Halo 4 Gameplay Scales Beyond Billion of Games Using Saga Pattern
Halo Gameplay Scales Beyond Billion of Games Using Saga Pattern
سلسلة Halo من أكتر ألعاب التصويب شهرة على Xbox، وخصوصًا مع Halo 4 حصل انفجار ضخم في أعداد اللاعبين والجيمز: ملايين المستخدمين، ومليارات الجيمز المتسجّلة. ورا التجربة دي فيه منظومة Distributed Systems كبيرة بتلمّ Statistics لكل لاعب بعد كل ماتش.
سلسلة Halo من أكتر ألعاب التصويب شهرة على Xbox، وخصوصًا مع Halo 4 حصل انفجار ضخم في أعداد اللاعبين والجيمز: ملايين المستخدمين، ومليارات الجيمز المتسجّلة. ورا التجربة دي فيه منظومة Distributed Systems كبيرة بتلمّ Statistics لكل لاعب بعد كل ماتش—عدد القتلات، المساعدات، الدقة، إلخ—وبتعرُضها على موقعهم وخدمات تانية.
المعضلة بدأت لما البنية القديمة كانت مبنية على SQL Database واحدة كـ Source of Truth، وده ما بقاش بيـ Scale مع الأرقام المهولة دي.
الأرقام بتاعة Halo 4 كانت مرعبة وده لإن تقريبًا كان فيه 1.5 billion games played و11.6 million مستخدم. فكان واضح إن Single Giant SQL Database مش هتستحمل.
فقرروا يعيدوا كتابة الـ Services وينقلوها لـ Azure Cloud، واستعملوا Azure Table Storage كأكبر شكل من الـ NoSQL — Key-Value Store. وده خلق تحدّي كبير: زمان هم كانوا عايشين على الـ Transactions في Database واحدة والي بالتأكيد بتضمن الـ Consistency، دلوقتي البيانات متقسّمة على Partitions كتير.
Halo Journey to Scale
