في التجربة دي هنحكي تجربة Atlassian في الـ migration الخاص بملايين الـ Jira databases لـ AWS Aurora على نطاق ضخم وبأقل تأثير ممكن على المستخدمين.
فهنشوف إزاي Atlassian عملت migration لحوالي 4 مليون Jira databases لـ AWS Aurora على scale كبير جدًا وبـ minimal user impact، وإيه الـ technical challenges والاستراتيجيات والنتايج اللي ساعدتهم في تحقيق الـ reliability والـ performance والـ cost efficiency.
?How would you migrate a database, without your users noticing
السؤال الأساسي هنا: إزاي تعمل migration للـ database من غير ما المستخدمين يحسّوا؟
في Atlassian، هما بالفعل بيعملوا database migrations على scale كبير كجزء من شغلهم اليومي الخاص بالـ server rebalancing عشان يحافظوا على توزيع الـ load بشكل متوازن على الـ Jira database fleet.
وفي المتوسط بيعملوا migration لحوالي 1,000 قاعدة بيانات كل يوم … ومن غير أي انقطاع محسوس عند المستخدمين.
بس المرة دي ظهر ليهم تحدي جديد: إزاي نعمل migration لملايين الـ databases، وبـ minimal impact على المستخدمين؟
Background
Jira بتستخدم Postgres كـ backing store. يعني كل حاجة في Jira تقريبًا من الـ: issues, projects, workflows, custom fields… كله متخزن في database. والـ architecture عندهم: one database per Jira tenant.
وده مش architecture منتشر قوي، بس Atlassian اختارته عشان:
الـ isolation بتاعه أعلى
والـ scalability كذلك أفضل
وكمان الـ operational control أقوى على scale ضخم
وده كمان بيخلّي ضمان إن البيانات بتاعة tenant ما تتشافش بالغلط أو بسوء نية من tenant تاني، وكمان بيسهّل إنهم يعملوا horizontal scaling ويوازنوا الـ load ويحسنوا الـ performance ل tenants بأحجام مختلفة ومتفاوتة.
فهم موزعين 4 مليون database على حوالي 3,000 PostgreSQL servers في 13 AWS regions. وبما إن PostgreSQL عندهم شغّال على AWS RDS for PostgreSQL أو AWS Aurora PostgreSQL، فهم غالبًا ما بيقولوش “server” وبيستخدموا كلمة instance بدلها.
وبشكل دوري بيعملوا migration للـ databases جوّه الـ fleet بشكل مستمر عشان موضوع الـ rebalancing، وده من خلال طريقتين:
للـ small databases: بيعملوا backup + restore بسرعة على destination instance
للـ larger databases: بيعملوا logical replication بين source وdestination، وده بيخليهم ينسخوا البيانات على مهلهم والـ database والـ tenant شغالين طبيعي بدون أي مشاكل.
وبرضه المتوسط عندهم: 1,000 database migration كل يوم مع minimal interruption.
وعندهم تقسيمة شبيهة باللي AWS Well-Architected Framework: أغلب الـ tenants على shared infrastructure، وعدد صغير من الـ very large tenants على dedicated infrastructure. والـ very large tenants دول محتاجين resources ضخمة (أكتر من اللي ممكن يتوفر على RDS instance)، فكانوا متشغلين على Aurora PostgreSQL من زمان.
في أواخر 2023، بدأوا يدرسوا مشروع إنهم يعيدوا عمل نفس الكلام على باقي الـ fleet من الـ databases لـ Aurora PostgreSQL عشان يحققوا أهداف قوية في الـ cost والـ reliability والـ performance.
والفرق المهم هنا: إن إعدادات الـ RDS عندهم كانت بتسمح بـ single instance فعليًا في الاستخدام، إنما Aurora تقدر تستفيد من الـ writer والـ reader (وممكن multiple readers) في نفس الوقت. وده عمليًا خلّاهم يقدروا يصغّروا من الـ instance sizes للنص… مع كفاءة أعلى.
كمان Aurora عندها SLA أفضل: 99.99% بدل 99.95%، وعندها autoscaling وقت الـ peak لحد 15 readers (وده بيحصل عندهم فعلاً ساعات). وبعد ماكانت النتايج إيجابية قرروا يكملوا في رحلتهم.
