، وتوزع الأحمال الخاصة بالـreads علي الـFollower Replicas.
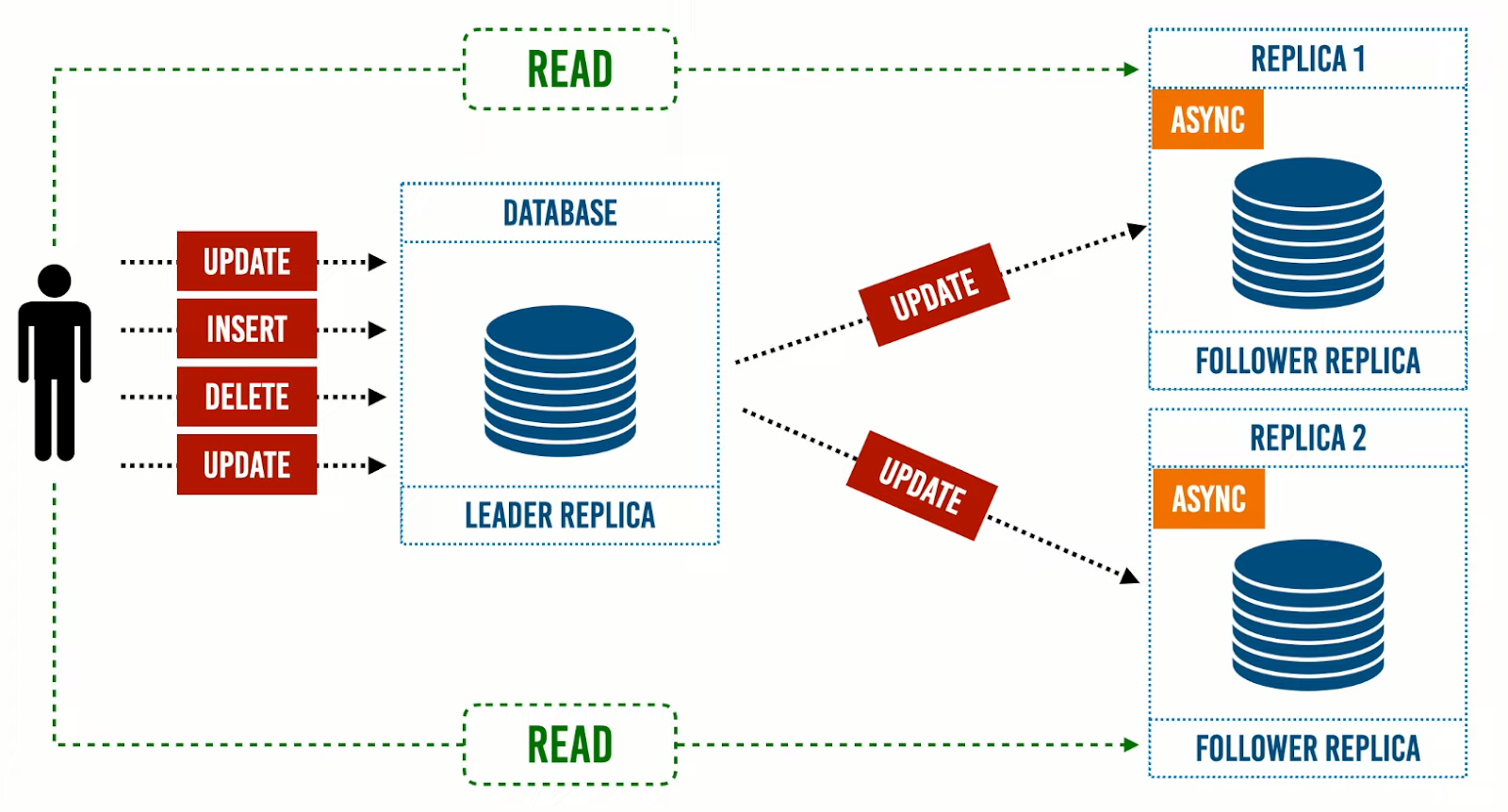
وعند زيادة أحمال الRead، سيتم اضافة followers، وتسمى هذه الـArchitecture بـRead-Scaling Architecture، وهذا النهج شائع لمعظم التطبيقات وخاصةً الـWeb applications.
