
The Complete Guide to Full Text Search in PostgreSQL
يشرح هذا المقال تقنية Full-Text Search, وكيفية تطبيقها في Postgres, حيث يبين أن التقنية توفر نتائج بحث أكثر صلة مقارنة بطرق البحث التقليدية, وذلك من خلال فهمها للبنية اللغوية للنص
- •

مقدمة
البحث ميزة أساسية في أغلب التطبيقات, و يؤثر مباشرة على جودة المنتج وتجربة المستخدمين, حيث أن بناء نظام بحث فعّال قادر على عرض نتائج دقيقة وذات صلة أصبح ضرورة.
توجد العديد من طرق البحث, منها طرق بحث بسيطة، مثل المطابقة الدقيقة (LIKE), والتي غالبا ما تؤدي إلى نتائج محدودة، لأنها تتعامل مع النص كمجموعة أحرف, دون فهم لبنيته أو معناه، ما يحدّ من جودة النتائج.
سنتحدث في هذا المقال عن طريقة بحث تسمى بالـ Full-Text Search، حيث سنتحدث عن تعريفها, كيفية عملها, أهميتها, كيف نعدها في Postgres, كيف نعدها للتعامل مع الأخطاء الإملائية, وكيف نعدها للعمل مع النصوص العربية.
ماهو الـ (Full-Text Search (FTS؟
هي طريقة للبحث تهدف إلى إيجاد مستندات بناء على الكلمات التي تحتويها.
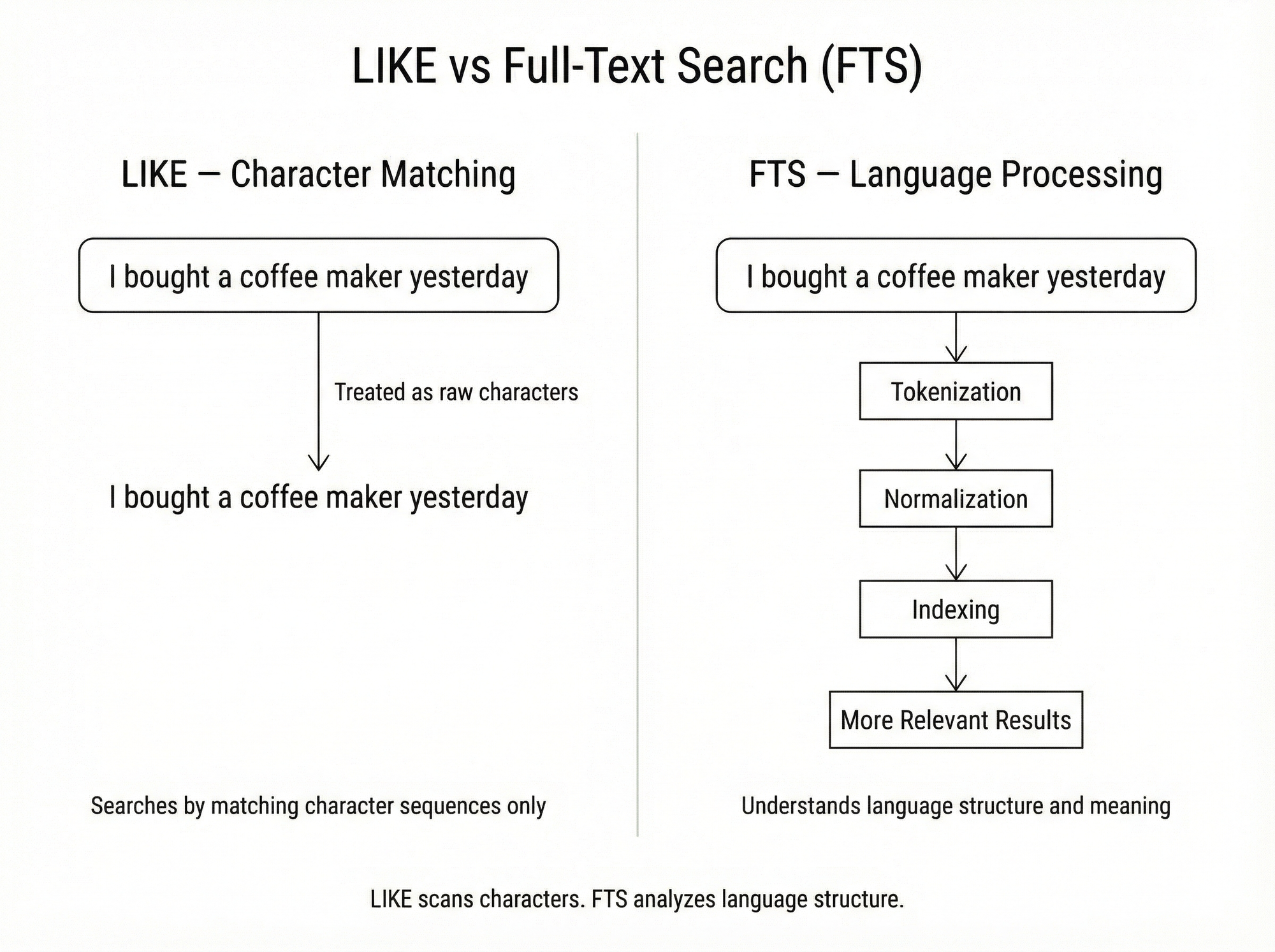
كيف تختلف هذه الطريقة عن المطابقات البسيطة "LIKE '%word"؟
تقنية المطابقة البسيطة '%LIKE '%word تعامل النص كمجموعة من الحروف, لا ككلمات لها معنى.
تضيف طريقة الـ FTS نوعا من الذكاء لعملية البحث, حيث تفهم بنية اللغة في النص, وتقوم بتحليل النص وفهرسته, مما يسمح بإرجاع نتائج أكثر صلة.
لكن, ما المقصود بـ المستند (Document)؟
كمفهوم عام, المستند هو كل نص قابل للفهرسة والبحث لاحقا.
في سياق قواعد البيانات كـ Postgres, المستند هو النص الذي يجمع خانات الصف الواحد (concatenation of row's fields)
