Modernizing Reddit's Comment Backend from Monolithic to Microservices
Modernizing Reddit's Comment Backend from Monolithic to Microservices
شركة Reddit عملت modernization للـ comment backend من legacy monolithic python لـ Go microservice. المقال ده بيشرح إزاي عملوا tap compare للـ write endpoints باستخدام sister datastores عشان يضمنوا safety… وفي الآخر p99 latency قلت تقريبًا للنص.
لو عندك system كبير وlegacy، غالبًا أسهل جزء في الـ migration هو الـ reads… لكن أول ما تيجي ناحية الـ writes، كل حاجة بتبقى حسّاسة جدًا: data integrity، caches، events، وخصوصًا لو عندك guarantees لازم ما تقعش أبدًا زي CDC events.
في المقال ده هنمشي خطوة بخطوة في تجربة Reddit وهي بتعمل modernization لـ comment backend: إزاي نقلوا من legacy Python service لخدمات Go microservices، وليه الـ tap compare لوحده مش كفاية في الـ write endpoints، وإزاي فكرة بسيطة زي “sister datastores” خلتهم يقدروا يعملوا validation حقيقي من غير ما يبوّظوا production data. وفي الآخر هنشوف إيه اللي اتحسّن فعلًا (خصوصًا في p99 latency)، وإيه الدروس اللي طلعوا بيها للـ Migrations اللي جاية.
Background
في Reddit فيه 4 Core Models هما اللي بيشغّلوا تقريبًا كل الـ use cases: Comments, Accounts, Posts, Subreddits. الأربعة models دول كانوا بيتهندلوا من legacy Python service قديم، والـ ownership بتاعه كان متقسم بين كذا team.
وفي 2024، الـ legacy Python service ده كان عنده تاريخ طويل من مشاكل كتير متعلقة بالـ reliability والـ performance. وكمان موضوع الـ ownership والـ maintenance بقى تقيل ومرهق على كل التيمز اللي شغّالة عليه. عشان كده فريق reddit قرر ينقل لحاجة أحدث: زي domain-specific Go microservices.
في النص التاني من 2024، الفريق بدأ يعمل fully migrating لأول comment model. وده منطقي جدًا… لان الـ Redditors بيحبوا يعبّروا عن رأيهم في الـ comments، فطبيعي إن الـ comment model هو الأكبر وعنده أعلى write throughput، فكان candidate قوي إنه يبقى أول migration يشتغلوا عليه.
How
الـ Migration بتاع الـ read endpoints عادة بيبقى مفهوم وسهل نسبيًا؛ وهم بيستخدموا tap compare testing. وفكرة الـ tap compare باختصار: هي انهم بيتأكدوا إن الـ new endpoint بيرجع نفس الـ response اللي بيرجعه الـ old endpoint من غير ما يأثروا على المستخدمين بالسلب.
وبيعملوا ده عن طريق:
توجيه نسبة صغيرة من الـ traffic للـ new endpoint
الـ new endpoint يطلع response
بعد كده (من جوّه) يعمل call للـ old endpoint
يحصل comparison بين الـ responses ويعملوا log للفروقات وشوية quality checks
وفي الآخر بيرجعوا للمستخدم response بتاع الـ old endpoint عادي زي ماهو عشان ميحصلش اي user impact، وبيحتفظوا طبعًا بالـ logs لو كان في اختلافات
بس في الحقيقة … الـ write endpoints قصة تانية خالص، وده جزء “المخاطرة” الحقيقي واللي ممكن يسبب مشاكل كبيرة.
ليه الـ Write Endpoints أخطر؟
أولًا: الـ write endpoints غالبًا بتكتب data في datastores (زي caches, databases… إلخ). وفيه كمان موضوع مهم جدًا: وهو ان reddit بتطلع CDC events لما أي حاجة تتغير في أي core model. والـ CDC events دي عندهم عليها 100% guarantee of delivery تقريبًا لأن في services تانية critical بتعمل consume للـ CDC events دي، فمينفعش يحصل gap أو delay أو أي مشاكل في الـ event generation.
وكنا شرحنا قبل كده الـ CDC واللي هو اختصار للـ Change Data Capture بالتفصيل في Use-case كانت بتتكلم عن Pinterest وتقدروا تشوفوها من هنا 👇
فبالنسبة للـ comments، فيه 3 datastores أساسيين بيتم الكتابة عليهم:
Postgres – backend datastore : اللي شايل كل الـ comment data
Memcached – caching layer
Redis – event store اللي بيتم استخدامه علشان الـ CDC Events
المشكلة هنا: لو حصل tap compare للـ write migration “زي ما هو” من غير اعتبارات خاصة للـ datastores، ممكن نوصل لحالة إن الـ new implementation بيكتب data غلط… وساعتها الـ old implementation مش هتعرف تقراها.
وعشان فريق المهندسين في reddit كانوا بيعملوا Migration لأكتر من data critical في Reddit، فمينفعش نعتمد على اكتشاف الفروقات بس من الـ production datastores.
طب إزاي نعمل Validate لعملية الكتابة من جزئين مختلفين من غير ما نكتب نفس الحاجة مرتين؟
هنا بقى ظهرت المشكلة الأساسية: بسبب الـ unique key restrictions على comment ids، فكرة إنك تكتب نفس الـ comment مرتين في نفس datastore مستحيلة (duplicate writing مش هيمشي).
