How Slack Handles Billions of Tasks in Milliseconds
How Slack Handles Billions of Tasks in Milliseconds
جزء مهم من البنية التحتية لـ Slack هو الـ Job Queue System واللي قادر إنه يعالج 1.4 مليار Job ، بمعدل يوصل لـ 33,000 في الثانية وده رقم ضخم جدًا فخلونا نشوف ازاي Slack قدرت تحقق ده.
لو جينا نبص على Slack هنلاقيها بتستخدم job queue system علشان تنفّذ الـ business logic اللي بياخد وقت كبير ومينفعش يتنفذ جوه الـ web request الطبيعي. والسيستم ده جزء أساسي في البنية التحتية بتاعت Slack، وكمان بيتم استعماله في كل message بتتبعت، وكل push notification، وكل URL unfurl، والتذكيرات، وحساب الفواتير وغيرها كتير من المميزات اللي Slack بتقدمها.
في أغلب الأيام اللي بيكون عليها ضغط كبير، السيستم بيعالج أكتر من 1.4 مليار job، بمعدل بيوصل لـ 33,000 job في الثانية. وده رقم ضخم جدًا ومع ذلك تنفيذ الـ jobs بياخد من ميلي ثانية لحد دقايق أحيانًا.
الـ job queue القديم اللي كانوا بيستخدموه من أول ما Slack بدأت، قدر يمشي معاهم الرحلة دي وهم بيكبروا. وكل ما كانوا بيقابلوا مشاكل في الـ CPU أو الـ memory أو الـ Network، كانوا بيعملوا scaling، لكن الـ Architecture الأساسي للـ System فضل زي ما هو تقريبًا.
من حوالي سنة، حصل عندهم production outage كبيرة بسبب الـ job queue. كان فيه مشكلة في الـ database layer، خلت تنفيذ الـ jobs يبقى بطيء جدًا، وده خلى Redis يوصل لأقصى سعة من الـ memory الممكنة. ولما مابقاش فيه memory فاضية، مقدروش يحطوا jobs جديدة، وبالتالي كل حاجة كانت معتمدة على الـ job queue وقعت.
اللي زوّد الطين بلة إن حتى عملية الـ dequeue كانت محتاجة memory، فكده الموضوع كان بايظ من الناحيتين لا عارفين يزودوا jobs جديدة ولا حتى يعملوا dequeue للـ jobs الموجودة بسبب ان مفيش free memory ، فحتى بعد ما مشكلة الـ database اتحلت، الـ queue فضلت واقفة، واحتاجت تدخل يدوي عشان تشتغل تاني.
الـ incident دي خلتهم يعيدوا تقييم الـ job queue system كله، وبدأوا يخططوا لتغيير كبير في التصميم، لكن من غير ما يوقفوا أي service، أو يعملوا migration ضخم، وكمان يوفروا سبيل لأي تحسينات مستقبلية ممكن يضيفوها بعدين.
