Scaling PostgreSQL to Power 800 million ChatGPT Users
Scaling PostgreSQL to Power 800 million ChatGPT Users
شركة OpenAI بقالهم سنين معتمدين على PostgreSQL كواحد من أهم الـ Data Systems اللي شغالة في الخلفية وبتشغّل منتجات أساسية جدًا زي ChatGPT و OpenAI API. ومع النمو السريع جدًا في عدد المستخدمين، الضغط على قواعد البيانات بيزداد بشكل Exponential.
شركة OpenAI بقالهم سنين معتمدين على PostgreSQL كواحد من أهم الـ Data Systems اللي شغالة في الخلفية وبتشغّل منتجات أساسية جدًا زي ChatGPT و OpenAI API. ومع النمو السريع جدًا في عدد المستخدمين، الضغط على قواعد البيانات بيزداد بشكل Exponential. وخلال السنة اللي فاتت بس، الحمل على PostgreSQL زاد أكتر من 10 أضعاف، ومازال بيزيد بسرعة.
وفي خلال رحلتهم وهم بيطوروا الـ production infrastructure علشان تستحمل النمو ده، اكتشفوا حاجة مهمة: وهي إن PostgreSQL يقدر يـ (scale) ويشيل workloads ضخمة جدًا من النوع الـ read-heavy أكتر بكتير ما ناس كتير كانت متخيلة.
النظام ده (اللي أصله اتعمل على إيد فريق علماء في University of California, Berkeley) مكنهم إنهم يخدموا traffic عالمي وضخم باستخدام single primary Azure PostgreSQL flexible server instance واحدة، ومعاها تقريبًا 50 read replicas متوزعين على أكتر من region حوالين العالم.
في رحلتنا انهاردة هنشوف مع بعض قصتهم وإزاي قدروا يعملوا scale لـ PostgreSQL في OpenAI عشان يخدم ملايين الـ queries في الثانية (QPS) لـ 800 مليون مستخدم، عن طريق optimizations دقيقة وهندسة قوية. وكمان هنشوف أهم الدروس اللي اللي نستفاد بيها في الرحلة دي.
Challenges in The Initial Design
بعد إطلاق ChatGPT، حجم الـ traffic زاد بشكل غير مسبوق. وعشان يواكبوا ده، اشتغلوا بسرعة على optimizations كبيرة على مستوى الـ application وعلى مستوى PostgreSQL نفسه، وكبروا حجم الـ instance (scale up)، وكمان زودوا عدد الـ read replicas (scale out).