في هذا المقال, سنستعمل مصطلحي "المستند" و "النص (Text)" كمترادفين.
والآن, دعونا نلقي نظرة حول كيفية عمل هذا النظام.
كيف يعمل الـ Full-Text Search؟
قبل التطرق لكيفية عمل الـ FTS, لنرى كيف يتم بناء أنظمة البحث بشكل عام,
أولا, كيف يتم بناء نظام للبحث؟
لبناء نظام للبحث, فالعمل مقسم إلى مرحلتين: مرحلة الفهرسة (Indexing phase), ومرحلة البحث أو الإسترجاع (Querying phase).
مرحلة الفهرسة (Indexing phase): هي المرحلة التي يقوم فيها النظام بتحليل وتنظيم البيانات التي لديه, وذلك لتحسينها وجعلها مناسبة لعملية البحث لاحقا.
مرحلة البحث (Querying phase): هي المرحلة التي يقوم النظام بمعالجة مدخلات المستخدم (كلمة البحث) وإيجاد النتائج المناسبة من داخل البيانات التي تم تنظيمها سابقا.
لنر كيف يتم تنفيذ هذه المراحل في Full-Text Search
كيف تنفذ هذه المراحل في الـ FTS ؟
أولا, مرحلة الفهرسة
في هذه المرحلة, يتم تحليل المستند أو النص, ثم إنشاء فهرس له.
1. تحليل النص (Text Analysis Pipeline): حيث يتم:
- تجزئة النص (Tokenization): يتم تقسيم النص إلى "وحدات (Tokens)" بناء على أحرف مثل المسافة (space) أو علامات الترقيم (مثل: ... ، ! ؟). مثال: "Beautiful park" تصبح ["Beautiful", "park"]
- توحيد النص (Normalization): من خلال تحويل الكلمات إلى أحرف صغيرة (Lowercasing), إزالة علامات الترقيم والكلمات غير المهمة (stopwords) مثل and, a, the, وإيجاد جذور الكلمات (Stemming) مثل: كلمات running, ran, و run لديها نفس الجذر وهو run, أي توجد علاقة بين هذه الكلمات.