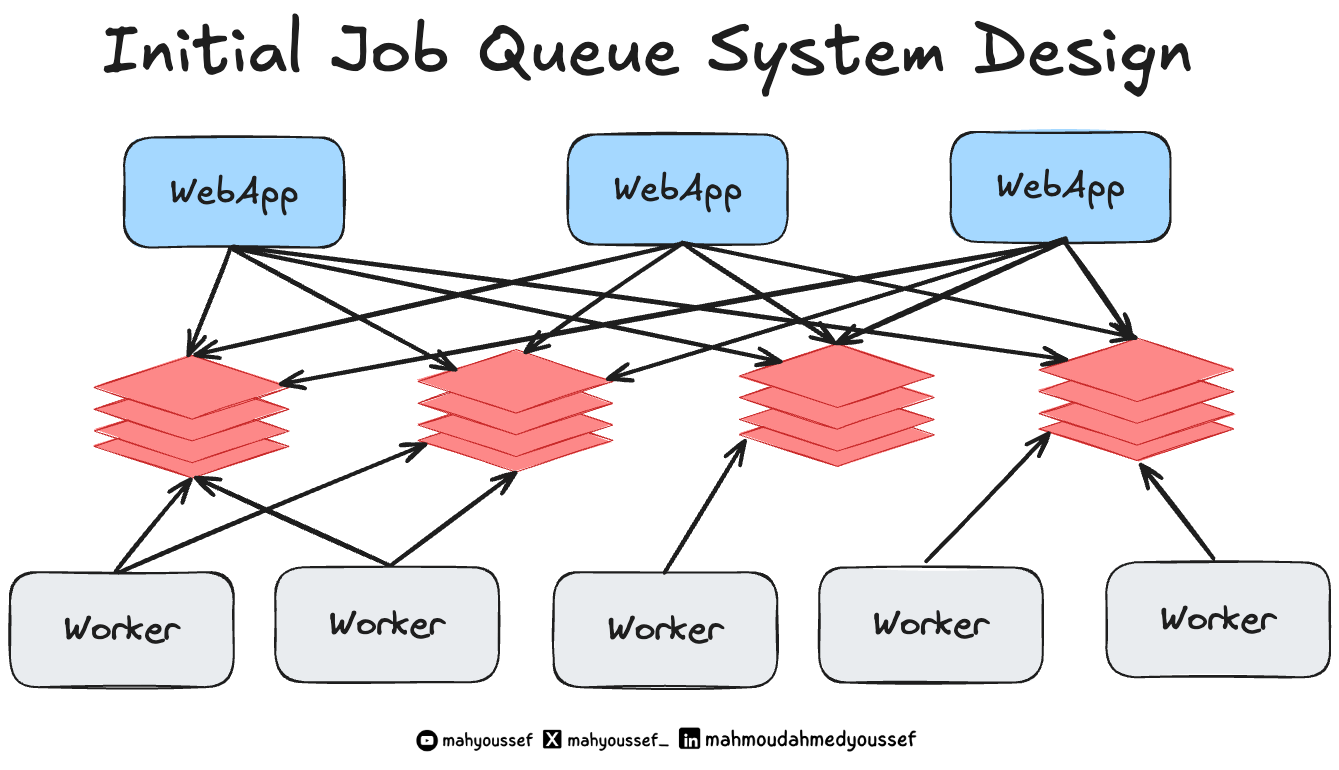
Slack's Initial Job Queue System Design
الـ system design القديم بتاع الـ job queue عند Slack كان ممكن ترسمه بالشكل ده، وغالبًا هيكون مألوف لأي حد اشتغل أو استخدم Redis task queue قبل كده.
Slack's Initial Job Queue System Design
Job's Lifecycle
لما الـ web app بيعمل enqueue لـ job: أول خطوة بتكون إنه ينشئ identifier (وده unique identifier) مبني على نوع الـ job والـ arguments اللي جاية معاها.
الـ enqueue handler بيختار واحد من Redis hosts: والاختيار بيتم بناءً على استعمال hash من الـ identifier ده وكمان الـ logical queue اللي تخص الـ job دي ، يعني كل job بتروح على Redis معين حسب نوعها ومحتواها.
في Redis، بيستخدموا data structures علشان يعملوا deduplication وبيكون limited شوية: فلو فيه job بنفس الـ ID أصلًا موجودة جوه الـ queue الطلب الجديد بيتلغى. ولو مفيش واحدة زيها الـ job بتضاف للـ queue.
الـ Workers دايمًا بتعمل polling على Redis clusters: في الـ background، بيكون فيه pools من الـ (worker machines) متابعة وبتراقب الـ queues، ومستنية يظهر أي job جديدة عشان تشتغل عليها. أول ما واحدة من الـ workers تلاقي job في queue من اللي هي بتراقبهم:
بتنقلها من pending queue لـ in-flight list (يعني الشغل اللي شغال عليه دلوقتي).
بتبدأ تشغّل (asynchronous task) علشان تنفّذ الـ job دي.
بعد ما الـ task تخلص: الـ worker بيشيل الـ job من قائمة in-flight jobs ولو الـ job فشلت وحصلها (failure) بتتحط في queue خاص بإعادة المحاولة (retry queue). وبيتم إعادة المحاولة عدد معين من المرات، لحد ما يا إما تنجح ، يا إما تتحط في قائمة تانية اسمها permanently failed jobs (اللي بيتم مراجعتها يدويًا علشان يشوفوا هي فشلت ليه، ويحلوها لو محتاجة تدخل بشري).
