

المقدمة
في عالم الذكاء الاصطناعي المتطور، أصبح استخدام النماذج اللغوية الضخمة (LLMs) جزءًا أساسيًا في عمل ال developers وال ML Engineers.
هنا تأتي أهمية ال Prompt Engineering، حيث نتعلم كيفية صياغة التعليمات (prompts) بطريقة تجعل الـ LLMs تنتج مخرجات دقيقة وذات مغزى. ورغم تدريب ال LLMs على كميات ضخمة من البيانات، إلا أن وضوح ال promptsيزيد من دقة النتائج.
في هذه المقالة، سنستكشف استراتيجيات الـ Prompt Engineering لتحسين أداء النماذج وتوسيع تطبيقاتها.
فرصة تكسب 6,000 جنيه لو شغال بالـ AI
دلوقتي عندك فرصة تبهرنا بأفكارك 💡 وتدخل عالم الـ AI حتى لو مش AI Engineer! كل اللي محتاجه إنك تتعلم Flowise AI وتبني Agents تناسب ثقافتنا واحتياجاتنا 💬.
أمثلة بسيطة:
- لخدمة القرآن الكريم أو الحديث الشريف.
- مساعدة الأمهات في التعليم وتلخيص شغل جروب الماميز.
- تسهيل تجهيزات الجواز: "عفشك منين؟ جهازك منين؟".
- صيانة السيارات بأسلوب عملي وسريع.
- التخطيط المالي وتقييم القرارات بطريقة ذكية.
ودي مجرد أمثلة! تقدر تبدع أكتر في حاجات تساعد ناس تانية في Industries مختلفة.
الجوائز المميزة 💰
- جايزة لأحسن Agent من وجهة نظر لجنة الحكام. 🏆
- جايزة لأكتر شخص هيبعت Agents عدّت شروط التقييم. 🎯
- جايزة لأكتر Agent خد Votes من الكوميونتي بتاعتنا. ❤️
هتشتغل على تاسكات مميزة 💻، تنافس ناس زيك 🤝، تبني خبرة قوية 📚، وتضيف إنجازات لمحفظتك 💼.
متفوتش الفرصة دي! سجل دلوقتي🚀