2. الفهرسة (Indexing): حيث يتم إنشاء فهرس يضم الكلمات الموجودة وأماكن تواجدها. يسمى هذا الفهرس بالـ Inverted Index.
مثال للفهرس:
لنفرض أنه لدينا هذه المستندات
| ID | Text |
|---|---|
| 1 | "Planning improves time management" |
| 2 | "Time is a limited resource" |
بعد تحليل المستندات, يتم إنشاء Inverted index, و وهكذا يكون شكله:
| Term | Postings List |
|---|---|
| plan | [(1, tf=1, pos=[0])] |
| improv | [(1, tf=1, pos=[1])] |
| time | [(1, tf=1, pos=[2]), (2, tf=1, pos=[0])] |
| manag | [(1, tf=1, pos=[3])] |
| limit | [(2, tf=1, pos=[3])] |
| resourc | [(2, tf=1, pos=[4])] |
ثانيا, مرحلة البحث
عند إدخال المستخدم لكلمة البحث, يقوم النظام بـ:
معالجة طلب البحث (Query processing): عند إدخال المستخدم لـ "Managing the Time" في شريط البحث على سبيل المثال, يقوم النظام بتطبيق نفس خطوات تحليل النص, فتكون النتيجة ['manag' & 'time']
البحث في الفهرس (Inverted Index Lookup): باستعمال العبارة الناتجة, يقوم محرك البحث بإيجاد جميع المستندات التي ذكرت فيها كلمة "time" وجميع المستندات التي ذكرت فيها كلمة "manag", ثم يجد المستندات المتقاطعة (حيث يوجد كلاهما).
ترتيب النتائج (Ranking): يتم ترتيب النتائج باستعمال خوارزميات مثل الـ (BM25 (Best Matching 25 أو الـ(TF (Term Frequency.
لماذا الـ FTS مهم؟
لأنه:
- يعرض نتائج أكثر دقة: يفهم بنية اللغة, ويعرض النتائج ذات الصلة, عكس المطابقة البسيطة.
- المرونة: قادر على استخراج جذور الكلمات, وإيجاد مرادفات الكلمات والعبارات.
- الأداء الجيد: يبحث بكفاءة في النصوص كبيرة الحجم, وذلك باستعمال الفهارس (Inverted Indexes).
أين يُستعمل؟
يستعمل الـ FTS في:
