

المقدمة
بنسمع عن ال Vector database في أي شيء ليه علاقة بال AI تقريبًا, ولكن ايه هي ال Vector database ؟ ليه أصلا بنحتاجها؟! وإيه فرقها عن قواعد البيانات التقليدية؟ ورقة وقلم ويلا بينا
ما هي الـ Vector Database؟
الـ Vector Database هي قاعدة بيانات متخصصة في تخزين وفهرسة والتعامل مع الـ Vectors.
فبدل ما بتخزَن فيها نصوص أو أرقام تقليدية، بتخزّن تمثيلات رقمية (Embeddings) للبيانات،
وبتقدر تدور فيها بناءً على “المعنى” مش “الكلمة”.
فبدل ما تبحث عن تطابق تام (exact match) زي الـ SQL، تبحث عن تشابه في المعنى (similarity search) بين المتجهات.
مثال بسيط:
لو عندك قاعدة بيانات فيها وصف منتجات، وسألتها:
“عايز منتج مناسب للسفر والشتا”
الـ Vector DB مش هتدور على الكلمات دي بالحروف،
لكن هتدور على المنتجات اللي معناها قريب من الجملة دي — زي "جاكيت مقاوم للمطر" أو "حقيبة ظهر مقاومة للمياه".
التعريف وضح لنا الفكرة العامة ولكن ما هو الـ Vector و ما هو ال Embedding ?
ما هو الـ Vector ؟
ال Vector أو المٌتجه بالعربية هو مجموعة مرتّبة من الأرقام بتمثل نقطة في مساحة (فضاء) رياضية. بمعنى أبسط، هو "قائمة أرقام Numbers Array" بتعبّر عن موقع أو اتجاه أو معنى في نظام معين.
مثلاً:
- المتجه [2, 3] بيمثل نقطة في مستوى ثنائي الأبعاد (زي محور س وص).
- المتجه [1, 0, -1] بيمثل نقطة في فضاء ثلاثي الأبعاد.
في الرياضيات، بنستخدم المتجهات عشان نمثل الاتجاهات أو السرعات. أما في مجال ال AI بنستخدمها عشان نمثل المعاني,
باختصار الـ Vector هو Array من الأرقام تمثل معنى معين.
ما هو ال Embedding ؟
الـ Embedding هو العملية اللي بتحوّل البيانات (زي نص، صورة، أو صوت) إلى Vector.
العملية دي بتخلي النموذج يفهم العلاقات بين المعاني.
فمثلاً، لو قلت “قهوة” و“بٌن”، الـ Embedding بتاعهم هيكون قريب جدًا لأن المعنى متشابه.
بالمقابل، “قهوة” و“بحر” هيبقوا بعيد جدًا في الفضاء ده لأن مافيش علاقة مباشرة بينهم.
في Embedding Models مٌخصصة لهذه العملية متاحة من أشهرهم OpenAI’s text-embedding-3 و Cohere Embeddings
لماذا نحتاج ال Vector Databases ؟
ال Vector Database بتحللنا مشكلتين كبار في عالم البحث أو ال Searching:
- البحث بالمعني والتشابه بدل البحث الحرفي :لأن قواعد البيانات العادية (زي SQL أو MongoDB) مش بتفهم المعنى، هي بتدور بالكلمة زي ما هي. لكن في تطبيقات الذكاء الاصطناعي، بنحتاج نفهم السياق والمعاني القريبة.الـ Vector DB بتخلي البحث “ذكي” — زي لما تسأل ChatGPT أو Gemini وبيفهم قصدك مش بس الكلمات.
- سرعة البحث في كميات ضخمة من البيانات : البحث بالطرق التقليدية في كميات ضخمة من البيانات ممكن ياخذ وقت طويل جدًا ويكون في النهاية غير مٌجدي لأنه زي ما قلنا بيفتقر للشعور بالمعنى أو السياق. علي عكس ال Vector DB لأنها بتستخدم ال Vectors و خوارزميات بحث قائمة على التشابه أو ال Nearest neighbour.