تعريف الـ Prompt Engineering
ببساطة، هي فن كتابة الأسئلة أو التعليمات اللي بتوجه الـ LLMs، علشان نطلع منها النتيجة اللي إحنا عايزينها. العملية دي بتعتمد على شوية إرشادات (guidelines) لو اتبعناها صح، هتحسن بشكل كبير من جودة الردود اللي بنحصل عليها.
بعض هذه الإرشادات مستمدة من تجارب المستخدمين العاديين، والبعض الآخر من تطوير OpenAI، بينما جزء منها يعتمد على فهمنا العميق لمعالجة اللغة الطبيعية (NLP).
مراحل تطورات الـ Prompt engineering
- Enhanced contextual understanding: مع تطور الـ LLMs زي GPT-4، بقت قادرة على فهم السياق بشكل أدق.
- Adaptive prompting techniques: الـ models دلوقتي بتتعلم ازاي تعدل ردودها حسب طريقة كتابة المستخدم. تفضيلاته وبالتالي المحادثه أصبحت natural and user-friendly
- Multimodal prompt engineering: فيه تقنيات جديدة بتتعامل مع أنواع مختلفة من البيانات زي النصوص والصور.
- Real-Time Prompt Optimization: تقديم ملاحظات فورية على ال prompt
- Integration with Domain-Specific Models: ال Domain-Specific Models بتكون مدربه علي داته من مجال معين وبتكون متخصصه.
LLM Output Configuration
لما تختار الmodel بتاعك، لازم تكوِّن الإعدادات الخاصة بيه بشكل صحيح. أغلب ال LLMs بتوفر لك اختيارات كتير تتحكم في المخرجات.
1- طول المخرجات Output Length
هنا بحدد عدد ال tokens اللي هتطلع في الرد. تقليل ال Output length مش هيخلي الmodel يكتب بشكل مختصر أو دقيق، هو هيقول نفس الكلام بس اول ما ال capacity تخلص هيقطع كلامه.
2- التحكم في العينة Sampling Controls
الموديل بيتوقع احتمالات (probabilities) لعدد من ال tokens الي ممكن تيجي بعد الكلمة الحالية كل واحد قصاده احتماليه ان هو يكون الtoken القادم. في techniques زي Temperature وTop-K وTop-P بتساعدني أتحكم في كيفية اختيار الرموز.
1) Greedy Decoding
هو طريقة بسيطة بيستخدمها ال LLM عشان تولد الToken القادم. الطريقة دي بتعتمد على اختيار الكلمة أو الtoken اللي احتمالها أعلى (high probability) .
مثال:
- الmodel بياخد المدخلات (ال prompt علي سبيل المثال "اهلا").
- بيحسب احتمالات للكلمات اللي ممكن تيجي بعد المدخلات دي.
- هاي → 0.25 مرحبا → 0.4 أهلاً → 0.35
- بيختار الكلمة اللي عندها أعلى احتمال" <-- مرحبا"
- بيضيف الكلمة المختارة للجملة، ويكرر نفس العملية للرمز اللي بعده.
- العملية دي بتفضل مستمرة لحد ما يوصل لعدد معين من الكلمات أو لنهاية الجملة
2) Temperature
ده بيسيطر على مدى عشوائية اختيار الtoken. لو خليت الـTemperature قليل، هتلاقي الإجابة أكتر تحديدًا وثباتًا لانه هيميل انه يختار الtokens ذات اعلي probabilities. لو خليت الـTemperature عالي، هتكون الإجابة أكتر تنوعًا أو مفاجئة او creative.
- لو خليت الـTemperature صفر، هيبقى الاختيار دائمًا للرمز اللي ليه أعلى احتمال زي ال الـGreedy Decoding.
3) Top-K
ده بيختار الـ K-tokens الأكثر احتمالية من الtokens اللي اتوقعه الmodel. لو خليت الـK عالي هنا بنختار من مجموعه كلمات كبيره فهتلاقي الإجابة أكتر إبداعًا، ولو قللتها، هتكون أكتر دقة وثباتًا.
- لو خليت الـK=1، هيبقى الاختيار زي الـ Greedy Decoding لان هيختار الtoken الي يحمل اعلي probability.
4) Top-P (Nucleus Sampling)
ده بيختار الرموز اللي احتمالاتها الإجمالية ما بتتجاوزش قيمة معينة (P). قيمة P بتبدأ من 0 (اختيار دائمًا للرمز الأكثر احتمالًا) لحد 1 (الاختيار من كل الرموز المتاحة). كأني بقوله اي token تحت ال probability (p) تختار تختار منه بحريه
- لو عايز تبدأ بشكل متوازن بين الإبداع والدقة، جرب Temperature = 0.2، Top-P = 0.95، وTop-K = 30.
- لو عايز نتائج أكتر إبداعًا، جرب Temperature = 0.9، Top-P = 0.99، وTop-K = 40.
- لو عايز نتائج دقيقة أكتر، جرب Temperature = 0.1، Top-P = 0.9، وTop-K = 20.
- لو مهم يكون في إجابة واحدة صحيحة (زي مسألة رياضية)، خلي Temperature = 0.
عناصر الـ Prompt
- Instruction: الجزء الأساسي من الprompt , زي مثلا Summarize the following text""
- Context : معلومات إضافية بتساعد الmodel على فهم الظروف أو الخلفية الأوسع , زي مثلا "Considering the economic downturn, provide investment advice"
- data Input : المعلومات أو البيانات اللي بتدخلها عشان الmodel يشتغل عليها.
- Output indicator : بيوجه الmodel على طريقة أو نوع الرد او يتقمص دور معين "In the style of Shakespeare, rewrite the following sentence"
Prompting Techniques
نماذج ال LLMs تم تدريبها على كميات ضخمة من البيانات ومهيأة عشان تتبع التعليمات وتفهم النصوص اللي بتستقبلها، وتولد إجابات بناءً عليها. لكن النماذج دي مش دايمًا مثالية؛ علشان كده كل ما كان النص اللي بتقدمه واضح أكتر، كل ما كانت قدرة الmodel على التنبؤ بالنص المناسب أفضل.
General Prompting - Zero Shot
الmodel بياخد تعليمات مباشرة من غير ما تديله أي أمثلة على المهمة اللي المفروض ينفذها. ده بيكون مفيد لما تكون المهمة بسيطة وواضحة، لكن أحيانًا التوجيه بالطريقة دي مش بيكون كافي، خصوصًا في المهام اللي معقدة شوية.

