منصة YouTube دلوقتي بتخدم أكتر من 2 مليار مستخدم، وعدد المستخدمين الضخم ده بيتعامل مع مئات الساعات من الفيديوهات اللي بتترفع كل دقيقة. واللي ممكن يكون مفاجئ للبعض إنهم معتمدين بشكل أساسي على MySQL، قاعدة البيانات اللي أغلبنا بنستخدمها في مشاريع كتيرة.
منصة YouTube دلوقتي بتخدم أكتر من 2 مليار مستخدم، وعدد المستخدمين الضخم ده بيتعامل مع مئات الساعات من الفيديوهات اللي بتترفع كل دقيقة. واللي ممكن يكون مفاجئ للبعض إنهم معتمدين بشكل أساسي على MySQL، قاعدة البيانات اللي أغلبنا بنستخدمها في مشاريع كتيرة. لكن السر مش في MySQL نفسها، بل في الطريقة اللي قدروا يستخدموها بيها لتوسيعها وتحسينها.
How YouTube Used MySQL
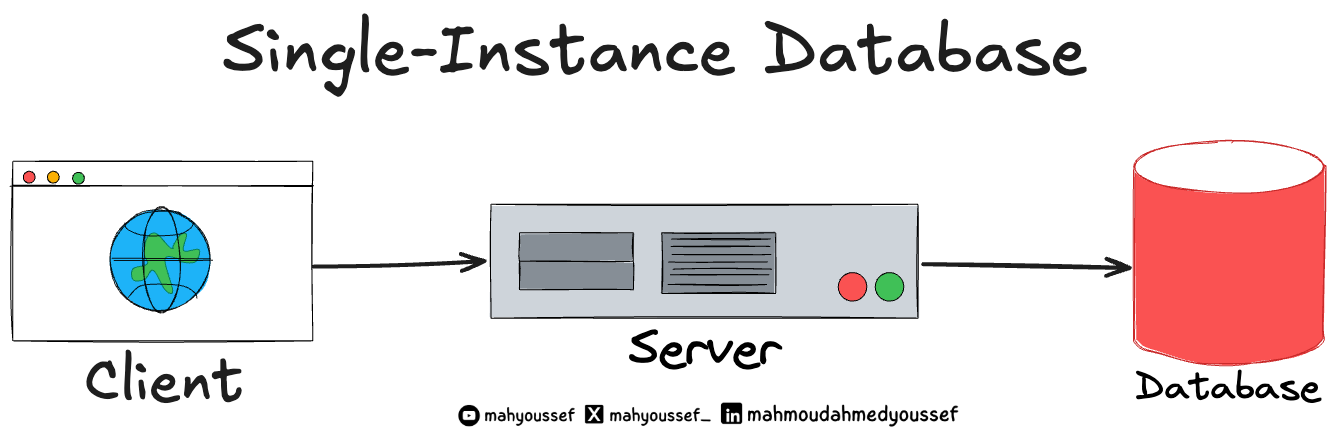
في البداية، YouTube كانت بتستخدم MySQL كقاعدة بيانات واحدة بتخزن فيها كل حاجة زيها زي أي Application ، فكانت بتخزن فيها بيانات المستخدمين، والفيديوهات، والتعليقات، وكل حاجة تانية. لكن مع الزيادة المستمرة والضخمة لعدد المستخدمين، النظام بدأ ينهار.
وده غالبًا الحال مع أغلب الـ Use Cases اللي هنشوفها مع أي Application ، إننا بنبدأ بقاعدة بيانات واحدة وبعدين بنضطر إننا نـ Scale مع الوقت فبتبدأ المشاكل هنا تبان ونبدأ نفكر ازاي نحلها.
How YouTube Used MySQL
طب ايه هي المشاكل اللي ممكن تنتج من وجود حمل عالي على قاعدة البيانات ؟
الـ Queries هتكون بطيئة: مع ازدياد حجم البيانات اللي بتتخزن مع الوقت هيكون من الصعب جدًا إننا نـ Retrieve البيانات دي بسهولة وبسرعة زي الأول لإن البيانات بقت ضخمة وكبيرة ومهما عملنا من Optimization هنوصل للـ Limitation مع الحمل الكبير.