Migration Design
فريق المهندسين في Atlassian كان عندهم اهداف واضحة، بس كمان حطّوا أهداف أثناء التنفيذ:
Minimise tenant downtime
Minimise cost عن طريق التحكم في كمية migration-related infrastructure
يخلصوا في وقت معقول (عمليًا: كام شهر)
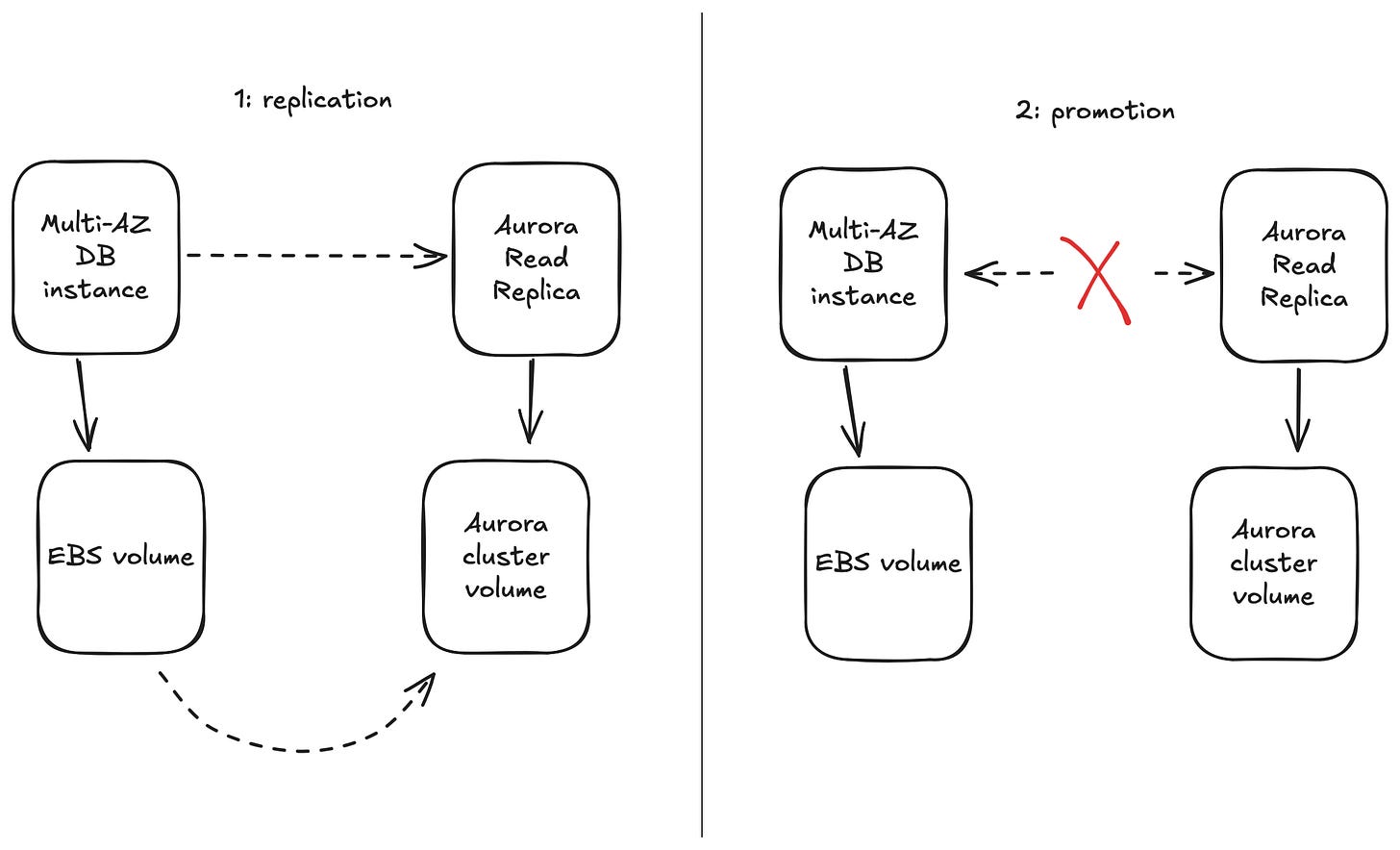
وبناءً عليه قرروا إن أفضل طريقة لكل RDS PostgreSQL Multi-AZ DB instance إنها تتنقل لـ Aurora كالتالي:
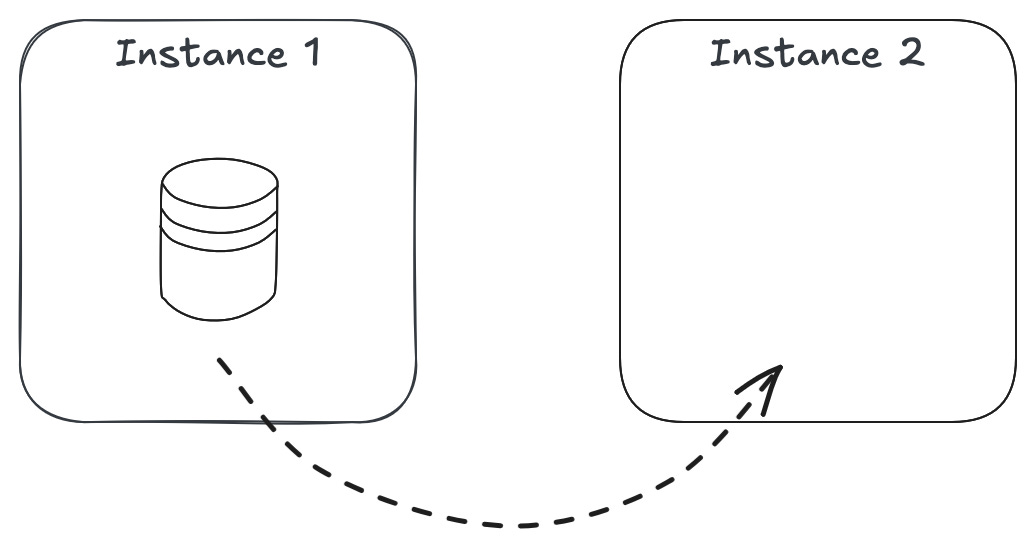
يضيفوا DB instance read replica للـ RDS PostgreSQL instance، والـ replica تـ synchronise data لـ new Aurora cluster volume (ودي feature موجودة في RDS).
يعملوا cutover في window مناسبة عن طريق إنهم يعملوا promoting للـ read replica دي وتبقى standalone Aurora cluster.
هم سمّوا العملية دي: conversion من RDS instance لـ Aurora cluster. وشكل الموضوع قد يبدوا غريب للبعض او ساذج شوية ولكن على scale Atlassian الدنيا بتبقى أعقد بكتير جدًا.
Migration Design: Replication & Promotion
Conversion
أول تعقيد: الـ clusters عندهم بتشيل لحد حوالي 4,000 databases في الـ cluster الواحد، وكل database هي عبارة عن tenant مختلف زي ما اتفقنا. وعلشان عاوزين نعمل migration لملايين ال databases فلما نيجي ننقل كل cluster هنلاقي اننا عاوزين نـ migration 4,000 tenant مرة واحدة.
يعني لما نيجي نعمل “promotion” للـ database replica ونحوّلها لـ standalone Aurora cluster، لازم عملية الـ cutover يحصل “مرة واحدة” لكل الـ 4,000 tenants، وكل واحد ليه:
unique connection endpoint
unique credentials
وكمان لازم يحدّثوا الـ Jira application (الي شغال على EC2 instances) عشان يستخدم الـ endpoint الجديد لكل tenant… وبطريقة تضمن 100% إن مفيش أي writes هتروح بالغلط للـ database القديمة.