لو الmodel مقدرش يقدّم الإجابة المطلوبة بشكل دقيق باستخدام ال zero shot، ممكن تضيف أمثلة توضيحية عشان تساعده يفهم المهمة بشكل أفضل. وده بيؤدي لفكرة One-Shot Prompting و ال Few-Shot Prompting
One-Shot Prompting
هنقدّم مثال واحد فقط للـmodel عشان يتبعه في تكملة المهمة. الفكرة هنا إن الـmodel يقدر يقلّد المثال اللي قدمته علشان يكمل المطلوب.
Few-Shot Prompting
بتقدّم للـmodel مجموعة من الأمثلة، مش مجرد مثال واحد. ده بيساعده يتعرف على النمط أو الهيكل اللي المفروض يتبعه.


عدد الأمثلة اللي تحتاجها للتوجيه بعدة أمثلة بيعتمد على:
- تعقيد المهمة: كل ما كانت المهمة معقدة أكتر، كل ما زادت الحاجة لأمثلة أكتر.
- جودة الأمثلة: الأمثلة لازم تكون واضحة وذات جودة عالية.
- قدرات ال :model بعض النماذج ممكن تحتاج أمثلة أكتر من غيرها عشان تقدر تفهم النمط.
كقاعدة عامة، من الأفضل استخدام 3 إلى 5 أمثلة في الprompt بعدة أمثلة. إذا كان المطلوب او ال prompt معقد جدًا، ممكن تحتاج تزود عدد الأمثلة.
System, Contextual and Role Prompting
هناك ثلاث تقنيات رئيسية تُستخدم لل prompt Engineering لتوليد النص بواسطة LLMs. وهم ال System Prompting وال Contextual Prompting وال.Role Prompting كل واحدة من التقنيات تركز على جوانب مختلفة في كيفية تعامل الmodel مع المطلوب منه. وهناك تقنيات اخري كالاتي:
- System prompting
- Contextual prompting
- Role prompting
- Step-back prompting
- Chain of Thought (CoT)
- Self-consistency
- Tree of Thoughts (ToT)
- ReAct (reason & act)
- Automatic Prompt Engineering
System Prompting
في النوع ده، أنا بقدم التاسك بتاعي مباشرة من غير أي إضافة. بمعنى تاني، هو بيحدد الصورة الكبيرة للي المفروض الmodel يعمله.


Contextual Prompting
هنا هنضيف سياق للكلام أو الموضوع اللي بسأل عنه، وده هيساعد الـmodel إنه يفهم التفاصيل الدقيقة ويعدل إجابته وتفكيره بناءً على السياق المُقدم.

Role Prompting
في النوع ده، بنحدد دور معين للـmodel، زي معلم أو مرشد سياحي، علشان يولّد نصوص تتناسب مع المعرفة والسلوك المتوقع من الدور ده.
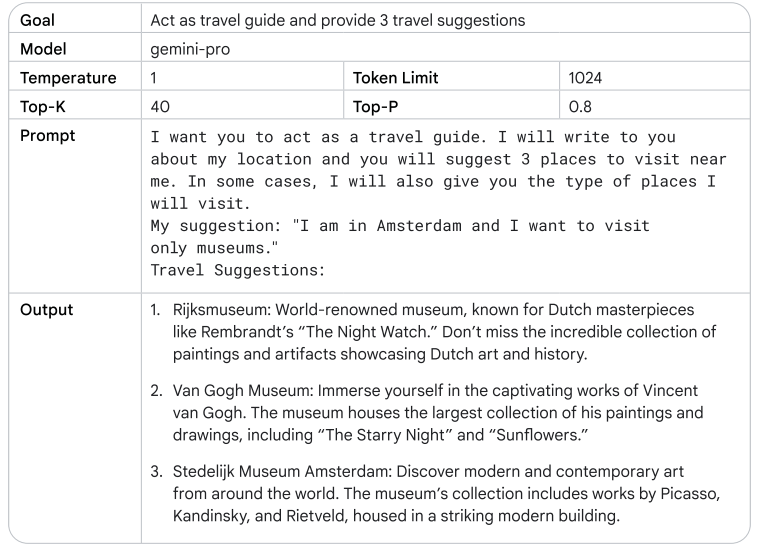
Step-back Prompting
من تقنيات تحسين أداء الLLMs، المستخدم بيبدأ بسؤال عام عن المهمة، وبعد كده يقدّم الإجابة اللي حصل عليها علشان يوجه سؤال أكثر تحديداً. الطريقة دي بتساعد الـmodel على استخدام معرفته بشكل أعمق قبل حل المشكلة.

let’s take a step back on the same task.

