

المقدمة
مٌبرمجنا الفاضل هناخدك بكوباية الشاى زي ما أنت ونسألك بعض الأسئلة في مجال الكيمياء الحيوية و هنقيم اجاباتك ( دا لو عرفت تجاوب) و في مرة ثانية هنديك كتب ومصادر تذاكر منها وتعرف أكثر عن الكيمياء الحيوية وبعديها نسألك ونقيم اجاباتك ثاني, أكيد في المرة الثانية إجابتك هتكون أحسن بكثير. اللي عملناه في المرة الثانية هو دا ال RAG اللي هنتعرف عليه النهارده فكوباية الشاي معاك وهيا بنا.
ما هي نماذج RAG ؟
نماذج RAG (توليد معزز بالاسترجاع للترجمة الحرفية ^^ - Retrieval-Augmented Generation) هي نوع من أنواع ال AI Models بتجمع بين فكرتين أساسيتين:
- الاسترجاع (Retrieval): بنقوم بالبحث عن معلومات في مصادر خارجية (مثل قاعدة بيانات أو وثائق نصية).
- التوليد (Generation): يقوم النموذج باستخدام المعلومات المُسترجعة لتوليد إجابة أو نص جديد.
ببساطة، بدلًا من أن النموذج يعتمد فقط على ما اللي اتدرب عليه (مثل GPT)، بتقوم نماذج RAG بجلب معلومات حديثة ودقيقة من مصادر خارجية وبعدين تستخدمها عشان ترد علي طلبك أو سؤالك. يعني بيذاكر وبعدين يجاوب.
أهمية وأسباب استخدام ال RAG Architecture
ال RAG Architecture بيتم استخدامها في أكثر من 60% من تطبيقات ال LLM في الشركات تبعًا لإحصاء من Databricks و دا لأن الإجابات اللي بتوفرها بتكون أدق بنسبة 40% من ال Models اللي معتمدة فقط على الـ fine tuning.
ودا بيرجع لأكثر من سبب:
- Static Datasets محدودية البيانات التي يتدرب عليها ال LLM Model: لو استخدمت LLM Model لوحده غالبًا هيبقي متدرب علي بيانات لحد سنة معينة و معندوش أي معلومات بعدها ودا بيقلل من دقة الإجابات أو يديك معلومات قديمة.
- No Local Data Access: وكذلك البيانات دي بتكون عامة لأنه ميقدرش يوصل للبيانات الخاصة بالشركات فلو سألته عن شىء/مصطلح محدد بتستخدموه في شركتكم بس غالبًا هيهلوس بأي إجابات ملهاش صلة بالموضوع.
- Hallucinations: ال LLM Models متدربة علي أنها تدي معلومات بشكل Generic أو عام لو معندهاش Context مخصص من باب "إجابة عامة ترضي الكل" ودا بيحد من استفادتنا بيها في التطبيقات الخاصة بالشركات واللي بتحتاج دراية بالسياق ومستوى أعلى من التفاصيل و في بعض .الأسئلة ممكن توصل معلومات خاطئة تمامًا أو تهلوس
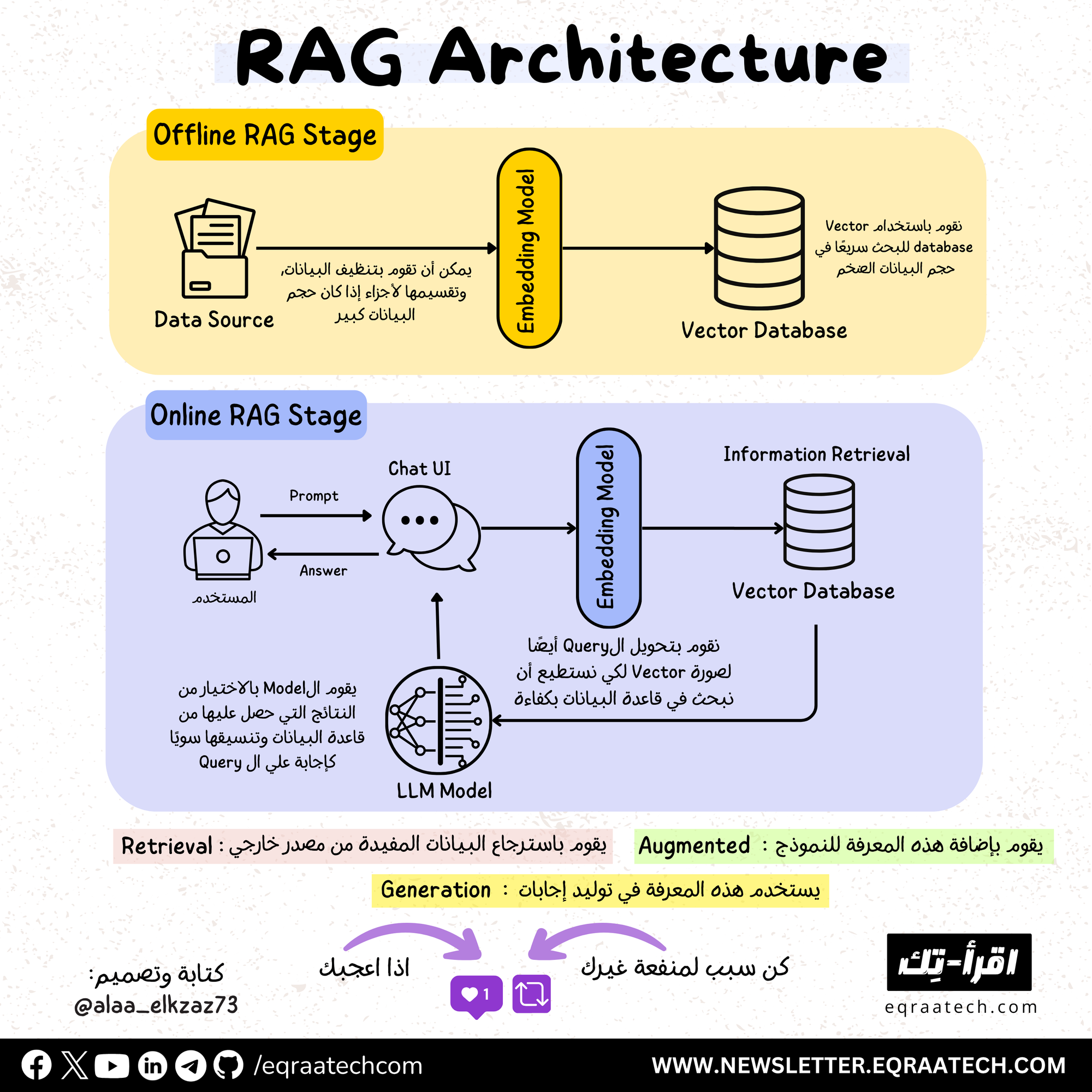
كيفية عمل RAG Application ؟
هنتكلم أولاً عن ال Offline Stage وهي إننا نقوم بتجميع البيانات من مصادر مختلفة, سواء ملفات أو APIs أو غيرها و تقسيمها لقطع Chunks و بعدين نديها لل Embedding Model اللي هيقوم بتحويلها ل Vectors ولكنه يأخذ في الاعتبار "المعنى" في طريقة تقسيمه وتحويله للبيانات.
في Embedding Models متنوعة متاحة من أشهرهم OpenAI’s text-embedding-3 و Cohere Embeddings لو حابين نعمل ورقة عن ال Embedding Models بحد ذاتها قولولنا في التعليقات لأنها بالفعل مبهرة وهي اللي بتمكن ال RAG من هضم الكمية الضخمة من البيانات والاستفادة منها بسهولة عن طريق تحويل الكلمات لأرقام و لكن بطريقة ذكية!