لكن كما ذكرنا في المقال السابق، أن مشكلة استخدام طريقة الـ Async: أن الـLeader Replica لا تنتظر اي Ack من الـFollower Replica؛ مما يعني أنه اذا تم إرسال read request الى الـLeader و الـFollower في الوقت ذاته سيؤدي إلى نتائج مختلفة؛ لإحتواء الـ Follower علي بيانات منتهية الصلاحية، وذلك بسبب عدم وصول التعديلات. ذلك يؤدي بالنظام إلى حالة من التناقض -inconsistency-، والذي يحدث بشكل مؤقت ويسمى بالـ Eventual Consistency.
ما هو الـ Eventual Consistency؟
إيقاف عمليات الـwrites على الـLeader Replica، يؤدي بنا بعد وقت ما إلى مرحلة يصبح النظام فيها consistent؛ يعني ذلك أن استمرار عملية الـwrite لا تضمن لنا معرفة، بعد كم من الوقت سنصل إلى حالة الـconsistency، وهل سنصل لها أم لا.
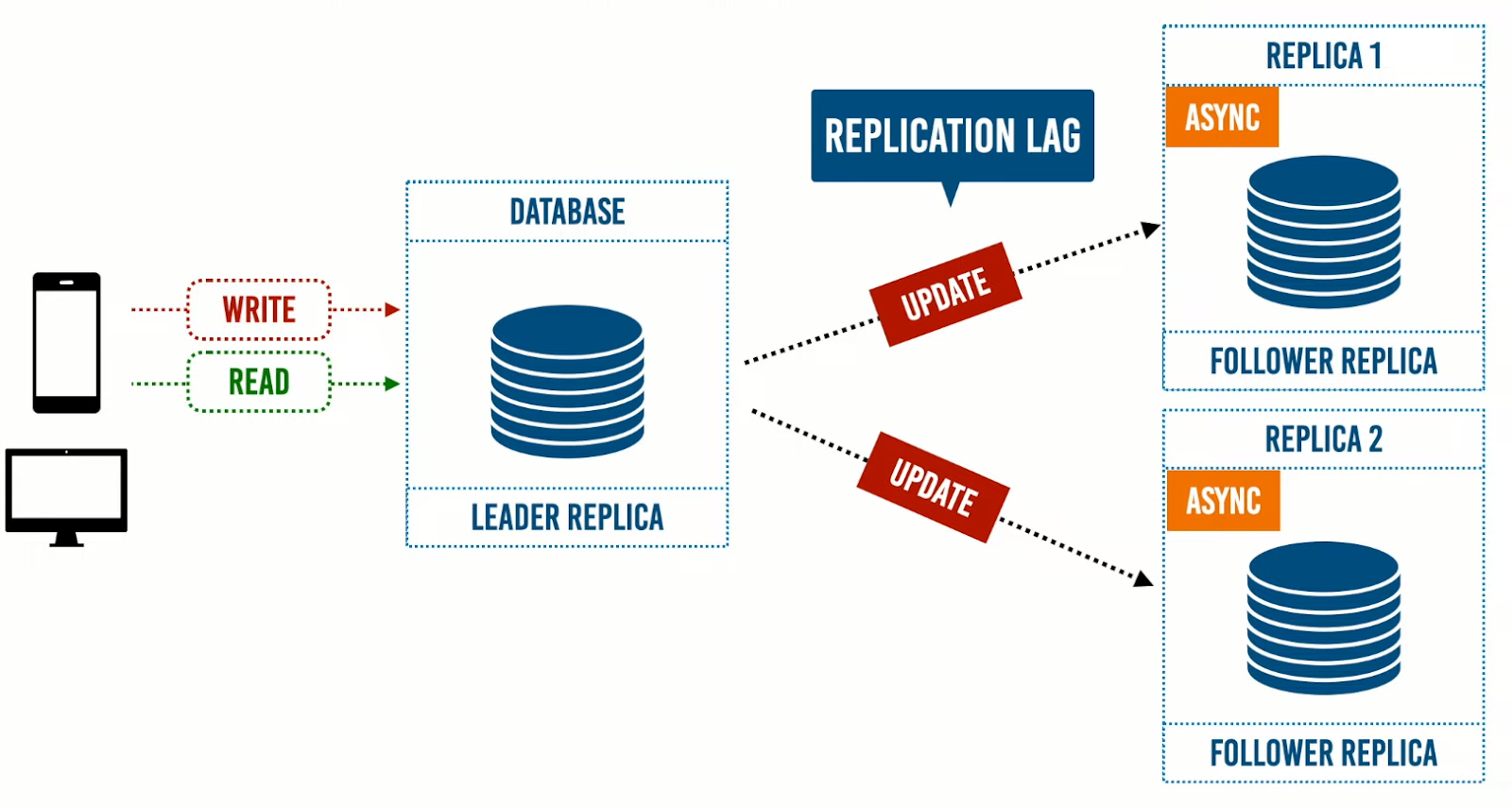