مقارنة بين ال VDB و ال Traditional DB
| المقارنة | قواعد البيانات التقليدية | الـ Vector Databases |
|---|---|---|
| نوع البيانات | نصوص، أرقام، تواريخ | Vectors (تمثيلات رقمية للبيانات) |
| طريقة البحث | مطابقة نصية أو شروط محددة | بحث بالمعنى (Semantic Search) |
| الاستخدام الشائع | تطبيقات الويب، الأنظمة المالية، التقارير | الذكاء الاصطناعي، البحث الدلالي، تحليل الصور والنصوص |
| أمثلة | MySQL، PostgreSQL، MongoDB | Pinecone، Milvus، Weaviate |
الاستخدامات العملية لل Vector Database
يمكن واحدة من أشهر استخدامات ال Vector DBs اللي نعرفها حاليًا هي استخدامها في تطبيقات ال RAG ولكن بعيدًا عن ال AI هي ليها استخدامات كثيرة جدًا وفي كثير من المنتجات من حوالينا ومن الأمثلة:
- Search Engines : محركات البحث بتستخدمها في إرجاع الملفات والصور والمواقع القريبة من كلمات بحث المستخدم
- Fraud Detection: بنقدر باستخدام ال VDB نحلل أنماط الاستخدام بشكل عام و نقدر نطلع نمط الاستخدام الغريب أو انماط الاستخدام المشابهة ل Frauds شوفناها من قبل
- Personalization and Recommendation Systems: سواء في ال E-Commerce أو ال Streaming Services فبنقدر نستخدم ال VDB عشان نرشح للمستخدم ترشيحات جديدة قريبة من ال Search history الخاص بيه أو علي حسب المنتجات اللي المستخدمين من نفس نوعه, فئته العمرية إلخ.. تصفحوها.
RAG Applications: في الشركات وغيره ال VDB هي اللي بتخزن بيانات الشركة بشكل ذكي عشان ال LLM Model يقدر يستخدمها كسياق يطلع منه الإجابات للمستخدمين في الشركة