- محركات البحث (Search engines): حيث يمكنك إعداد الـ FTS للبحث في مستندات التطبيق.
- أنظمة إدارة المواقع (Content Management System): استعمال FTS للبحث في المقالات أو التعليقات أو أوصاف المنتجات.
- روبوتات المحادثة (Chatbots): يمكن للـ FTS إيجاد الفقرات ذات الصلة للإجابة.
والآن, سننتقل إلى الجزء العملي
كيف نُعِد الـ Full-Text Search في Postgres؟
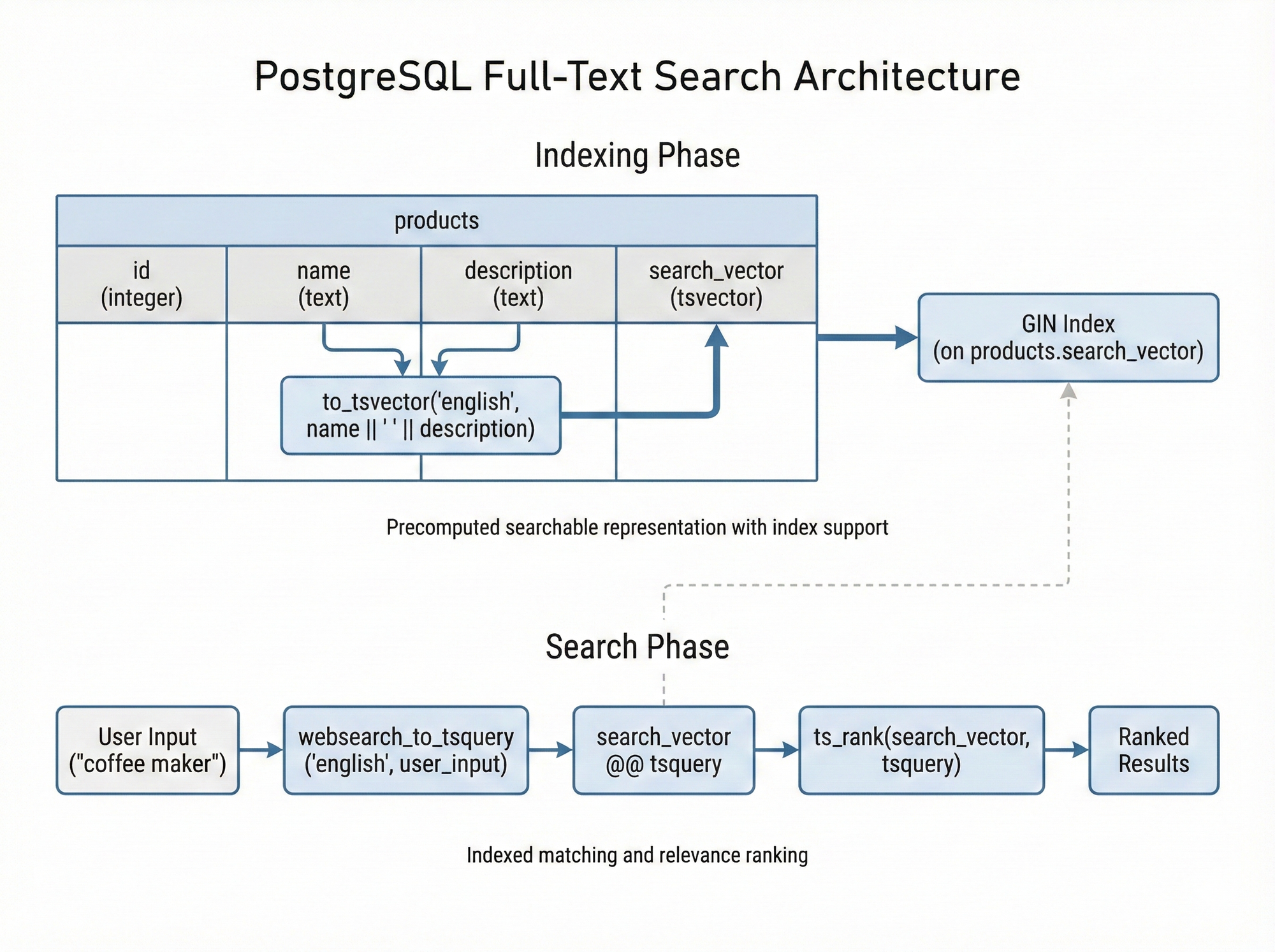
في مرحلة الفهرسة
سنقوم بـ:
- إنشاء عمود للبحث (Column Creation): قم بإضافة عمود للبحث من نوع tsvector لتخزين الـ Text Search Vectors
- إنشاء الـ Vectors: قم بملئ العمود باستعمال دالة ( to_tsvector(language, text. يمكنك دمج نصوص عدة أعمدة في عمود البحث مثل (name, description, ...).
هذا كود sql يقوم بالخطوة 1 و2:
-- Adding the search_vector column that combines name and description
ALTER TABLE products
ADD COLUMN search_vector tsvector
GENERATED ALWAYS AS (
to_tsvector('english', coalesce(name, '')) ||
to_tsvector('english', coalesce(description, ''))
) STORED;- الفهرسة (Indexing): قم بإنشاء فهرس من نوع GIN (Generalized Inverted Index) لعمود البحث.
هذا كود sql يقوم بهذه الخطوة:
-- Create a GIN index on our new vector column
CREATE INDEX idx_products_search ON products USING GIN (search_vector);في مرحلة البحث
سنقوم بـ:
- البحث (Querying): باستخدام رمز المطابقة @@ (Matching Operator) لمقارنة مدخلات المستخدم (كلمة البحث) مع الـvectors المفهرسة.
- الترتيب (Ranking): استعمل دوال مثل ts_rank أو ts_rank_cd لترتيب النتائج وعرض العناصر الأكثر صلة أولا. تعمل هذه الدوال بخوارزمية الـ (TF (Term-Frequency.