بالرجوع إلى حالة الـSingle Leader، إذا تم ارسال تعديلات الى الـLeader Replica، ثم يتم عمل commit إلى هذه التعديلات، ويتم إبلاغ المستخدم بأن هذه التعديلات تمت علي الـdata، ثم تقوم الـLeader Replica بإرسال هذه التعديلات إلى الـFollower Replicas.
خلال ذلك الوقت -الذي يتم أرسال فيه التعديلات الى الـFollower Replicas ويتم عمل commit لهذه التعديلات في الـ Followers- ننتظر -مما يعني أن النظام يصبح في حالة inconsistent- لحين عمل commit للتعديلات عند الـ Follower Replicas، ووقت الانتظار حتى تصبح الـ Follower Replicas في حالة consistent يسمي Replication Lag وهو الوقت الذي يحتاجه النظام بدًأ من ارسال المستخدم التعديلات لحين الوصول لحالة الـconsistent بمعنى أن كل من الـLeader و الـFollowers يحتويان على نفس الـ data.
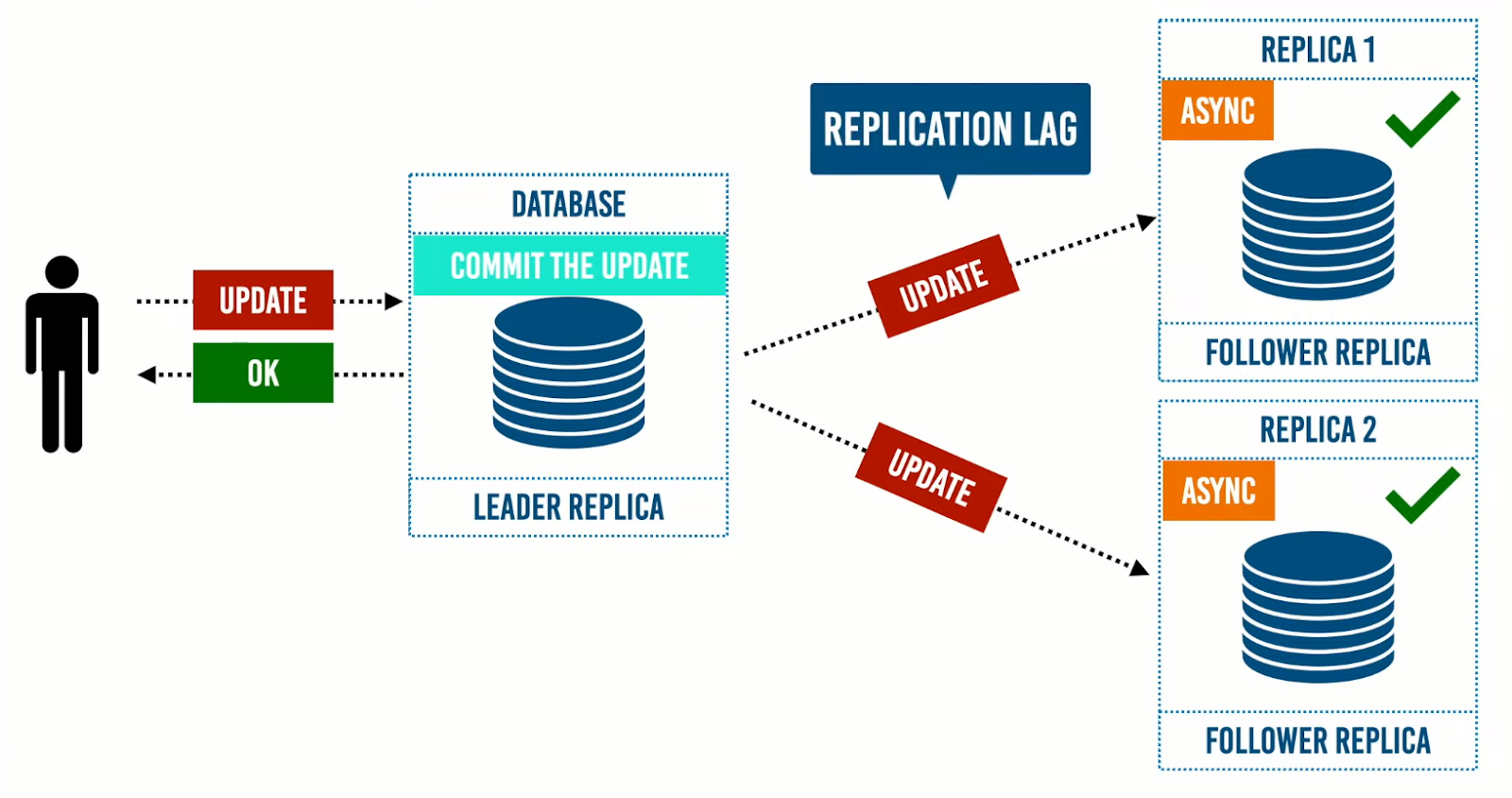
هناك بعض المشاكل يظهر فيها الـ Replication Lag والهدف هنا هو إخفاء تلك المشاكل عن المستخدم، حتى يصبح النظام consistent.
كيف تتعامل مع هذه المشكلات ؟
Reading your own writes
وهي قراءة المستخدم للبيانات التي أدخلها الآن.
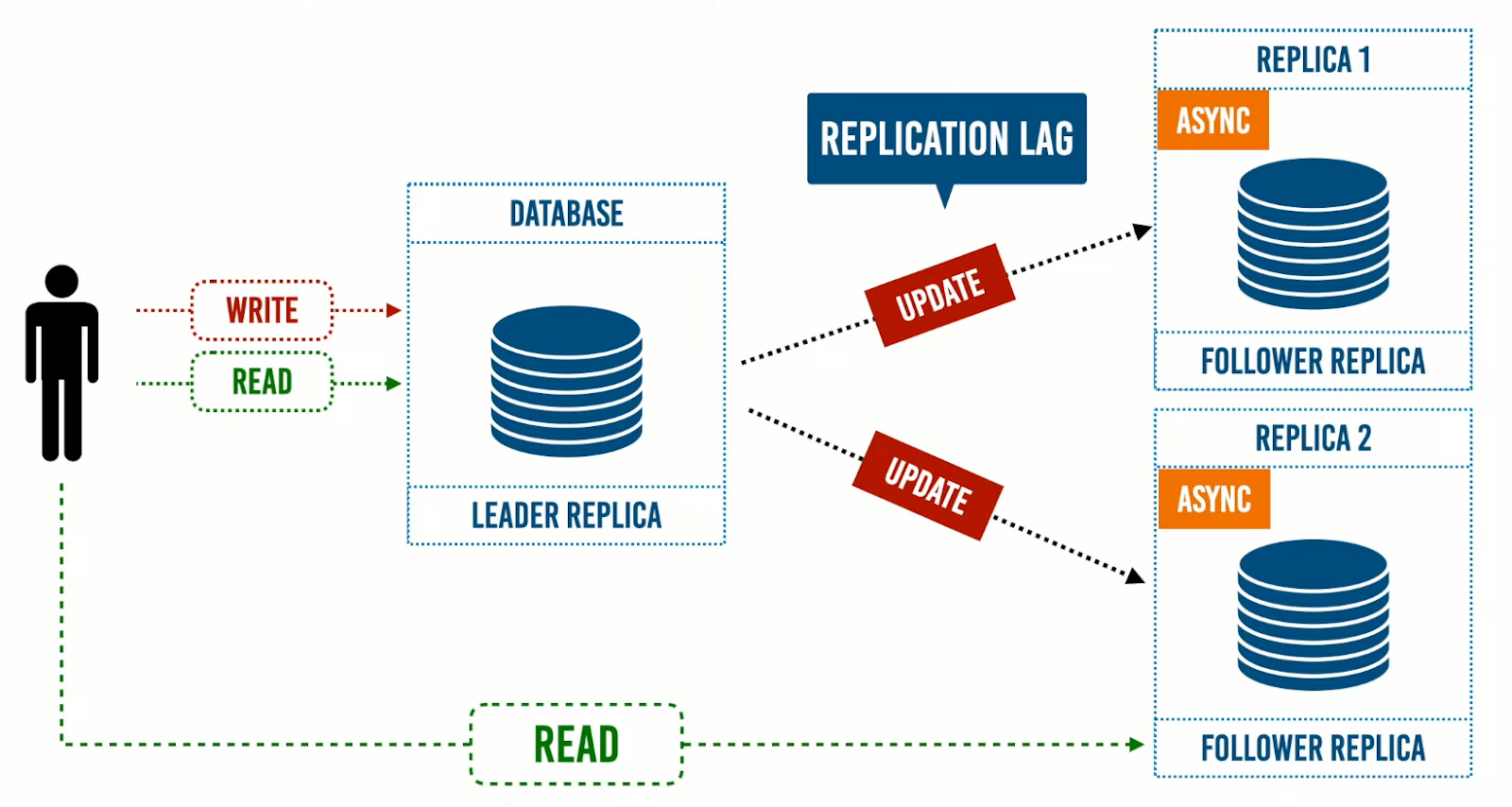
في حالة إستخدام نهج الـSingle leader، تتم كتابة البيانات وقراءتها في ومن الـLeader Replica. بهذة الطريقة نجعل المستخدم الذي أدخل البيانات هو المستخدم الوحيد القادر على قراءتها من الـLeader Replica، وباقي المستخدمين يمكنهم قراءة البيانات ولكن من الـFollower Replicas؛ لحين وصول النظام لحالة الـConsistency.
إذا كان النظام يشهد عمليات write كثيرة، فهذا الحل ليس مفيدًا؛ لأن الحمل الناتج من عمليات الـRead ستمثل حملًا على الـLeader Replica وهذا ضد هدف تحقيق معدل عال من الـavailability.
ولكن هناك حل يقلل الـ read load علي الـ Leader ولكن من الـ client side، وهو قيام المستخدم بحفظ وقت آخر تحديث تم عمله افتراضا اننا عرفنا الـ Replication lag يتم في وقت معين وليكن اعلي وقت ممكن يصل إليه هو 2 دقيقة فمن الممكن جعل المستخدم أن يقرأ البيانات من الـ Leader إذا كان الوقت قريب جدا من وقت آخر تحديث وإذا كان الوقت بعيد يقرأ من أي Follower Replica.
ولكن إذا كان هناك desktop app للنظام فيكون وقت آخر تحديث غير مخزن عليه، فيتم قراءة البيانات من Follower Replica، وهذا يتم بعمل write request عن طريق الهاتف وفي خلال وقت قليل جدا يتم عمل read request من الـ desktop app وفي هذا الوقت سوف يتم ظهور المشكلة وهي ان النظام في حالة inconsistent.