صعوبة الـ Backups: وده لإننا محتاجين يكون عندنا Downtime أثناء عملية الـ Backups والـ Updates اللي عاوزينها على قاعدة البيانات دي كذلك هتوقفلنا التعامل مع قاعدة البيانات لمدة من الزمن.
الـ Data Loss: لو حصل أي مشكلة في MySQL فاحنا عرضة لخسارة بعض البيانات وده لإننا مش قادرين نضمن الـ Durability للبيانات دي بـ Single Instance.
الـ Latency هتكون عالية: خصوصًا لو كان المستعملين متوزعين جغرافيًا بعيد عن بعض ، فلو كان التطبيق بيستهدف كل الناس في العالم ، فمع قاعدة بيانات واحدة هيكون من الصعب جدًا خدمة العدد ده من الناس والموضوع كان هيكون فيه Limitations كبيرة.
المشاكل اللي تناولناها دي أهم المشاكل اللي بتواجه أي قاعدة بيانات واحدة مع زيادة حمل كبير عليها.
فالنهاية YouTube كان لازم يلاقوا حل يوسعوا بيه النظام بدون ما يغيروا MySQL نفسها.
Replication is The Secret
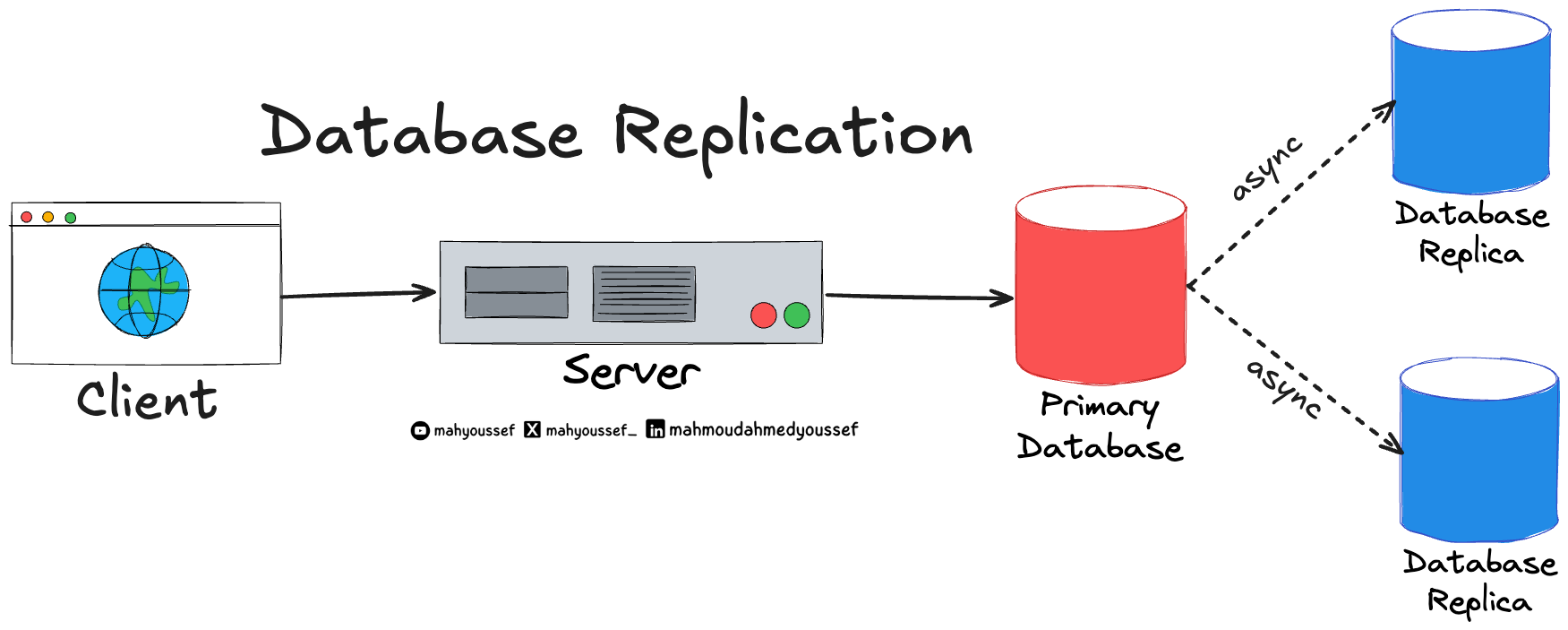
أول خطوة YouTube خدتها هي كانت استخدام MySQL Replication، يعني يعملوا نسخ من قاعدة البيانات الرئيسية (Primary) لنسخ تانية (Replicas) للقراءة فقط.