الفريق بدأ يفكر بشكل كبير ازاي يقدروا يحلوا المشكلة دي ، لحد ما وقع قدامهم الورقة البحثية من 1987 واللي كانت بتتكلم عن الـ Saga Pattern ، فطبقوا الكلام ده عشان يقدروا يعملوا Processing للاحصائيات بطريقة شبه Transactional ، وبنقول هنا "شبه Transactional" عشان بالتأكيد كان فيه تنازلات عن شوية ضمانات قرروا يتنازلوا عنها زي مثلا ان مفيش Serializability ولكن في النهاية ده كان في سبيل تحقيق الـ Consistency من بداية لنهاية الـ Transaction ويعرفوا يتصرفوا في الـ Failure Scenarios.
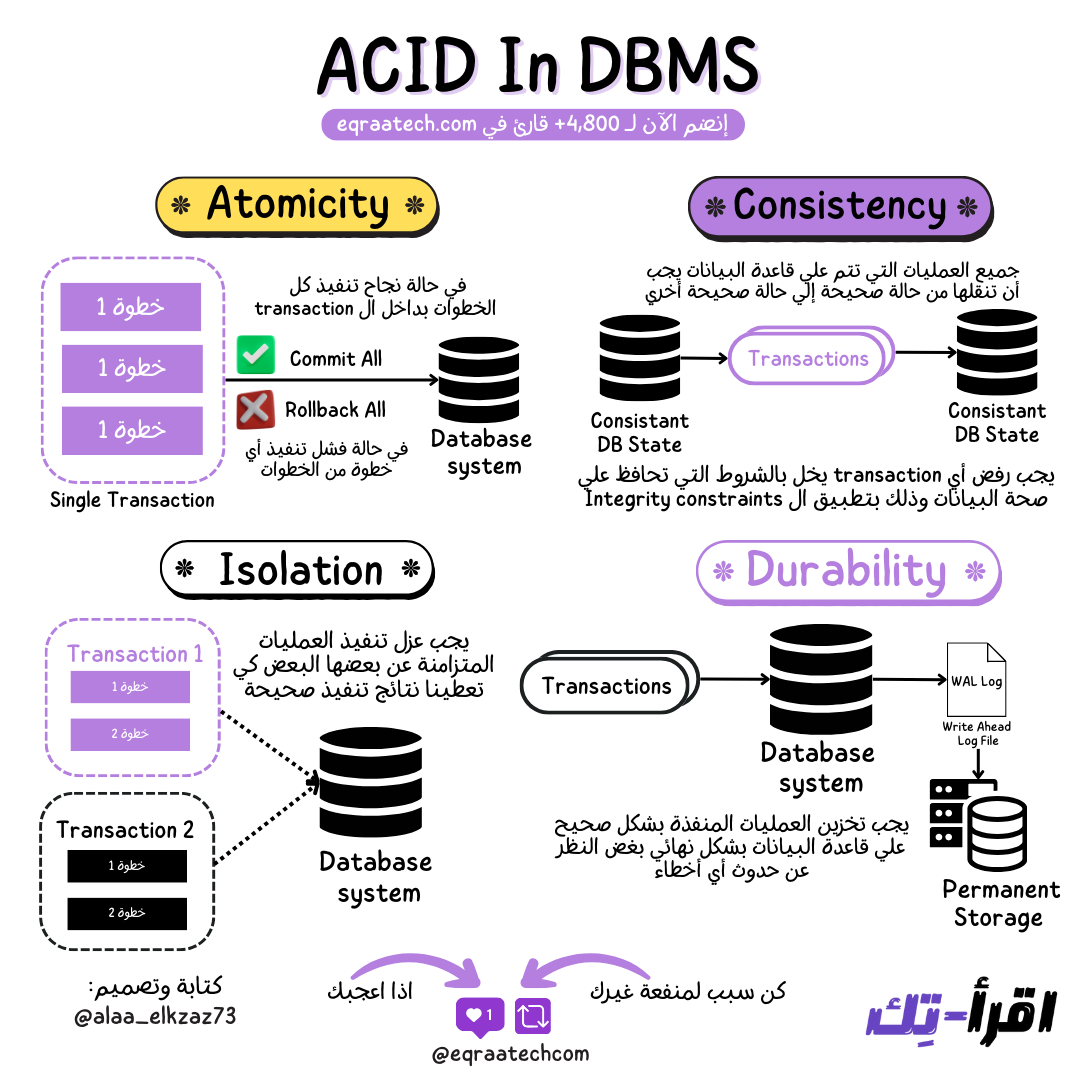
الطبيعي إن أي System بيكون في بدايته بسيط جدًا فبيكون عبارة عن App أو Website بيكلم Stateless Service واللي بدورها بتكلم Database ضخمة وبالتالي بناخد الضمانات الجميلة اللي كلنا عارفينها من الـ ACID Properties زي الـ Transactions والـ Serializability وغيرهم.
Simple Web / Mobile Applications
وكتذكرة الـ Serializability هي بكل بساطة عبارة عن ضمان بيضمن إن كل العمليات الـ Concurrent تبان إنها هتحصل بشكل Sequential بدون أي مشاكل أو بدون مالعمليات تدخل في شغل بعضها.
والـ ACID عملنا عنها ورقة قبل كده فتقدروا تشوفوها من الرابط ده:
ده كان الحال زمان ، ولكن دلوقتي احنا عايشين وسط الـ Microservices والـ Distributed Systems فموضوع ان يكون عندنا Database واحدة هي الـ Single Source of Truth مبقاش واقعي وكمان لما بنيجي نبني نطبيقات حاليًا فالتطبيقات دي بشكل ما أو بآخر هتكون يا بتكلم الـ Internal APIs بتاعتنا يا هتكون بتكلم APIs مختلفة وبتاعة حد تاني وكل APIs من دي هتكون Behind The Scene عندها الـ Database اللي بتتعامل معاها.