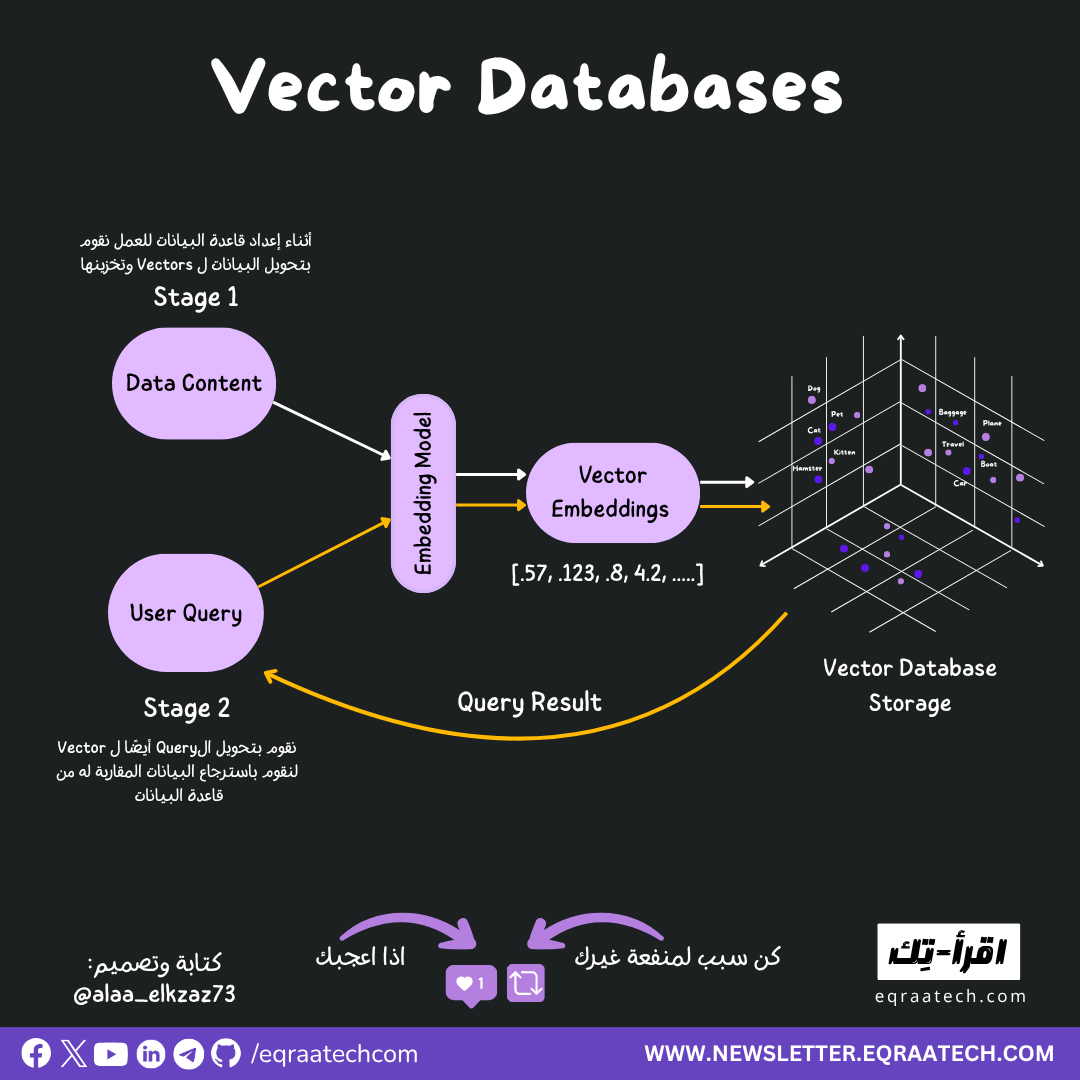
كيفية عمل الـ Vector Databases ؟
أهمية المٌتجهات بتظهر لما يكون عندي بيانات ضخمة عاوزة أبحث فيها عن بعض المعلومات ولنقل عاوزه بيانات بتتكلم عن القطط , فحولنا البيانات لأرقام لأن الكمبيوتر أسرع في التعامل مع الأرقام عن النصوص أو أي صيغة بيانات أخري. والأرقام رتبناها بحيث أن الأرقام اللي بتتكلم عن موضوع معين تكون منطقيًا قريبة من بعض وأبعد عن المواضيع الأخري. وبكدا لما أبحث عن القطط هيجبلي البيانات اللي فيها ذكر لكلمات زي "قطط", "هرة" "قطقوطة" , "حيوان أليف" وغيرها
فعلي مثال القطط ممكن بٌعد بيمثل اللون, نوع الفصيلة, الشكل,وغيرها

ما هي ال Vector Database Architecture ؟
قواعد بيانات المتجهات بتتقسم لمكونات أساسية (Core Components):
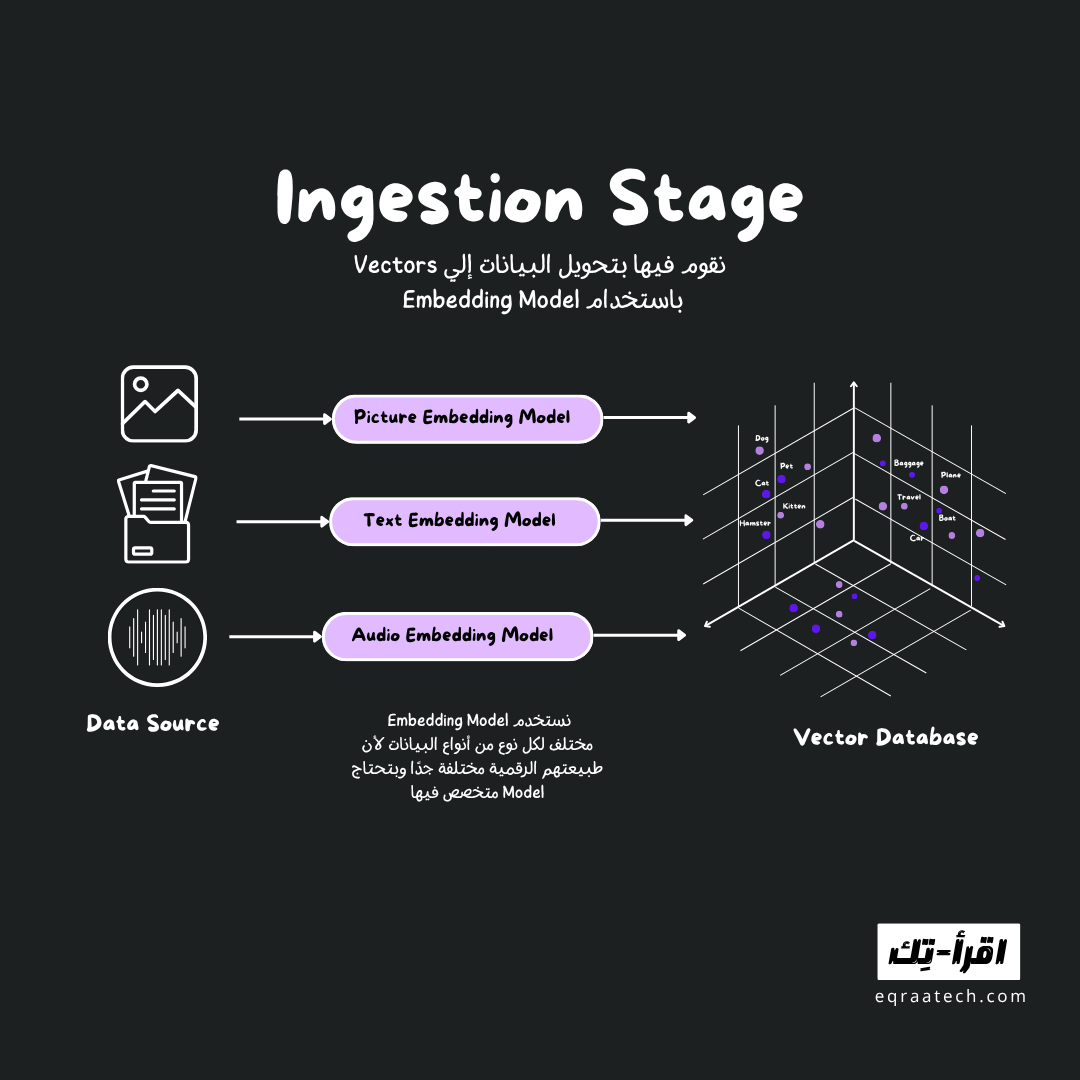
1. Data Ingestion Layer
هي الطبقة المسؤولة عن:
- استقبال البيانات الخام (نصوص، صور، إلخ)
- تحويلها إلى متجهات (embeddings) باستخدام نموذج (مثل OpenAI embeddings أو sentence transformers)
- تخزين المتجهات + ال (metadata) في النظام
مثال: "I love pizza" → [0.21, 0.73, -0.11, …]
2. Storage Layer (Vector Storage)
الطبقة التي تحتفظ بالمتجهات فعليًا في الـ + Disk Storage In-memory Storage مثل بقية قواعد البيانات
3. Indexing Layer (Vector Index)
دي أهم طبقة في الـ Vector Database هدفها هو هدف أي فهرس في العالم ألا وهو تسريع البحث عن المتجهات المتشابهة.