هذا كود sql يقوم بهاتين بالخطوتين:
-- Search for "waterproof speaker" and rank the results
SELECT
name,
description,
ts_rank(search_vector, query) AS relevance_score
FROM
products,
websearch_to_tsquery('english', 'waterproof speaker') AS query
WHERE
search_vector @@ query
ORDER BY
relevance_score DESC;بعد إتمام هذه المراحل, ينبغي أن يكون الـ FTS يعمل جيدا.
لكن ماذا لو أن كلمة البحث التي أدخلها المستخدم تحتوي على خطأ إملائي؟
هنا تظهر إحدى نقائص الـ FTS التقليدي، مما يدفعنا إلى البحث عن آلية تجعله يتعامل مع الأخطاء الإملائية.
كيف نعد الـ Full-Text Search ليكون متسامحا مع الأخطاء الإملائية (Fuzzy FTS)؟
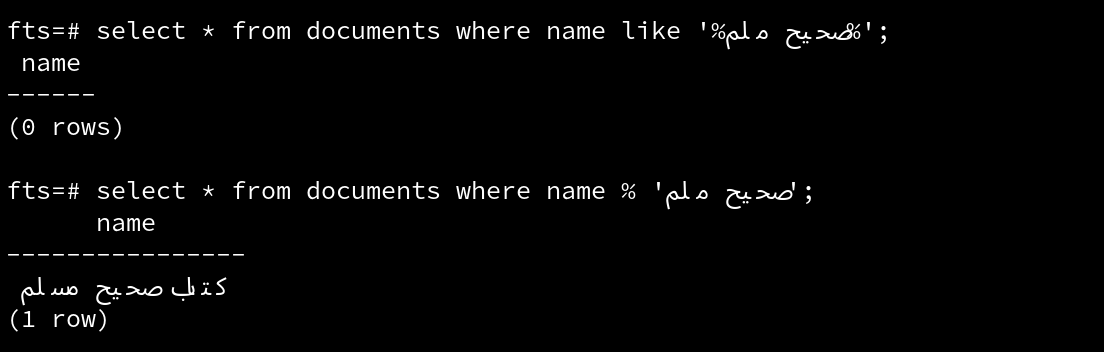
الـ FTS في Postgres ليس مصمما للتعامل مع الأخطاء الإملائية التي قد تكون في كلمة البحث, حيث أنه في النهاية بعد القيام بتوحيد النص (Normalization), يقوم بعمل مطابقة دقيقة (exact match) بين النص الناتج والنص المخزن سابقا.
توفر Postgres مجموعة من الإضافات (extensions) التي تقوم بإيجاد الكلمات القريبة من الكلمة المدخلة (approximate match), وذلك للتعامل مع الأخطاء الإملائية. من هذه الإضافات:
- pg_trgm
- fuzzysearch (levenshtein distance, phonetic matching)
سنقوم في هذا الشرح بإعداد pg_trgm مع FTS للتعامل مع الأخطاء.
الخطوات
أولا, قم بتثبيت إضافة pg_trgm:
CREATE EXTENSION IF NOT EXISTS pg_trgm;في مرحلة الفهرسة:
- قم بانشاء جدول يدعم الـ FTS (كما تم شرحه سابقا)
- قم بانشاء جدول يحوي جميع الكلمات الموجودة في الجدول الذي تريد البحث فيه (Lookup Table), مع إنشاء فهرس (Index) لتسريع عملية البحث لاحقا.