SOA/Microservice Architecture
فمفيش حاليًا Database واحدة عملاقة فيها كل البيانات اللي محتاجينها.
Two-Phase Commit
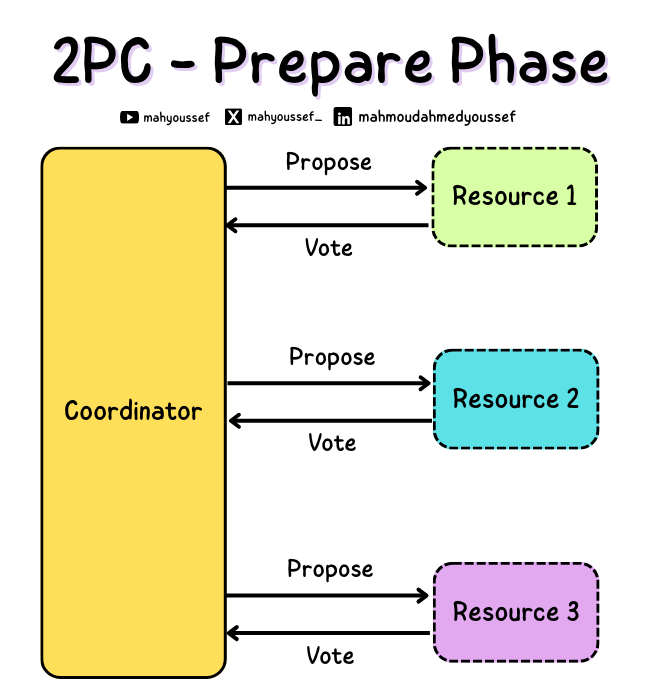
وعشان نحل مشكلة الـ Distributed Transaction في الـ Distributed Systems ظهر الأول مفهوم الـ Two Phase Commit وده عبارة عن Atomic Commitment Protocol ونوع فريد من الـ Consensus Protocol واللي فيه بيكون عندنا 2 Phases أو مرحلتين ، وهم الـ Prepare / Commit.
فبيكون عندي Single Coordinator واللي بالمناسبة ممكن يكون Single Point of Failure ، وسعتها الـ Coordinator بيتواصل مع كل الـ Services اللي مفروض تكون متعلقة بالـ Transaction ده ، وبيشوف هل الـ Resources أو الـ Services دي جاهزة انها تنفذ الـ Transaction ده ولا لا ، في المرحلة دي الـ Services دي بتصوت يا بنعم أو لا.
2PC - Prepare Phase
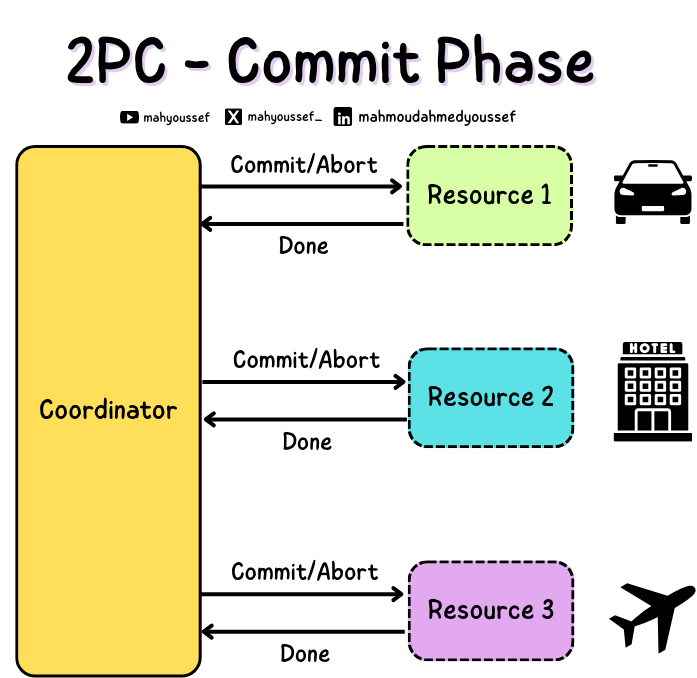
ووقتا الـ Coordinator بيجمع الأصوات دي كلها ، ونبدأ مرحلة الـ Commit Phase واللي وقتها لو كل الـ Services جاوت بنعم انها جاهزة تنفذ الـ Transaction ، فبيبعت الـ Transaction لكل Service لان كل Service خلاص أكدت أو صوتت بنعم أو Commit إنها تنفذه وجاهزة لتنفيذه.