Architectural Challenges
بعد ما عملوا post-mortem للـ outage اللي حصل، Slack وصلت لاستنتاج واضح: "الـ scaling بالنظام الحالي مش هينفع، ولازم نشتغل على تغييرات جذرية أكتر."
طب إيه هي المشاكل والقيود اللي اكتشفوها؟
مبدئيًا كده Redis كان مفيهوش مساحة كفاية، خصوصًا من ناحية الـ memory: فلو عدد الـ jobs اللي بتتعمل enqueue بقى أسرع من الـ dequeue لفترة طويلة، السيستم بيستهلك الذاكرة كلها. ولما الـ memory تخلص، حتى dequeueing ميبقاش ممكن (لأنه هو كمان بيحتاج memory علشان يحرك الـ job لقايمة الـ processing).
الـ Redis connections كانت عاملة complete bipartite graph: كل client (أي system بيعمل enqueue) لازم يكون متصل بـ كل Redis instance. وده معناه إن كل client لازم يعرف كويس كل تفاصيل Redis nodes، ويكون عنده config مظبوط ومحدّث دايمًا.
الـ Job workers ماكانوش يقدروا يعملوا scaling لوحدهم من غير Redis: كل ما بنزود عدد الـ workers بنحط load أكتر على Redis.
الاختيارات اللي كانوا عاملينها قبل كده في الـ Redis data structures كانت مكلفة: علشان نعمل dequeue من الـ queue، كان لازم نعمل عمليات تتناسب مع الـ queue length نفسه. أو بمعنى أبسط (كل ما الـ queue يطول، كل ما بيبقى أصعب إننا نفضيه).وده كان مخلي الأداء يبقى أسوأ مع الوقت.
الـ semantics والـ QoS (quality-of-service) guarantees اللي بتتقدم للـ app والـ platform engineers كانت مش واضحة: فالـ async job processing كان مفروض يكون حاجة أساسية في الـ architecture ، لكن في الواقع، المهندسين كانوا بيترددوا يستخدموه علشان سلوكه مكنش متوقع. فأي تغيير حتى ولو بسيط (زي موضوع deduplication المحدود) كان high-risk جدًا، لإن فيه jobs كتير بتعتمد عليه علشان تشتغل صح.
طب يعملوا إيه؟ إيه الحل؟
كل مشكلة من دول كانت ممكن تروح في كذا اتجاه من الحلول — من مجرد تحسينات بسيطة، لحد عملية الـ Re-Write للسيستم من الصفر. لكن Slack قرروا يركزوا على 3 نقاط رئيسية ممكن تحل المشاكل اللي ليها أولوية:
استبدال Redis بـ durable storage (زي Kafka): علشان يبقى فيه buffer يتحمّل ضغط الـ memory، وميفقدش الـ jobs لو حصل أي overload. وده لإن Kafka يقدر يحتفظ بالبيانات دي بأمان على الـ disk، بدل ما كل حاجة تبقى in-memory.
بناء scheduler جديد خاص بالـ jobs: ده هيساعدهم يقدّموا guarantees أفضل من ناحية QoS. وكمان يقردوا يوفّرا features بأريحية زي مثلًا الـ rate-limiting، والـ prioritization في تنفيذ jobs.
فصل تنفيذ الـ jobs عن Redis تمامًا: كده أصبح بإمكانهم إنهم يعملوا scale للـ job execution من غير ما يضطروا يتعاملوا مع Redis نفسه.
Incremental Change or Full Rewrite
فريق Slack كانوا عارفين إن تنفيذ كل التحسينات اللي خططوا ليها هيحتاج تغييرات كبيرة في الـ web app وفي الـjob queue workers. علشان كده الفريق قرر يركز على أهم المشاكل اللي عنده، وياخد خبرة عملية مع أي جزء جديد من النظام بدل ما يحاول يعمل كل حاجة مرة واحدة.