نرجع للسؤال الأصلي (original prompt) ، ولكن هنضيف إجابة ال step back كالسياق (context) ونرى الإجابة.

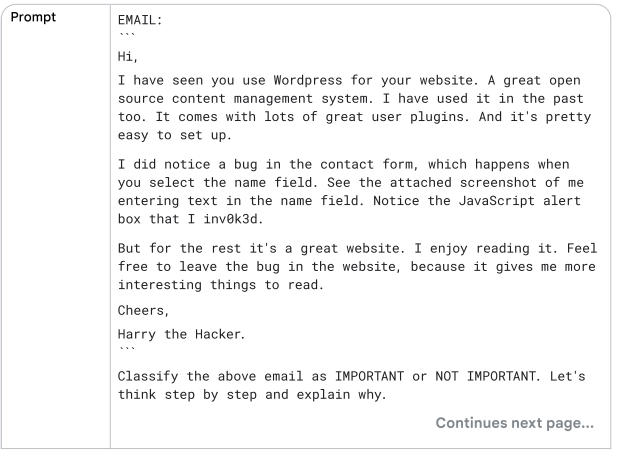
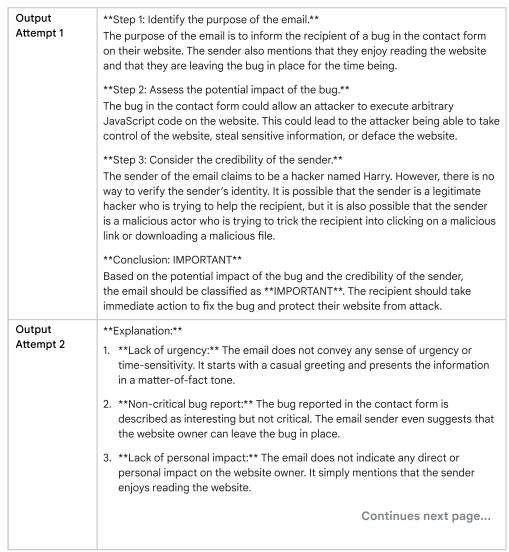
Chain of Thought (CoT)
في النوع ده، أنا بقدم للـmodel خطوات واضحة يمشي عليها، وده بيساعده يفكر بشكل منطقي أكتر. بنقسم الـprompt المعقد لـprompts أبسط، وده يعزز فهم الـmodel. ممكن كمان دمجها مع الـfew-shot prompting لزيادة كفاءة النموذج.

الجواب غير صحيح. ال LLMs غالبًا تواجه صعوبة في التعامل مع المهام الرياضية، وقد تقدم إجابات خاطئة حتى في مسائل بسيطة مثل ضرب الأرقام. والسبب هو أن النماذج تم تدريبها على كميات ضخمة من النصوص، بينما الرياضيات تتطلب نهجًا مختلفًا. كما يظهر في Table11 ، إضافة خطوات ال Chain of Thought (CoT) حسنت النتيجة بشكل واضح.

الجواب النهائي دلوقتي صحيح لأننا وجهنا الـmodel بوضوح لشرح كل خطوة بدلاً من تقديم إجابة مباشرة بالاضافه الي استخدام مثال one-shot.

Self-Consistency
هو تقنية لتحسين دقة استجابة ال LLMs عن طريق توليد عدة مسارات مختلفة ثم اختيار الإجابة الأكثر تكرارًا من هذه المسارات. يتم ذلك من خلال تكرار نفس الprompt عدة مرات مع تغييرات في Temperature ثم مقارنة الإجابات لاختيار الأكثر دقة.