ولو فيه Services جاوبت بلا ، فده معناها انها مش جاهزة للـ Transaction وبالتالي نقدر نلغيه أو نعمل Abort فكده احنا نقدر نتحكم ان يا اما الـ Transaction كله يتم أو لا بناء على الـ Votes اللي طلعنا بيها من الـ Services اللي داخلة في الـ Transaction.
2PC - Commit Phase
وفي النهاية بعد ما كل Service تشتغل على الـ Transaction بترد بالآخر بـ Done بحيث الـ Coordinator يكون عارف النتيجة النهائية من كل Service ويقدر بناء عليها يحدد اذا كان خلاص تمام ولا فيه مشكلة وهنضطر نـ Abort.
شركات كتير بتستعمل الـ 2PC لحل مشكلة الـ Distributed Transactions ولكن مشكلة الحل ده إنه بيكون ماشي كويس في البداية لحد ما نوصل لنقطة إنه مش Scalable.
لو فيه Failures ممكن نوصل لـ O(N^2) رسالة رايحة جاية جوا الـ System
الـ Coordinator هو Single Point of Failure فلو فيه مشكللة حصلت ووقع مننا في نص الـ Transaction ، الـ Transaction كله هيبقى Aborted حتى لو الـ Services التانية شغالة كويس.
ولو عندنا Resources او Services كتير داخلة في الـ Transaction فاحنا عرضة طبعًا للـ Latency وبالتالي هنكون مرتبطين ومضطرين نصبر ونكون Bounded بأبطأ Resource أو Service في النظام بتاعنا.
الـ Throughput كمان مش أفضل حاجة وده لإننا بنكون ماسكين Locks على الـ Resources دي واحنا شغالين في الـ Transaction ومش عاوزين حاجة تعدل أو تغير فيهم وسط الـ Transaction اللي شغال.
بالاضافة كمان إن معظم الـ Cloud Providers في الشركات الكبيرة زي Google , Azure مش بيستعملوه بسبب المشاكل الي ذكرناها وانه مش بيـ Scale بشكل كويس.
Google Spinner
بالنسبة لشركة Google فهي عندها Spinner ودي الـ Distributed Database بتاعتهم وكمان كانوا عملوا Paper ليها وبتحقق الـ Distributed Transactions من خلال الـ TrueTime API باستعمال الـ GPS و الـ Atomic Clocks في الـ Data Centers بتاعتهم.
بالإضافة كمان إن الـ Data Centers بتاعتهم مربوطة ببعضها بـ Fibers خاصة بيها فأغلب مشاكل الـ Network اللي الشركات بتمر بيها هم في غنى عنها بشكل كبيرا.
واللي بيعمله الـ TrueTimeAPI هو إنه بياخد كل الـ inputs من الـ system واللي بيتضمن الـ GPS والـ Atomic Clocks وبعدين يحسب الـ Time Bound للوقت اللي حصل فيه الـ Event وبالتالي يقدروا يستعملوه في إنهم يحددوا الترتيب الزمني السليم للـ Events اللي حصلت بترتيبها.
وجب القول برضو إن ده بيكون عرضة لـ Downtime قدره بيكون حوالي 7 مللي ثانية ، فالـ Synchronization مش 100% ولكن من خلال الـ Time Bound Window الصغيرة جدًا دي بيشتغل بشكل كويس.
طب ايه اللي مخلهمش ياخدوا قرار إنهم يستعلموا Google Spinner ؟ ده لإنه في الواقع كان وقته غالي جدًا بالإضافة كمان لإن الـ Synchronization لسه مشكلة ملهاش حل.
