Dropbox's Chrono: Scalable, Consistent and Metadata Caching Solution
عملية تخزين الـ Metadata واسترجعاها كان من فترة طويلة محور أساسي ومهم لفرق الـ Metadata في Dropbox وعشان كده من ضمن التحسينات اللي عملوها انهم يبنوا Scalable و Consistent Metadata Caching Solution.
عملية تخزين الـ Metadata واسترجعاها كان من فترة طويلة محور أساسي ومهم لفرق الـ Metadata في Dropbox ومؤخرًا فريق المهندسين عمل تحسينات ملحوظة في البنية التحتية.
التحسينات دي كان من ضمنها إنهم يبنوا الـ Scalable Key-Value Storage الخاص بيهم تدريجيًا ، وبالشكل ده قدروا إنهم يتجنبوا احتياجهم الأساسي لمضاعفة الـ Hardware.
ولكن مع تطورهم ومع وجود Scale كبير ، ده برضو كان قصاده تحديات مستمرة مقدروش إنهم يتجنبوها بسهولة.
Context
الـ Internal Clients اللي بيستعملوا Dropbox Metadata فضلوا لمدة طويلة بيعتمدوا على فرضية إن البيانات اللي هيتم استرجاعها لازم توفر ضمان الـ read-after-write فعلى سبيل المثال :
لما نيجي نعمل عملية Write لـ Key معين وبعدين علطول نعمل عمليات قراءة متتابعة للـ Key ده ، المفترض اني اقدر اشوف اللي عملتله Write بمعنى أدق لازم دايمًا أشوف الـ Recent Value اللي حصلت من عملية الـ Write ولا مجال لوجود Stale Values.
ولو كان فريق الـ Metadata كبر دماغه وقال إن الضمان ده مش مهم ، خصوصًا في أغلب التطبيقات الحالية اللي بتعتمد على الـ Eventual Consistency ، كان هتبقى مشكلة كبيرة من ناحية الـ Auditing وإنهم يغيروا كل الـ Client Code الخاص بالفرق التانية ، وده كان هيضطرهم لمجهود كبير جدًا ومضاعفات من ناحية الـ Client Side وكان هيقلل من سرعة فرق التطوير والـ Product Teams كذلك.
فعشان يحلوا مشكلة الـ High-Volume Read QPS واللي بتعرف برضو بالـ "Queries Per Second" المهولة اللي بتحصل عندهم وفي نفس الوقت يظلوا محافظين على توقعات الـ Client بتوعهم من ناحية الـ Read Consistency وعدم وجود Stale Reads ، فالحلول التقليدية من الـ Caching ما كنتش هتنفع.
فكان لا بد من وجود Scalable Consistent Caching Solution عشان يحل المشكلة دي.
Chrono
ومن هنا جه Chrono وهو عبارة عن Scalable و Consistent Caching System مبني فوق Key-Value Storage System بيستعملوه وهو Panda. وقادر إنه يعيش ويـ Survive مع الكميات المهولة من عمليات القراءة والـ High-Volume Read QPS.
Consistent Caching Challenges
استخدام الـ Caching بشكله البسيط والتقليدي في الـ Database Layer مش بيدينا ضمانات القراءة بعد الكتابة "Read-After-Write" اللي عاوزين نحققها. فمثلًا، لو كتبنا في قاعدة البيانات وبعدها كتبنا في الـ Caching، ممكن يحصل إن الـ Server يتعطل بين العمليتين، وده يخلي البيانات اللي في الـ Caching قديمة.
وحتى الطرق البسيطة لتحديث الـ Caching مش بتكون مضمونة. فخلونا نتخيل السيناريو ده: لو عندنا القيمة القديمة للـ Key = K في الـ Storage هي v1، وفي الـ Cache هي كمان v1:
الـ Writer لو حاول يكتب K=v2 فاحنا في البداية محتاجين نمسح القيمة القديمة من الـ Cache للـ Key = K.
الـ Reader 1 وهو بيقرأ من الـ Cache مش هيلاقي حاجة وده لإننا مسحناها، فهيروح يقرأ من الـ Storage Layer نفسها وهيلاقي إن النتيجة هي v1.
الـ Writer بعد كده بيكمل الكتابة عادي جدًا في الـ Storage ويخزن v2.
الـ Reader 2 وهو بيقرأ من الـ Cache مش هيلاقي حاجة، فهيروح يقرأ من الـ Storage Layer وهيلاقي v2 ووقتها هيخزنها في الـ Cache إن الـ K = v2.
الـ Reader 1 في الأول حصله Cache Miss وبالتالي قرأ من الـ Storage Layer إن الـ K = v1 فهو دلوقتي هيروح يكتب v1 في الـ Cache بعد ما عمل Cache Invalidation.
فهنلاقي إن النتيجة إن الـ Cache دلوقتي بيحتوي على بيانات قديمة بالنسبة للـ Storage Layer. نتيجة إن فيه Concurrent Read حصلت وبينهم حصل Concurrent Cache Miss واثناء ما كل Reader بيحاول يـ Invalidate الـ Cache بالقيمة الجديدة فيه واحد عمل Write على التاني بالقيمة القديمة.
Consistent Caching at Scale
فـ Chrono زي ماوضحنا هو مبني فوق Panda، وPanda عبارة عن الـ Multi-Version Concurrency Control واللي هي الـ (MVCC) للـ Key-Value Storage System الخاص بـ Dropbox.