الـ architecture دي قدرت انها تخدمهم كويس لفترة طويلة، ولسه مع التحسينات المستمرة بتديهم مساحة للنمو كويسة جدًا قدّام.
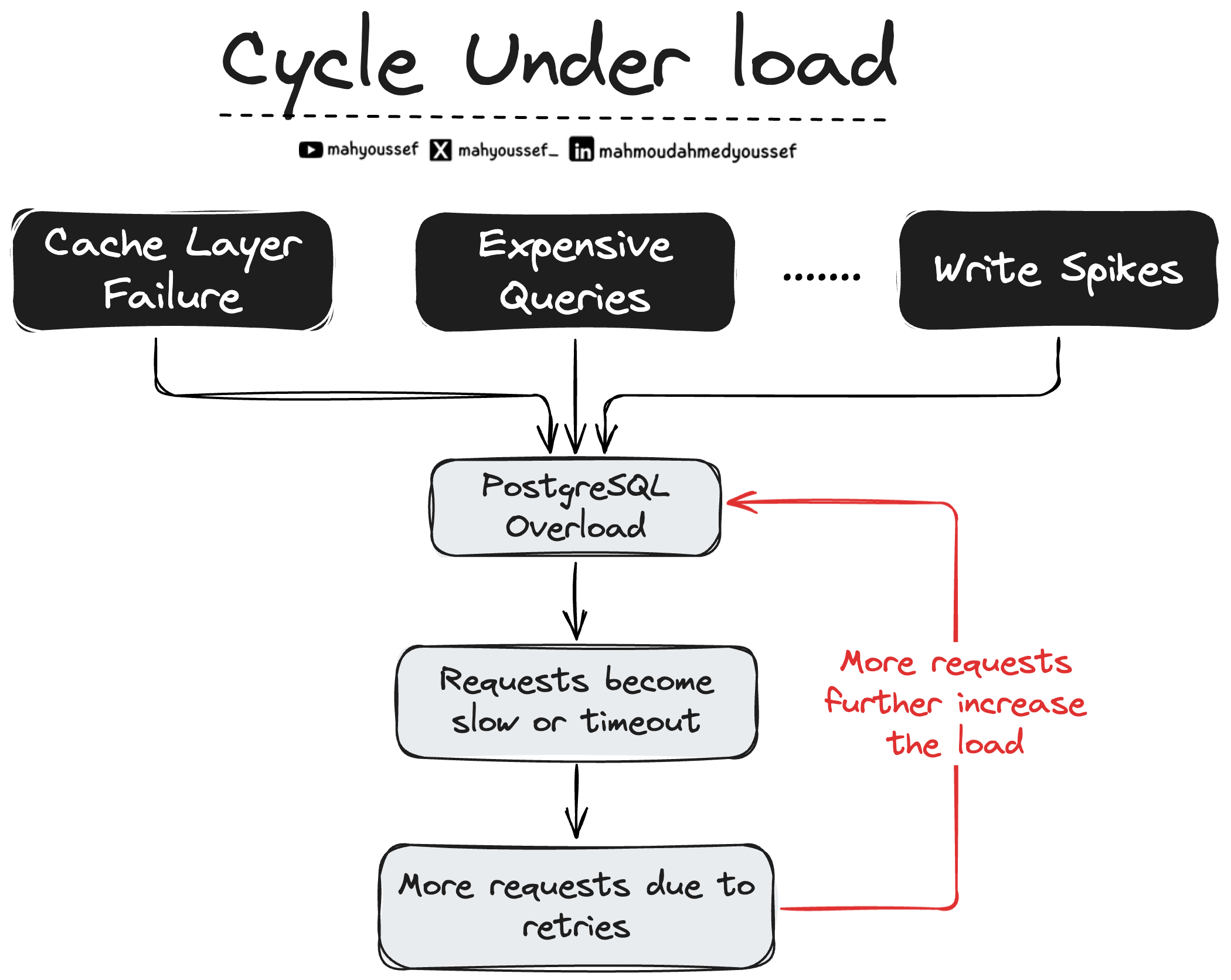
وقد ما الموضوع ممكن يبان غريب لكتير من الناس وإن single-primary architecture تقدر تشيل scale بحجم OpenAI، بس الحقيقة إن تطبيق الكلام ده عمليًا مش سهل. وفريق المهندسين في OpenAI شافوا مشاكل كتير و Incidents بسبب الـ overload في Postgres، وغالبًا السيناريو بيبقى شبه بعضه:
مشكلة في إن الـ upstream تعمل spike مفاجئ في load على الـ database
الـ cache layer تقع فيحصل cache misses على نطاق واسع وبالتالي الـ load يزيد على الـ database
الـ expensive multi-way joins تستهلك CPU
أو write storm بسبب feature جديدة نزلت
Challenges in The Initial Design - Cycle Under Load
ومع زيادة استهلاك الموارد، بنلاقي ان الـ latency بتعلى، الـ requests تبدأ في الـ timeout والـ retries تزود الحمل أكتر، وبعدين ندخل في cycle ممكن تبوظ ChatGPT والـ API بالكامل.
Challenges With Write-Heavy Traffic
زي ما قولنا إن PostgreSQL ممتاز جدًا في الـ read-heavy workloads، ولكن ده معناه إن لسه فيه تحديات في الـ write-heavy workload. والسبب الأساسي هنا هو الـ MVCC أو الـ (multi-version concurrency control).
في PostgreSQL، أي update بيحصل حتى لو على field واحد، بيعمل نسخة جديدة من الـ row كله. ومع ضغط writes عالي، ده بيعمل:
Write Amplification
في PostgreSQL، أي UPDATE—event لو على column واحد—ما بيعدّلوش الـ row في مكانه. بدل كده، النظام بيكتب نسخة جديدة كاملة من الـ row ويخلّي القديمة موجودة.
ده معناه إن: عملية الـ write من التطبيق بتتحول لعدة writes على مستوى الـ table، الـ indexes، والـ WAL فالـ write cost الفعلي أعلى بكتير من اللي ظاهر في الكود، وده اللي بنسميه write amplification.