الـ Read Queries بتروح للـ Replicas.
الـ Write Queries بتروح للـ Primary.
بالشكل ده احنا نقدر يبقى عندنا MySQL Cluster بيتكون من Primary Node وأكتر من Replica Node ونقدر نـ Handle الحمل الكبير بدلًا ماكان على قاعدة بيانات واحدة إنه يتم توزيعه على باقي الـ Replica Nodes.
الـ Replication عادة بيتم بأكتر من طريقة ولكن أشهرهم هو الـ Asynchronous Replication واللي فيه الـ Replicas بتكون متزامنة أو Synchronized مع الـ Primary Database فبيتم نسخ أي تغييرات بتطرأ على الـ Primary Database مع الـ Replica بشكل Asynchronous ومع الوقت بنضمن إن الـ Replica Nodes كلهم هيكون عندهم البيانات نفسها اللي عند الـ Primary.
Database Replication
لكن المشكلة إن الـ Replication في MySQL بيشتغل (Single-threaded)، فالـ Replicas كانت بتتأخر في تحديث البيانات، وده سبب مشاكل في التزامن.
وهي دي ضريبة الـ Asynchronous Replication إن على مالـ Replica يوصلها التغييرات اللي طرأت على الـ Primary Database هيكون عندي Stale Data والبيانات مش هتكون متزامنة أو Consistent مع بعض.
Consistency and Availability Trade-Offs
من فهمنا للـ CAP Theorem إن لازم يتوفر معايا ضمانين 2 بس ونضحي بالتالت ، فـ YouTube كانت شايفة إنها محتاجة في حالة الـ Network Partition إنها تضحي بالـ Strict Consistency في سبيل تحقيق الـ Availability ، ومش مشكلة إن يكون فيه Eventual Consistency والبيانات مع الوقت تبقى Consistent.
ولكن في نفس الوقت هم كان عندهم Use-Cases إن عمليات القراءة اللي هتتم مش محتاجة يكون فيها Stale ولازم تكون Fresh. فعشان يعالجوا المشكلة دي قرروا يوازنوا ويمسكوا العصاية من النص. طب ازاي ؟
عمليات القراءة من الـ Replica: فيه بعض الـ Use-Cases اللي مكنوش محتاجين فيها البيانات تكون Fresh والموضوع ده مش مهم أوي زي مثلًا إنهم يظهروا الـ View Counts الرقم ده مش محتاجين انه يكون Accurate و Consistent في كل ثانية. فلو فيه تأخير بسيط ده مش هيضر من الـ User Experience في إن الـ Count يكون دقيق جدًا لحظة بلحظة.
عمليات القراءة من الـ Primary: على النقيض فيه بعض الـ Use-Cases التانية اللي قراءة Fresh Data هو موضوع حتمي ومهم زي مثلًا لما المستخدم يغير الاعدادات بتاعته أو بياناته ويجي يعمل Refresh عشان يشوفها ، فمش منطقي ان بعد مالمستخدم يغير بياناته ويعمل Refresh يلاقي بياناته القديمة لسه موجودة. وعشان كده في الحالات دي ، عمليات القراءة بتتم على الـ Primary Database عشان هي اللي بيكون فيها الـ Fresh Data.
In-Memory Bound Replication - Introducing Cache
زي ما شوفنا مشكلة MySQL فالـ Replication إنه عملية Single Threaded ، ومع تزايد عمليات الكتابة اللي بتتم على الـ Primary Database أصبح من الصعب جدًا إن الـ Replication يتم بشكل سريع وأصبح فيه Lag كبير بين الـ Replicas والـ Primary.