الطريقة الشائعة واللي أغلبنا اتعرضلها عشان يقدر يولد Unique IDs عشان نستعملها في الـ Database ونميز الـ Rows كانت الـ UUID أو اللي بنسميه برضو GUID في منتجات Microsoft.
ورغم انها طريقة عملية جدًا لاننا نـ Generate Unique IDs الا ان الكلام ده بيجي معاه مشاكل خطيرة لما نشتغل في Scale كبير خصوصا مع الـ Performance.
ايه هو الـ UUID ؟
هو اختصار للـ Universally Unique Identifier والفرق بينه وبين الـ GUID ان اول كلمة بس هي اختصار لـ Globally.
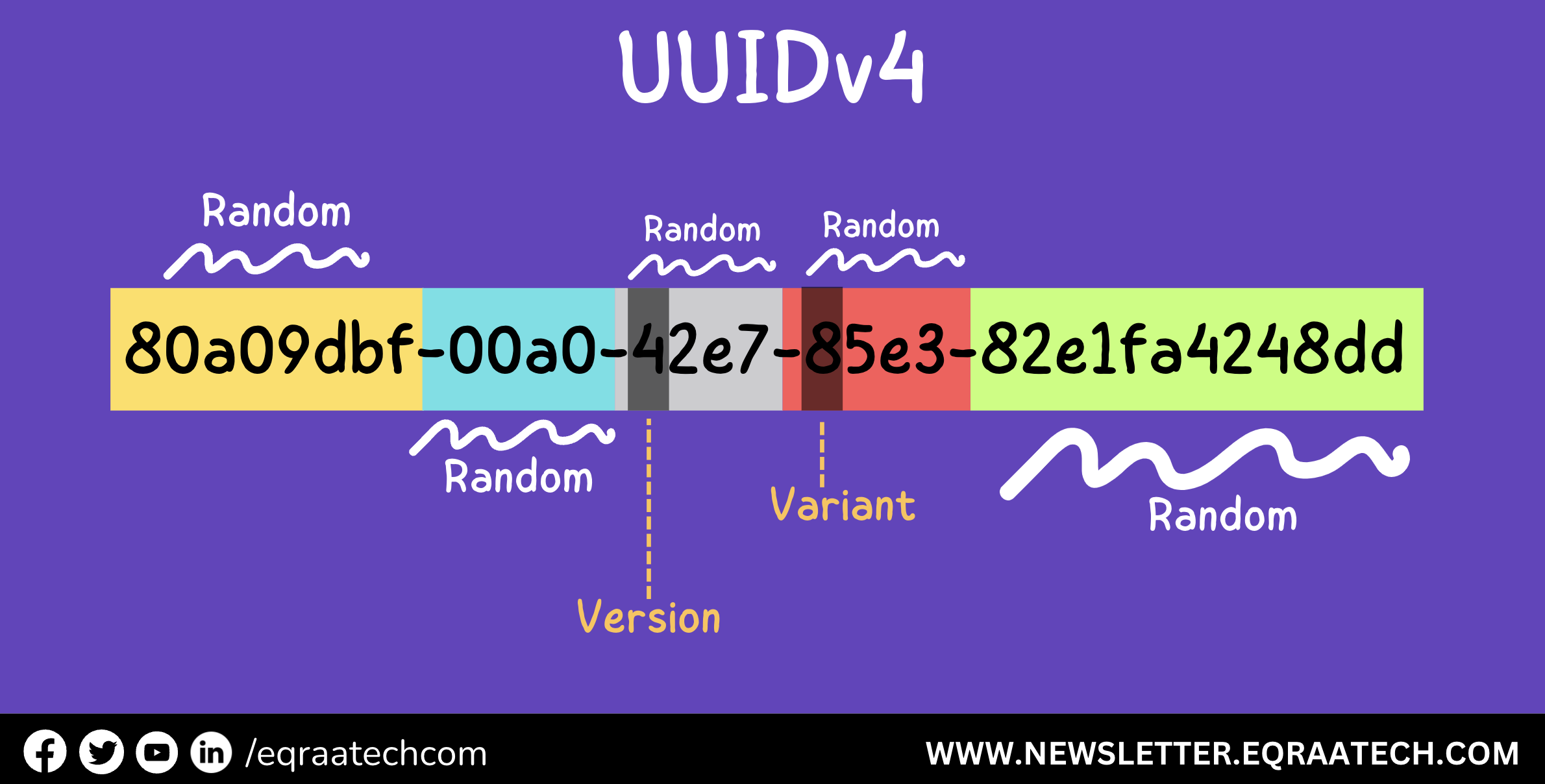
بيتكون من 128 Bit، وده بيخليه عنده قدرة إنه يولد أكتر من 340 سكستيليون (340 مع 36 صفر جنبها) ID مختلف. فيه أنواع مختلفة من الـ UUID، زي الـ UUIDv1 والـ UUIDv4، وكل نوع ليه طريقة معينة لتوليد الـ IDs.
لكن النوع الأكثر شيوعًا هو الـ UUIDv4 , وهنلاقي انه بيشتمل على رقم 4 في الـ UUID المتولد اصلا واللي بيشير للـ Version.
UUIDv4
ازاي بيحصله Generation ؟
بيعتمد على العشوائية التامة على عكس بعض الـ Versions التانية اللي بتعتمد على الـ Timestamp بالاضافة للـ MAC Address على سبيل المثال.
وبالتالي ده بيديله ميزة قوية الا وهي صعوبة تكراره وانه بيتميز بانه فريد بالاضافة لانه مش بيعتمد على أي معلومات شخصية.
تقدروا دلوقتي تشتركوا في النشرة الأسبوعية لاقرأ-تِك بشكل مجاني تمامًا عشان يجيلكوا كل جديد بشكل أسبوعي فيما يخص مواضيع متنوعة وبشروحات بسيطة وسهلة وبجودة عالية 🚀
النشرة هيكون ليها شكل جديد ومختلف عن شكلها القديم وهنحاول انها تكون مميزة ومختلفة وخليط بين المحتوى الأساسي اللي بينزل ومفاجآت تانية كتير 🎉
بما اننا عارفين ان في قواعد البيانات غالبًا الـ Clustered Index واللي بيكون على الـ Primary Key بيكون معموله Index بالـ B+ Tree Data Structure , فلكم ان تتخيلوا ازاي عملية الـ Re-Balancing هتحصل مع كل Write Operation أو بمعنى أدق Insertion عشان تزود Row جديد.
اشترك الآن بنشرة اقرأ‑تِك الأسبوعية
لا تدع أي شيء يفوتك. واحصل على أحدث المقالات المميزة مباشرة إلى بريدك الإلكتروني وبشكل مجاني!