ولكن الهدف من هذه المشكلات والحلول هو جعل المستخدم قادر على قراءة البيانات التي أدخلها بشكل طبيعي.
هل في احد المرات قمت بفتح تطبيق فيسبوك واحد الاصدقاء قام بعمل تعليق على منشور وانت رأيته وثم قمت بعمل refresh او قمت باعادة فتح المنشور مرة اخرى وجدت ان هذا التعليق غير موجود؟
تسمى هذه الظاهرة بـ moving backward in time
وهنا المستخدم يرى شكل الـ data القديمة في حين أنه شاهد الـ data الجديدة فيما قبل وحل هذه المشكلة يسمي Monotonic Reads Consistency
وهي قراءة المستخدم لكل الـ requests الخاصة به من replica واحدة بمعنى ان جميع الـ requests الخاصة بهذا المستخدم سوف ترسل لنفس الـ replica في كل مرة ويتم ذلك عن طريق hashing technique ويعتمد على الـ user id بحيث في كل مرة يرجع نفس الـ value وهي الـ replica id التي يتم القراءة منها ومشكلة هذه الطريقة إذا حدثت مشكلة في هذه الـ replica ستحتاج إلى عمل reroute لهذا المستخدم لـ replica أخرى.
الـ Monotonic Reads Consistency هو حل more consistent عن الـ Eventual Consistency ولكن لا يحقق الـ strong consistency.
وهو more consistent لأنه يجعل المستخدم غير قادر علي معرفة أن هناك مشكلة وهذا هو الهدف الأساسي الذي نتحدث عنه.
وهو ليس strong consistency لأن تحقيق الـ strong consistency تعني أن جميع الـ Followers Replicas هتكون consistent ويكون لديها نفس البيانات الموجود علي الـ Leader وهذا لا يحدث في حالة الـ Monotonic Reads Consistency وهو جعل المستخدم قادر على قراءة البيانات الخاصة به ولكن هذا لا يعني أنه إذا قام بقراءة هذه البيانات من replica أخرى سيحصل على نفس البيانات ويجدها.
وهناك حالة أخرى هل قمت بالدخول الي منشور على تطبيق فيسبوك ووجدت في التعليقات اجابة على سؤال غير موجود وبعد فترة ظهر السؤال بمعني ان الاجابة ظهرت اولا ثم السؤال؟
هنا يوجد مشكلة في الترتيب الزمني للـ data وهذه المشكلة تظهر عندما تكون الـ data في شكل sharding او مقسمة علي اكثر من partition.
يتم حل هذه المشكلة بطريقة تسمى Consistent Prefix Reads
وهي جعل الـ data متعلقة ببعضها البعض وموجودة في نفس الـ partition.
وفكرة هذه الطريقة إذا تم حدوث writes كثيرة علي النظام لا بد من ان تتم بترتيب حدوثها ووقت قرائتها تظهر بنفس الترتيب.
وهذه المشكلة والمشاكل المتعلقة بالـ sharding نادراً ما تقابلها لانها تحدث في شركات ذات حجم كبير جدا وتمتلك أحجام هائلة من البيانات.
اذا كنت تعمل مع Eventual Consistency system لا بد من التفكير في الـ Replication Lag.
هل إذا زاد هذا الوقت في النظام سيسبب مشكلة ؟
اذا كانت الاجابة لا فتعامل بشكل طبيعي مع المشكلة وبعد هذا الوقت ستكون قاعدة البيانات Consistent، ولكن إذا زاد الوقت سوف يسبب مشكلة فلابد من ايجاد حل.
وهذه المشكلات لا تواجهها إذا كنت تعمل على قاعدة بيانات واحدة ولا يوجد replication.
وحتى إذا كنت تعمل على نظام صغير غالبا سوف تحتاج لعمل replication إلى الـ data لجعل النظام متاح إذا حدثت مشكلة في أي machine.
















Discussion