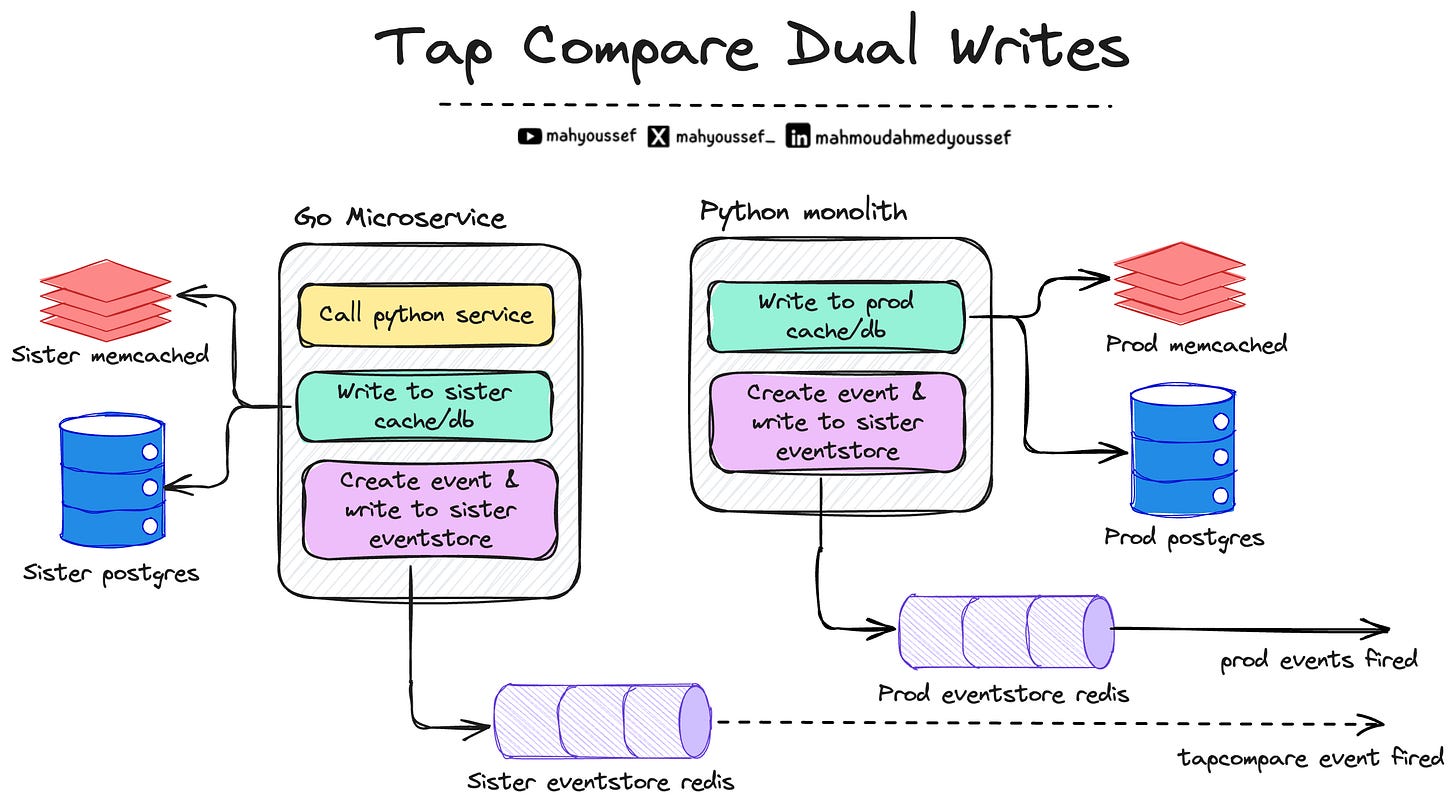
فالحل كان إننا نعمل 3 sister datastores جديدة — مخصوصة للـ tap compare testing — واللي يكتب فيها يكون بس الـ new Go microservice endpoints. وبكده نقدر نقارن اللي اتكتب في production datastores بواسطة الـ old endpoint، مع اللي اتكتب في sister datastores بواسطة الـ new endpoint… من غير ما الـ new endpoint يبوّظ أو يكتب فوق production data.
خطوات الـ Sister Writes Verification
فريق المهندسين بدأوا يوجهوا نسبة صغيرة من الـ traffic للـ Go microservice
الـ Go microservice يعمل call للـ legacy Python service عشان يعمل production write الحقيقي بدون اي مشاكل
وبعد كده الـ Go microservice يعمل write بتاعه هو في الـ sister datastores، ودي معزولة تمامًا عن الـ production
Tap Compare Dual Writes
وبعد ما كل الـ writes بتخلص، لازم نتحقق ويحصل Validation:
فبنقرأ من الـ 3 production datastores اللي الـ legacy Python service كتبت فيهم
ونقارنهم بالـ 3 sister datastores اللي Go كتب فيهم
وكمان عشان يعالجوا بعض الـ serialization issues اللي ظهرت بدري (إن مثلا الـ Python services مش قادرة تعمل deserialize لـ data اتكتبت من Go services)، عملوا verification للـ tap comparisons كمان جوّه comment CDC event consumers في الـ legacy Python service.
الخلاصة: ان فريق reddit قدر انه يعمل الـ Migration للـ 3 write endpoints، وكل واحدة بتكتب في 3 datastores، ويعملوا verify للـ data من خلال 2 services… فبقى فيه 18 tap compares شغالين، وده احتاج وقت زيادة عشان يراجعوا ويصلحوا اي مشاكل بتحصل من الـ Data Quality Checks.