بنقوم بتخزين ال Vectors دي في Vector Database, ودا لأن عملية ال Retrieval ما هي إلا اسم فخم لعملية Brute-Force Search فتخيل عندك 100K ملف حابب تدور فيهم عن معلومة معينة دي هتكون عملية بطيئة فعلاً باستخدام قواعد البيانات العادية اللي هي أصلاً سيئة الأداء في ال Semantic Search. بداخل ال Vector Databases ال Vectors بتترتب أن الكلمات والمقاطع المتشابهة والمرتبطة تتخزن بجانب بعضها و نقدر نبحث عن القطع الأقرب لل Query بخوارزميات مبنية على فكرة الـ Graph search اللي أسرع بشكل كبير جدًا من الطرق العادية والميزة دي هي اللي بتخلي تطبيقات ال RAG قابلة للتوسع.
ثانيًا ال Online Stage
وقت ما المستخدم بيبعتلنا ال Query بنقوم بردو بعمل عملية Embedding عليه وتحويله كذلك ل Vector عشان نقدر بسهولة نبحث عنه في الـ Vector database ونرجع البيانات المتشابهة معاه.
بنرجع نتائج البحث دي إلى ال LLM Model واللي بيقوم باختيار الأنسب منها أو حتي جمع بعضها مع بعض واستخدامها ك Context يقدر يطلع منه إجابة مناسبة لل Query المطلوب.
أنواع ال RAG
ال RAG ما هي إلا Architecture أو Design Pattern وبالتالي تقدر تنفذ تفاصيلها بالطريقة اللي تشوفها أنسب ودا اللي أنتجلنا أنواع كتيرة منها أشهرهم:
Naive RAG
ودي الطريقة الأساسية والأسهل وبنعتمد فيها علي إننا بنجيب البيانات المتشابهة مع ال Query باستخدام طرق بسيطة زي ال Keyword Matching أو Basic Semantic Similarity ونستخدمها كما هي بلا أي تعديل كسياق ونطلع منها الإجابة.
Advanced RAG (Iterative RAG, Fusion RAG, Query-Transforming RAG)
هنتبع نفس الخطوات ولكن هنحسن في جودة تنفيذ كل خطوة ودا هيزود من دقة الإجابات
- ففي الاسترجاع Retrieval بدل ما نستخدم ال Query كما هو هنعمله Query Expansion ونضيف ليه كلمات تساعدنا في البحث عن إجابات(سياق) أدق أو حتي نعيد كتابته مرة أخرى Query-Transforming, وبدل ما نبحث مرة واحدة ونكتفي هنعمل Iterative Retrieval ونقوم بفرز وتنقيح البيانات في كل مرة عشان نلاقي الأقرب والأدق. ونقدر بعدها كمان نعمل Relevance Scoring لترتيب صلة البيانات لل Query ودا كله طبعًا هيحسن الدخل للنموذج وبالتالي يحسن الإجابة النهائية.
Agentic / Tool-Augmented RAG
هنا ال LLM بيقوم بدور AI Agent ويحدد هو طريقة ال Retrieval وتكوين السياق اللي هيطلع منه الإجابة أو حتى يعمل أكثر من Retrieval أو يجمع أكثر من طريقة مع بعض (ممكن يعمل API Calls, Documents Search وغيره) وبيطلع وقتها إجابات أدق وأحسن ولكن طبعًا دا أصعب في التنفيذ وكذلك يستهلك موارد أكبر, فمثل كل قرار في صناعة البرمجيات هي عملية Trade-offs فمدي الدقة اللي بتحتاجها والموارد المتاحة ليك هو اللي بيحدد أي نوع RAG هتبنيه.
في الختام
اتعرفنا في الورقة دي بشكل مبسط عن ال RAG فائدتها ومكوناتها وكمان بعض الأنواع المختلفة الموجودة منها , قولولنا في التعليقات لو حابين تعرفوا أكثر عن الـ Embedding أو حابين تعرفوا إيه أكثر عن الـ AI
المصادر
بالمصادر في أفكار كثيرة للتحسين من جودة تطبيقات ال RAG يٌنصح بالإطلاع عليها:















Discussion