Complexity of Distributed Transactions
اللي محتاجين نفهمه في الرحلة دي لحد دلوقتي واللي عاوزينه يوصل للكل هو إن الـ Distributed Transactions مكلفة جدًا وصعبة جدًا في التعامل معاها ، خصوصا كمان لو محتاجين الـ System يكون فيه الـ Serializability والـ ACID متحققين زي قواعد البيانات العادية.
وعشان كده القرارات في النظم الموزعة أو الـ Distributed Systems واللي مختصة بالتصميم غالبًا بتتضمن فيها Trade-Offs ، إحنا لازم نقدم تنازلات في سبيل تحقيق هدف معين محتاجين نحققه.
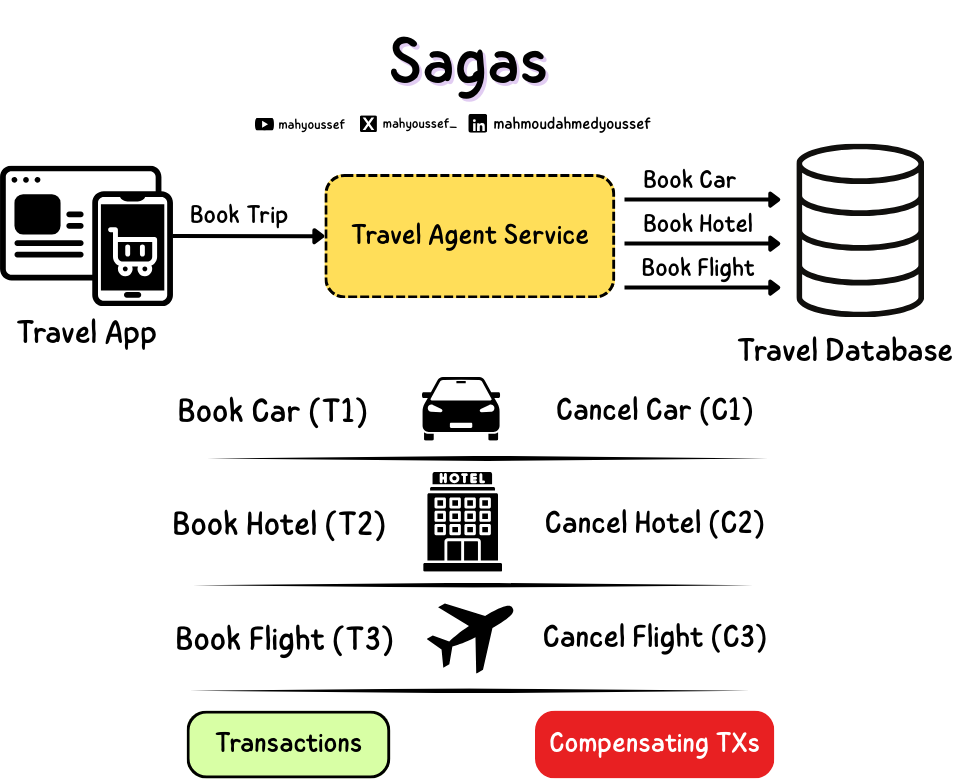
Saga Pattern
ومن هنا بدأت الـ Sagas ، الـ Saga هو عبارة عن Long Lived Transaction يعني Transaction عمره طويل شويتين واللي بيكون متمثل كـ Sequence من الـ Sub Transactions المختلفة واللي ممكن يحصلهم تداخل مع بعضهم البعض.
وكل Sub-Transaction بيكون ليه Compensating Transaction خاص بيه. يعني ايه الكلام ده ؟
في آخر الـ Saga يا إما كل الـ Transactions في الـ Sequence ده تخلص بنجاح يا إما لو فيه مشاكل حصلت وبعض الـ Transactions حصلها Failure ، بنشغل Compensating Transactions اللي هي خطوات تعويضية عن فشل العملية اللي حصلت ، نقدر من خلالها نرجع أثر اللي اتعمل في النظام زي مثلًا إننا نـ Cancel Booking او نعمل Refund.