أشهر الخوارزميات اللي بنستخدمها في ال Indexing:
- HNSW (Hierarchical Navigable Small World Graph)
- IVF (Inverted File Index)
- PQ (Product Quantization)
- Annoy, Faiss, ScaNN
بنستخدم كل الخوارزميات دي لعمليات ANN (Approximate Nearest Neighbor Search) يعني إيجاد أقرب متجهات بسرعة دون الحاجة للمطابقة الدقيقة.
4. Query Layer (Similarity Search Engine)
لما المستخدم يبعت Query بيبحث فيه عن شيء، مثل:
"ابحث عن مقالات عن تاريخ تربية القطط كحيوان أليف"
قاعدة البيانات بتعمل الخطوات دي:
- تحويل النص إلى متجه (embedding)
- البحث عن أقرب المتجهات (nearest neighbours)
- استرجاع البيانات الأصلية (النصوص أو الصور) المرتبطة بها, لأن الفهرس Index بيخزن صورة مضغوطة أو مٌختصرة من البيانات.
5. Metadata & Filtering Layer
البيانات بتتخزن جوه ال Vector DB علي هيئة وحدات كل وحدة هي ال Vector + metadata ال metadata هي عبارة عن وصف للبيانات وبقدر استخدمها ك Filter عشان أضيق نطاق البحث بتاعي. ال Filter و ال Namespaces و ال Hybrid Searches كلها مفاهيم مهمة بتساعد في تحسين وتسريع البحث لو مهتمين نتكلم عنهم قولونا في التعليقات.
أمثلة على الـ Vector Databases المتوفرة في السوق حاليًا
- Pinecone من أشهر الحلول المتاحة بتركز على الأداء العالي وسهولة التكامل مع تطبيقات الـ RAG و الـ LLMs. منتشرة جدًا في المشاريع التجارية والـ startups لأنها مستقرة، سريعة، وسهلة الدمج مع OpenAI وLangChain.
- Weaviate قاعدة بيانات مفتوحة المصدر (Open Source) و بتدعم الHybrid Search (Hybrid Search: keyword + vector). منتشرة في الشركات التي تبني تطبيقات semantic search أو knowledge graphs لأنها قوية ومرنة جدًا.
- Milvus واحدة من أكثر القواعد كفاءة من ناحية الأداء والـ scalability،منتشرة جدًا في المشاريع البحثية والمؤسسات الكبيرة بسبب أدائها العالي.
- Qdrant قاعدة بيانات مفتوحة المصدر وسهلة التشغيل، مكتوبة بلغة Rust فأدائها سريع ومنتشرة في مجتمع الـ AI developers وRAG systems عشان سرعتها وسهولة دمجها في التطبيقات الصغيرة والمتوسطة.
Chroma كذلك قاعدة بيانات مفتوحة المصدر وتقدر تشغلها Locally على جهازك الشخصي, سهلة جدًا في الاستخدام وسريعة وعشان كدا منتشرة بين المطورين في المشاريع التجريبية والـ prototyping
في الختام
اتعرفنا في مقال اليوم عن ال Vector Databases وطريقة عملها بالتفصيل والأنواع المتاحة, اكتبولنا في التعليقات المواضيع اللي حابين نتكلم عنها في ورقة وقلم, إلى اللقاء في ورقة قادمة إن شاء الله 👋
المصادر















Discussion