-- Create the Lookup table
CREATE TABLE words AS
SELECT word
FROM ts_stat(
$$SELECT to_tsvector('simple', content) FROM documents$$
);
-- Create the index
CREATE INDEX words_idx ON words USING GIN (word gin_trgm_ops);في مرحلة البحث:
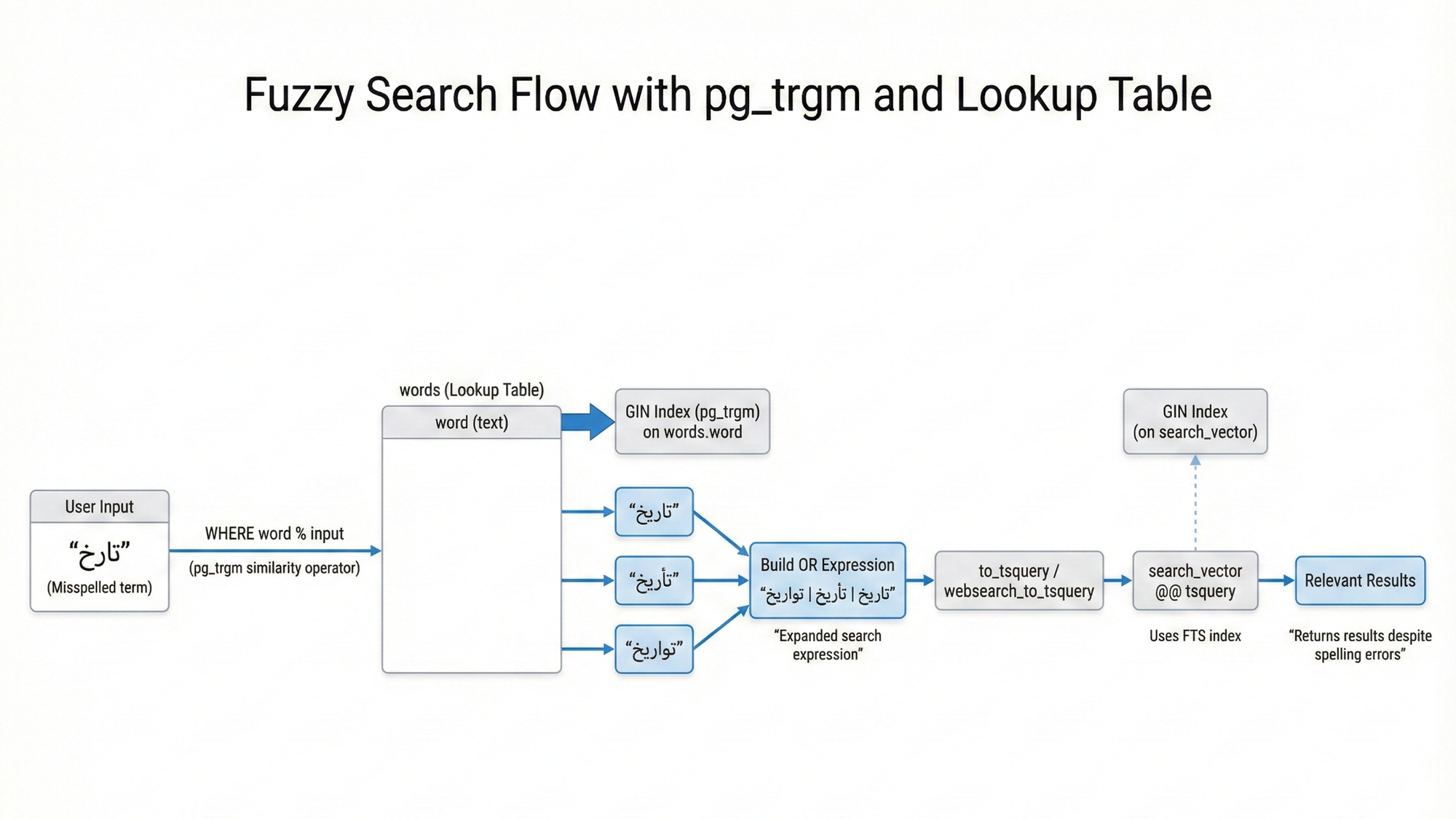
عند إدخال المستخدم لكلمة بحث تحوي أخطاء (مثال: تارخ الجزائر) يتم:
- تقسيم الجملة إلى وحدات (Tokens), فتصبح: ["تارخ", "الجزائر"]
- إيجاد الكلمات القريبة من كل كلمة مذكورة باستعمال جدول البحث الذي تم إنشاؤه سابقا.