Tree of Thoughts (ToT)
هي تقنية تشبه CoT ولكنها أكثر تطورًا، حيث تسمح لل LLMs باستكشاف مسارات متعددة في وقت واحد، يتم تمثيل كل مسار فكري في tree of nodes ، حيث تمثل كل node خطوة منطقية نحو حل المشكلة.
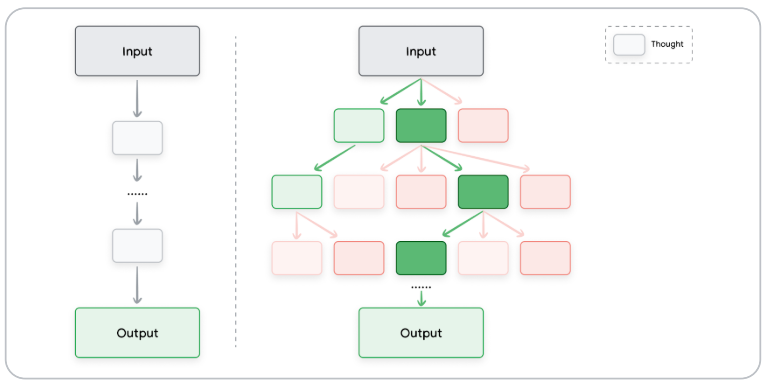
ReAct (Reason & Act)
يدمج reasoning (التفكير) مع acting (التصرف) لحل المهام المعقدة. يعتمد على فكرة أن النماذج ال LLMs يمكن أن تستفيد من أدوات خارجية (مثل ال search أو code interpreter) لتنفيذ مهام معينة. يتم ذلك عبر loopمن ال Reason & Act حيث يبدأ الmodel بالتفكير في المشكلة، ثم يحدد خطة للعمل، ومن ثم ينفذ هذه الخطة عبر أدوات خارجية، مثل إجراء بحث عبر الإنترنت، قبل أن يعيد تقييم الوضع بناءً على النتائج.
Automatic Prompt Engineering (APE)
في هذا الأسلوب، يتم تكليف الmodel بإنشاء تعليمات متنوعة لتحسين الأداء في مهمة معينة، مثل training a chatbot ليحسن قدرته على فهم وتفسير طلبات المستخدمين.

ملخص
- أكتب clear instruction ومفصله مع عدم وجود irrelevant words
- أستخدم ال delimiters الي هي التاجات (" “ # <> ```)
- علي اد مااقدر احددله يتكلم بعدد tokens اد ايه عشان ميدينش حاجه لل max token وخلاص
- (persona) Role-playing : بتطلب من الmodel أن يتصرف ككيان معين، زي المؤرخ أو العالم، علشان تحصل على ردود مخصصة. "As a nutritionist, evaluate the following diet plan"
- Iterative Refinement: هنبدا ب prompt general ومع الوقت نفضل نعلمها Refine
- Feedback Loops : استخدم كلامه الي رد بيه انك توجهه توجيه معين
- : Zero-shot Prompting الموديل ياخد تاسك عمره ماشافه قبل كده بخبر بيه هو general enough ولا مش بيعرف يتكلم ف مواضيع معينه ؟
- Few-shot Prompting/In-context Learning : توبك جديد علي الموديل بس هديله امثله shots يعني ممكن اوريله الترجمه من الماني لفرنسي في كام مثال وهو هيفهم لوحده من الكام مثال هو بيعمل ايه او لما احتاج اعلمه منطق معين لحل مسائل الرياضيات ممكن ادي كام مثال للمساله
- Chain-of-Thought CoT : هنا بقي بقوله دي الخطوات الي هتمشي عليها بيخليه قادر يفكر ف الحل بمنطقيه اكتر ودا عن طريق تقطيع ال complex prompt لprompts اسهل منها وممكن ادمجها مع الي قبلها هيعزز جدا فهم الموديل
- Referencing : زي تطبيقات ال RAG اني بديله داته ويجاوب منها علي اسئلتي
- كdeveloper :
- نقدر نخليه يعمل summarize for historical prompts
- يستخدم embedding based search
- أقدر أقوله اعمل code execution
- اقدر اخليه يعمل search on internet
- اقدر اعمل فانكشن بالكود ينفذها ف وقت معين
في الختام
يمكن القول أن الهندسة التوجيهية (Prompt Engineering) هي أداة هامة لتحسين أداء النماذج اللغوية الكبيرة (LLMs). باستخدام تقنيات مثل System Prompting وContextual Prompting وRole Prompting، يمكن توجيه النموذج بشكل دقيق لتحقيق نتائج أفضل.
كما أن إضافة خطوات Chain of Thought (CoT) يمكن أن تحسن قدرة النموذج على التعامل مع المهام المعقدة، مثل المسائل الرياضية. بالتالي، ستظل ال Prompt Engineeringجزءًا أساسيًا في تحسين أداء النماذج وتوسيع تطبيقاتها في المستقبل.
المصادر
Prompt Engineering

Understanding Prompt Engineering Course
















Discussion