فـ Panda بيوفر Commit Timestamp لكل عملية كتابة ناجحة، وكل بيان (Key/value Pair) بيكون مربوط بالـ Commit Timestamp لعملية الكتابة اللي أنشأته. والـ Commit Timestamp للـ Key بيزداد بشكل Monotonic مع عمليات القراءة المتتابعة.
Panda APIs
طبعًا Panda بيوفر APIs لكتابة وقراءة البيانات باستخدام الـ Timestamps دي و Chrono بيستخدم الـ APIs المتوفرة من خلال Panda لتحقيق الـ Consistent Caching.
الـ (Write API): بيتم استخدامه لكتابة البيانات في Panda، ولو الـ Timestamp اللي اختاره Panda للكتابة أكبر من الـ Timestamp اللي العميل حددّه، عملية الكتابة بتفشل.
الـ (Snapshot Read API): بيسمح للعميل يقرأ البيانات من لحظة معينة في الزمن باستخدام Timestamp محدد.
الـ (GetLatest API): بيرجع أحدث البيانات المتاحة للقراءة مع الـ Timestamp.
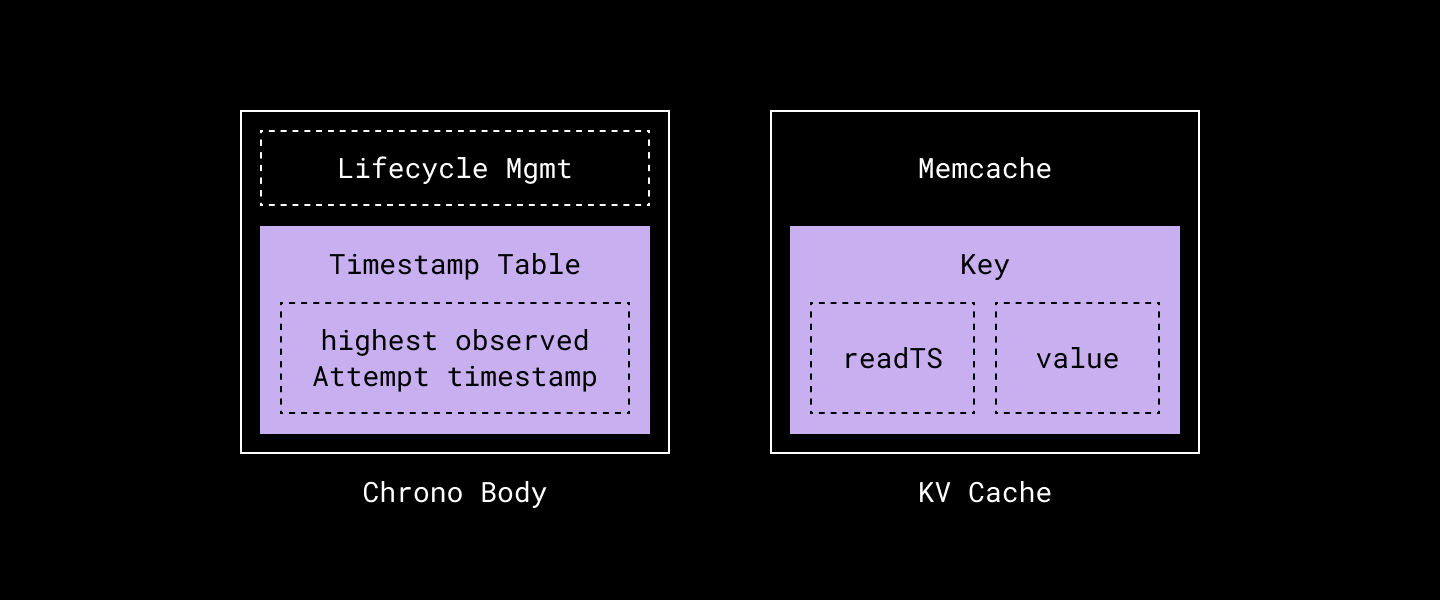
وبالشكل ده Chrono يقدر يخزن الـ Timestamp لأحدث محاولة كتابة لكل Key، وده بيساعد إننا نتأكد إن الـ Caching ما فيهوش بيانات قديمة أو إن فيه Stale Data.
How Chrono Works
باختصار Chrono هو خدمة بتقولك الـ Timestamp لأحدث محاولة كتابة لأي بيان في الـ Storage System.
فـ Chrono بيوفر API اسمه Attempt، اللي العميل بيستخدمه قبل كتابة البيانات، وبيحدد الـ Timestamp للمحاولة. والـ Timestamp ده لازم يكون أكبر شوية من الزمن الحالي لضمان عدم فشل الكتابة، لكنه مش كبير لدرجة إنه يعوق الـ Caching.
فكده عشان نكون في الصورة بشكل أوضح Chrono مش دوره إنه يقوم بتخزين الـ Data Values للـ Keys وده لإن المهمة دي سهل يتم تفويضها لـ KV Cache System زي Redis أو Memcache. ولكن غرضه هو إنه يقولنا الـ Latest Write Attempt Timestamp أو "آخر محاولة كتابة" لكل Key.



















{kind=link}