Read Amplification
بسبب الـ MVCC، النسخ القديمة من الـ rows (dead tuples) بتفضل موجودة لحد ما تتشال.
لما query تعمل SELECT: بنلاقي إن PostgreSQL ممكن يمرّ على أكتر من version للـ row ويستبعد النسخ القديمة لحد ما يوصل للـ version الصح
فـ read واحدة منطقيًا، بتتحول لعمليات قراءة أكتر على مستوى الـ storage و CPU وده اسمه read amplification.
Table & Index Bloat
مع كثرة الـ updates: الـ dead tuples بتتراكم والـ indexes بتفضل شايلة references لبيانات اتحذفت والمساحة ما بترجعش بسهولة للـ OS
والنتيجة:
حجم الـ tables والـ indexes يكبر
الـ queries بتبقى أبطأ
والـ disk I/O بيزيد
Index Maintenance Overhead
كل INSERT أو UPDATE:
بيحتاج تحديث لكل index مرتبط بالـ row
ومع MVCC، الـ indexes نفسها بتدخل في دايرة versions قديمة وجديدة
ولو الـ table عليه أكتر من index:
فتكلفة الـ write بتزيد بشكل Linear مع عدد الـ indexes
والـ CPU والـ disk usage بيعلى
والـ autovacuum يبقى عليه شغل أكتر
Autovacuum Tuning Complexity
الـ autovacuum هو المسؤول عن التنضيف بمعنى تاني:
إزالة الـ dead tuples
تقليل الـ bloat
الحفاظ على أداء الـ DB
ولكن لو كان aggressive بزيادة → بيزاحم الـ queries ولو كان conservative بزيادة → الـ bloat والـ latency بيعلوا
عشان كده autovacuum tuning واحد من أعقد أجزاء تشغيل PostgreSQL في الـ production.
Scaling PostgreSQL to Millions of QPS
عشان يقللوا الضغط على الـ writes، بدأوا يرحلوا الـ workloads اللي ينفع تتقسم (shardable) واللي فيها writes كتير لأنظمة sharded زي Azure Cosmos DB، وكمان عدلوا على الـ application logic عشان يقللوا أي writes ملهاش لازمة.
كمان، منعوا إضافة أي tables جديدة على PostgreSQL الحالي. وأي workload جديد بقى default يروح على الأنظمة الـ sharded.
ورغم كل التطوير ده، PostgreSQL لسه unsharded، وفيه single primary مسؤولة عن كل الـ writes. والسبب هو إن الـ sharding للـ workloads الحالية معقد جدًا، وعايز تغييرات كتيرة في مئات الـ endpoints، وممكن ياخد شهور أو سنين.
وبما إن معظم الشغل كان عندهم read-heavy، ومع شوية optimizations قوية، فالتصميم الحالي لسه مديلهم مساحة كافية للنمو. فكل بساطة الـ sharding لـ PostgreSQL ممكن يحصل في المستقبل، بس مكنش أولوية ليهم دلوقتي.
Reducing Load on The Primary
المشكلة: الـ Single-primary لوحده بكل تأكيد مش هيعرف يعمل scale للـ writes. وأي spike في الـ writes ممكن يوقع الـ primary وبالتالي يأثر على ChatGPT والـ API.
فالحل: بدوا يقللوا الحمل على الـ primary لأقصى درجة ممكنة وده من خلال الآتي:
عمليات القراءة - reads بتروح على الـ replicas
الـ reads اللي جوه write transactions بيخلوها optimized لإنها كده كده لازم تعدي على الـ Primary
والـ write-heavy shardable workloads اتنقلت لـ CosmosDB زي ما وضحنا
كمان صلحوا bugs كانت بتعمل redundant writes علشان يقللوا عمليات الكتابة قدر المستطاع
استخدموا الـ lazy writes ومن اشهر الـ techniques لحاجة زي كده (batching, debouncing, write-behind-cache)
وعملوا strict rate limits أثناء عمليات الـ backfilling لبعض الـ fields اذا دعت الحاجة لده عشان يقللوا الضغط على الـ writes.
Query Optimization
المشكلة: الـ Queries التقيلة كانت بتاكل من الـ CPU جامد، ومع وجود الـ spikesالخدمة كانت بتبطّأ.