- دمج الكلمات القريبة باستعمال الـ OR Operator | فتكون النتيجة على سبيل المثال: تارخ | تاريخ | تأريخ | تواريخ | الجزائر
- ثم يتم تشغيل أمر البحث باستعمال العبارة الناتجة مع ترتيب النتائج كما في الحالة العادية.
هذا كود sql يقوم بكل خطوات مرحلة البحث:
WITH input_terms AS (
SELECT unnest(string_to_array(
lower(''),
' '
)) AS term
),
similar_terms AS (
SELECT i.term,
w.word
FROM input_terms i
JOIN words w
ON w.word % i.term
),
grouped AS (
SELECT term,
string_agg(word, ' | ') AS alternatives
FROM similar_terms
GROUP BY term
),
query_string AS (
SELECT string_agg(
'(' || alternatives || ')',
' & '
) AS query
FROM grouped
)
SELECT
d.*,
ts_rank(d.fts_vector, to_tsquery('english', q.query)) AS rank
FROM documents d, query_string q
WHERE d.fts_vector @@ to_tsquery('english', q.query)
ORDER BY rank DESC;وهكذا يصبح الـ FTS قادرا على التعامل مع الأخطاء الإملائية !
في ماسبق, رأينا أن الـ FTS يعمل جيدا, خصوصا مع النصوص الإنجليزية, لكن كيف نجعله يتعامل مع لغات أخرى مثل العربية؟
كيف نعد الـ Full-Text Search ليعمل مع النصوص العربية؟
تم تصميم الـ Full-Text Search في Postgres ليكون محايدا ومتوافقا مع جميع اللغات, حيث يمكن إضافة دعم لأي لغة من خلال الـ Text Search Configuration.
كل لغة في Postgres يتم التعامل معها كـ Configuration, كل Configuration لديها مجزئ للنص (Parser) ومجموعة من الـ Dictionaries لتوحيد النص (Normalization).
لمعرفة اللغات المدعومة بشكل أساسي في Postgres, قم بتشغيل هذا الأمر
SELECT cfgname FROM pg_ts_config;ستظهر اللغة العربية, ولكن الـ Dictionaries المستعملة لتوحيد النص فيها بسيطة (Simple Dictionary), ولا تفهم بنية اللغة بشكل صحيح, مما يؤدي إلى نتائج خاطئة أو غير مرغوبة.
لحظة, ماهو الـ Dictionary؟
هو برنامج يقوم بتحويل الوحدات الناتجة من مجزئ النص (Tokens) إلى وحدة لغوية موحدة (lexeme).
الهدف دائما هو توحيد النص (Normalization).
الـConfiguration قد يكون لديها العديد من الـ Dictionaries, كل Dictionary يقوم بعمل معين (مثل تحويل النص إلى أحرف صغيرة, إيجاد جذور الكلمات, إيجاد مرادفات الكلمات, إيجاد مرادفات الجمل, ...)
ما أنواع الـ Dictionaries الموجودة في Postgres؟
- الـ Simple Dictionary: يقوم فقط بتوحيد الأحرف الكبيرة والصغيرة (case normalization)
- الـIspell Dictionary: يستخدم ملفات من نوع ispell لفهم بنية اللغة.
- الـ Snowball Dictionary: يستخدم خوارزمية Snowball لاستخراج جذور الكلمات.
- الـ Synonyms Dictionary: يستخدم ملفات لاستبدال الكلمة بمرادفها.
- الـ Thesaurus Dictionary: يقوم باستبدال عدة كلمات في العبارة بمرادف أو مرادفات, ولديه قواعد استبدال أكثر تعقيدا من الـ Synonyms Dictionary.
هل توجد Dictionaries خاصة العربية, والتي يمكن استخدامها في Postgres؟
يمكن استعمال الـ hunspell dictionary للغة العربية, والذي توفره مجموعة LibreOffice.
يمكن استعمال قائمة الكلمات المستبعدة من الفهرسة (Stopwords) الموجودة في Arabic Stop Words | Github.
كما يمكن استعمال Synonyms dataset الموجودة في Sinlab Synonyms | Github, مع إعادة تنظيمها بشكل مناسب لـ Postgres.