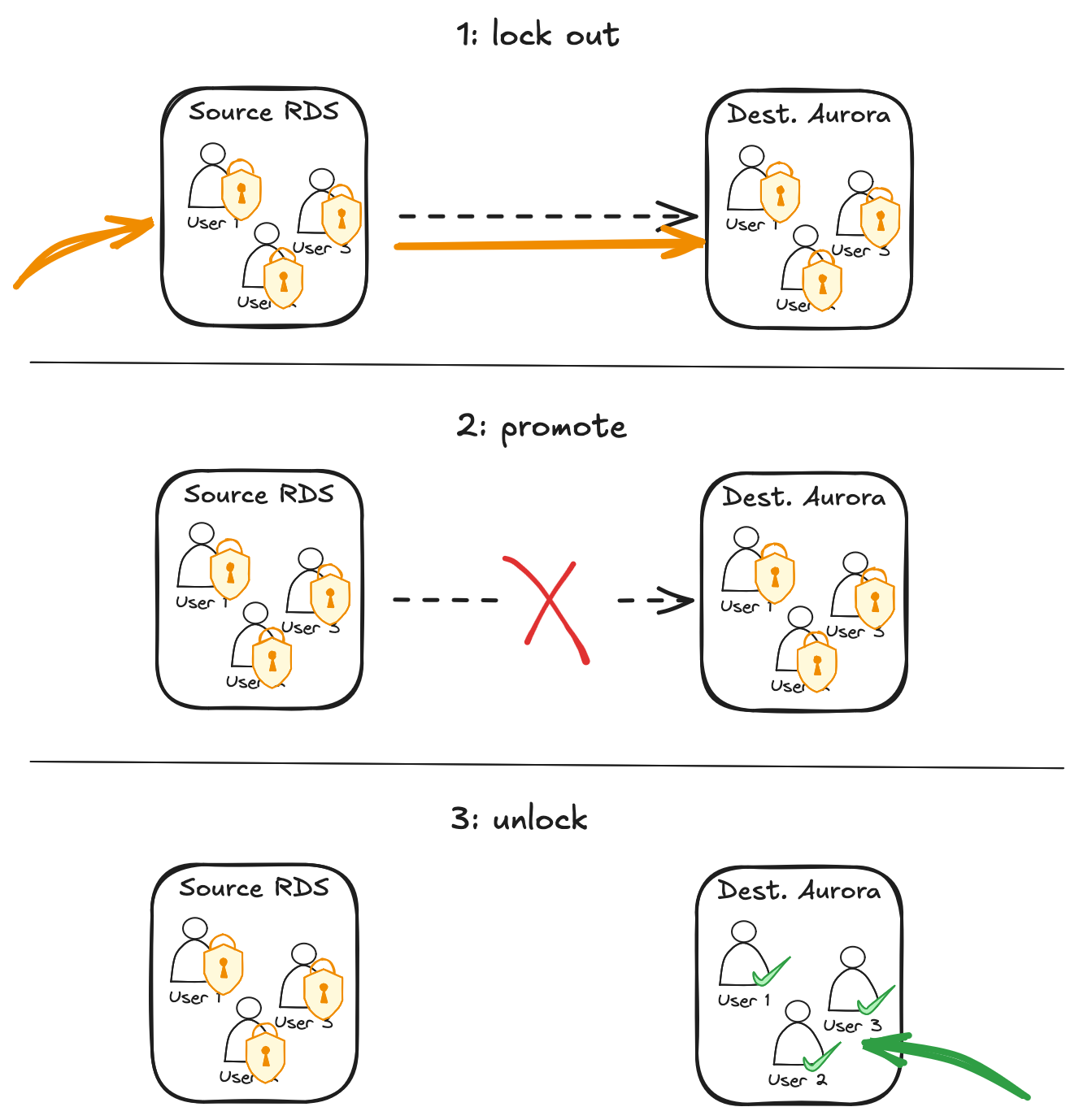
فعشان يضمنوا ده، عملية cutover كانت بتعمل الآتي:
lock out لكل SQL user على source instance
تكمل promotion للـ Aurora cluster
وبعدها تعمل unlock للـ SQL users بس على الـ destination
Conversion Plan: Lock out , Promote & Unlock
وكل ده كان orchestrated بـ AWS Step Function بتعمل safety checks قبل وأثناء وبعد عملية الـ conversion، وعشان لو أي حاجة غلط ممكن تحصل يرجعوا بسرعة للوضع الطبيعي. وبعد الـ conversion كانوا بيراقبوا الـ customer traffic كام ساعة عشان يتأكدوا إن كل حاجة تمام.