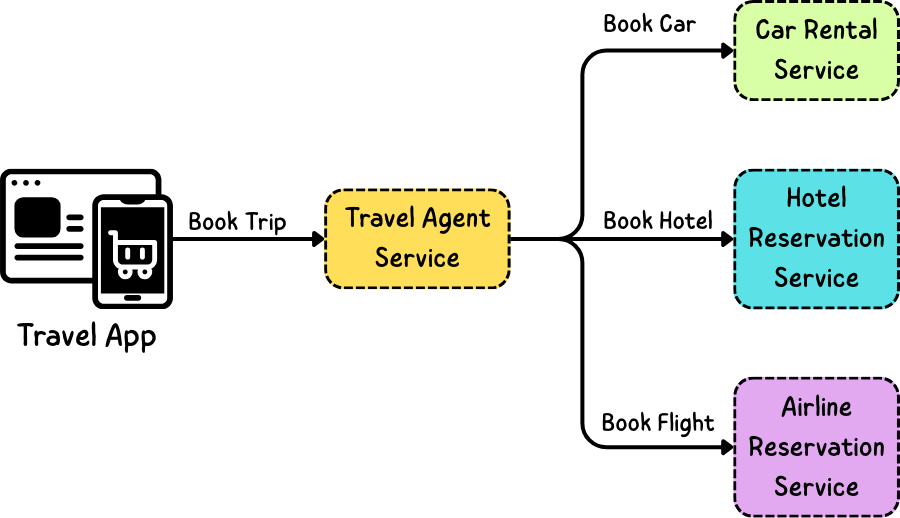
فلو عندنا مثلا سيستم حجوزات وعاوزين نحجز رحلة سفر ، فلو حجز العربية والفندق تم بنجاح ، ولكن حجز الطيارة حصل فيه مشاكل ، بنروح نلغي حجز الفندق والعربية ، بدل ما نسيب الدنيا نص محجوزة.
خلونا نشوف ده في Single Database ممكن يكون عامل ازاي ، واللي سهل بعد كده برضو نتخيله في الـ Distributed Systems:
Large Single Transaction - "Book Trip"
فزي ماحنا شايفين قبل ما يكون عندنا Saga كنا بنبعت Single Transaction اسمه Book Trip ولكن دلوقتي ده هيتقسم لـ Sub Transactions وهم الـ Book Car, Book Hotel وكمان Book Flight فبقى عندنا Sub Transaction كل واحد فيهم ليه الـ Compensating Transaction الخاص بيه.
Sagas in Single Database
حاجة تانية مهمة نذكرها هنا إن ليه بنضطر نلجأ للـ Compensating Transactions ؟ لإن في بعض الحالات هنلاقي إن ما ينفعش نعمل Undo ، زي مثلا فيه System بعت Email خلاص مش هنعرف نلغي العملية دي ، فبالتالي بيكون فيه مثلا Compensating Transactions إننا نعمل Follow-up Email يصلح اللي حصل كـ Corrective Action.
في الـ Saga احنا بنضحي بالـ Atomicity في سبيل تحقيق الـ Availability. فالـ Sub Transactions اللي في الـ Saga هيتنفذوا بشكل مستقل تماما عن بعضهم ، بدون ترتيبات مسبقة ، فلو عازين نحقق الـ Atomicity ده مش هنوصله من خلال الـ Saga ولكن معظم التطبيقات بتكون مش محتاجة فعلًا ده.
Saga Execution Coordinator
طب ازاي الكلام ده بيشتغل فعليًا ؟ لو احنا مكملين في مثال الـ Single Database عشان الموضوع يكون أسهل للشرح ، فاحنا بيكون عندنا Process قايمة بجانب الـ Database اسمها SEC وهي اختصار لـ Saga Execution Coordinator.