كيف نعد الـ Dictionaries العربية في Postgres؟
سنقوم باستعمال الـ Arabic hunspell كـ Ispell dictionary, ونستعمل قائمة الـ Stopwords.
- قم بتحميل ملفات ar.aff و ar.dic من مستودع LibreOffice, وملف list.txt من مستودع Arabic Stop Words.
- قم بنقل الملفات إلى مجلد Postgres مع استبدال أسماء الملفات وصيغتها لتناسب بنية الـ Ispell
cp ./ar.aff /usr/share/postgresql/<your-version>/tsearch_data/ar.affix
cp ./ar.dic /usr/share/postgresql/<your-version>/tsearch_data/ar.dict
cp ./list.txt /usr/share/postgresql/<your-version>/tsearch_data/ar.stop- لإعداد الـ dictionaries في Postgres, قم بتشغيل الأمر
CREATE TEXT SEARCH DICTIONARY arabic_hunspell (
TEMPLATE = ispell,
DictFile = ar,
AffFile = ar,
StopWords = ar
);
CREATE TEXT SEARCH CONFIGURATION public.arabic (
COPY = pg_catalog.english
);
ALTER TEXT SEARCH CONFIGURATION arabic
ALTER MAPPING
FOR asciiword, asciihword, hword_asciipart, word, hword, hword_part
WITH
arabic_hunspell;- للتحقق من عمل الـ arabic dictionaries
SELECT ts_debug('arabic', 'كتب');
Output
(word,"Word, all letters",كتب,{arabic_hunspell},arabic_hunspell, ..
SELECT websearch_to_tsquery('arabic', 'قل إن صلاتي ونسكي ومحياي ومماتي لله');
Output
'قل' & 'صلاة' & ( 'نسك' | 'نسكة' | 'نسكا' | 'نسك' | 'نسكة' | 'نسك' | 'نسكا' | 'نسك' | 'نسكة' | 'نسكا' | 'نسك' ) & 'محيا' & 'ممات' & ( 'لله' | 'الله' | 'اله' | 'لهي' | 'لهي' | 'لهي' | 'لهي' | 'الهي' | 'الله' | 'اله' | 'الله' | 'اله' | 'الله' | 'اله' | 'الله' | 'اله' | 'الله' | 'اله' | 'الله' | 'اله' )الـ dictionaries تعمل جيدا.
ختاما, سنعرض أفضل الممارسات لاستعمال FTS مع عرض بعض من النقائص الموجودة فيه.
أفضل الممارسات (Best Practices)
- تأكد أن عملية توحيد النص (Normalization) هي نفسها في مرحلة الفهرسة ومرحلة البحث.
- قم بإضافة ميزة Fuzzy search إذا كان تصحيح الأخطاء مطلوبا في محرك البحث.
- تأكد أن الـ Configuration الخاص باللغة المستهدفة يحوي الـ dictionaries التي أنت يحاجة إليها.
النقائص
- لا يعتبر الـ FTS بحثا دلاليا, حيث أنه لا يفهم المعنى وراء الكلمات الموحدة الناتجة (مثل car != automobile إلا في حالة استعمال synonyms dictionary).
- لا يوجد دعم تلقائي لتصحيح الأخطاء الإملائية في FTS Postgres, عكس بعض نظم البحث الأخرى التي توفره تلقائيا مثل elasticsearch.
- عمل الـ FTS في Postgres معتمد على اللغة و الـ Configuration الخاص بها, لذا يجب عليك إختيار الـ Configuration المناسبة.
في الختام
في الختام، تمثل تقنية FTS في PostgreSQL حلاً فعالا لتجاوز قيود طرق البحث التقليدية.
لقد أوضحنا كيف تعمل هذه التقنية, وبيّنا أهميتها في تقديم نتائج دقيقة وذات صلة بفضل فهمها لبنية اللغة. كما قدّمنا حلولاً لتعزيز كفاءته، كالتسامح مع الأخطاء الإملائية ودعم اللغة العربية.
إن بناء نظام بحث فعال شيئ ضروري لضمان منتج جيد وتجربة مستخدم جيدة.
المصادر
Postgres Docs Chapter 12. Full Text Search



















Discussion