

المقدمة
في المقالة دى، هنركّز على الجانب العملي من Prompt Engineering، وهنعرف مع بعض إزاي نصيغ prompts بشكل يضمن لنا أفضل نتائج من LLMs.
مش مطلوب يكون عندك خلفية كبيرة في ال Techniques، لكن لو كنت اطلعت على المقالة السابقة عن أساسيات Prompt Engineering:
Comprehensive Guide Into Prompt Engineering
هيكون عندك نظرة أعمق تخليك تستفيد من الأمثلة هنا بشكل أكبر. المهم إنك تعرف إن كل مثال عملي هنا مبني على شرح تفصيلي تم تناوله في المقالة السابقة، علشان كده هنقدر نخوض في الجانب العملي مباشرة.
فرصة تكسب 6,000 جنيه لو شغال بالـ AI
دلوقتي عندك فرصة تبهرنا بأفكارك 💡 وتدخل عالم الـ AI حتى لو مش AI Engineer! كل اللي محتاجه إنك تتعلم Flowise AI وتبني Agents تناسب ثقافتنا واحتياجاتنا 💬.
أمثلة بسيطة:
- لخدمة القرآن الكريم أو الحديث الشريف.
- مساعدة الأمهات في التعليم وتلخيص شغل جروب الماميز.
- تسهيل تجهيزات الجواز: "عفشك منين؟ جهازك منين؟".
- صيانة السيارات بأسلوب عملي وسريع.
- التخطيط المالي وتقييم القرارات بطريقة ذكية.
ودي مجرد أمثلة! تقدر تبدع أكتر في حاجات تساعد ناس تانية في Industries مختلفة.
الجوائز المميزة 💰
- جايزة لأحسن Agent من وجهة نظر لجنة الحكام. 🏆
- جايزة لأكتر شخص هيبعت Agents عدّت شروط التقييم. 🎯
- جايزة لأكتر Agent خد Votes من الكوميونتي بتاعتنا. ❤️
هتشتغل على تاسكات مميزة 💻، تنافس ناس زيك 🤝، تبني خبرة قوية 📚، وتضيف إنجازات لمحفظتك 💼.
متفوتش الفرصة دي! سجل دلوقتي🚀

الادوات المستخدمة (Tools)
جميع التمارين معتمدة على Gemini API من خلال Python SDK. يمكن أيضًا الوصول إلى كل ال prompts مباشرة في Google AI Studio.
- Gemini Developer API
- AI Studio: الخدمة دي متاحة مجانًا، وكل اللي هتحتاجه هو حساب Google علشان تسجل الدخول وتبدأ. كمان متكاملة بشكل قوي مع Gemini API، وفيها فئة مجانية (free tier) تخليك تشغّل الأكواد في التدريبات دي بدون أي تكلفة.
- Python SDK
Setup
Create Conda Environment
لما نشتغل على مشاريع بتحتاج مكتبات أو أدوات خاصة، لازم نعمل بيئة معزولة علشان نتجنب أي تعارض بين المكتبات (versioning conflict). بإستخدام Conda، نقدر نخلق بيئة مستقلة تحتوي بس على الأدوات والمكتبات اللي هنحتاجها في المشروع بتاعنا.
ولكن هل هذا مقتصر على مشاريع ال LLMs فقط؟
لا، الخطوة دي مش مقتصرة على مشاريع الـ LLM بس. هي مهمة في أي مشروع برمجي بنحتاج فيه نعمل إدارة لبيئات وبرمجيات مختلفة.
خطوات عمل conda environment؟
بالطبع، لازم يكون Anacondaأو Miniconda مثبتين على جهازك علشان تقدر تنشئ virtual environment. عشان كده، يفضل تحميل (Download) واحدة منهم قبل ما تبدأ، وبعد كده اتبع الخطوات التالية:
# Step 0: In your directory create requirements.txt file
# to store all the needed dependencies with their versions
# for your project we need only this ---> google-generativeai>=0.8.3
# Step 1: Create a new conda environment with a specific name and Python version
conda create --name myenv python=3.8
# Step 2: Activate the newly created environment
conda activate myenv
# Step 3: Install necessary dependencies for your project
conda install -r requirements.txt Generate the API Key
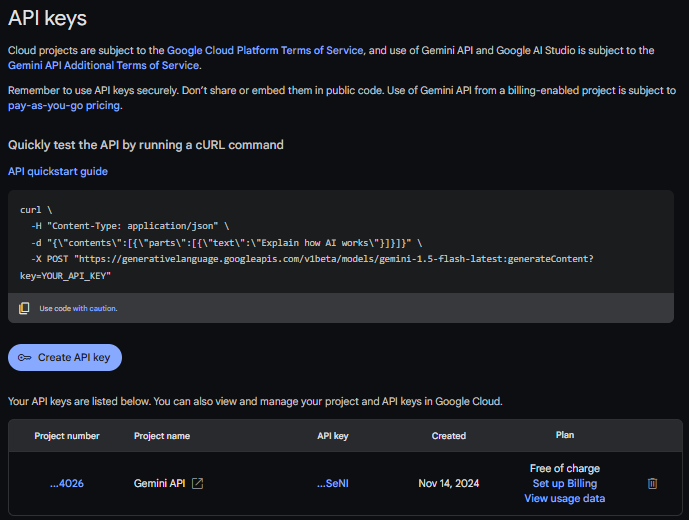
عشان تحصل علي ال API Key من Google AI Studio اتبع الخطوات التالية:
- اضغط علي الرابط دا Google AI Studio API Key .
- تأكد من تسجيل الدخول باستخدام حساب Google.
- ابحث عن Generate API Key.
- احفظ API Key في environment variable
Setup API Key (Environment Variables)
لو عندنا معلومات حساسة او secrets زي مثلا ال API key وبيتم استخدامها في برنامجك طول الوقت، يبقى لازم تخزنها في مكان خاص اسمه environment variables. عشان تكون الـ keys دي موجودة دايما لما تفتح بيئة العمل بتاعتك (conda environment)، ممكن تعمل ملف صغير يجهزلك الـ keys دي لوحده كل ما تفتح البيئة. عشان تعمل كده، هتكتب أوامر معينة في مكان اسمه terminal:
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
echo 'export GOOGLE_API_KEY="YOUR_API_KEY_HERE"' > $CONDA_PREFIX/etc/conda/activate.d/env_vars.shاستبدل "YOUR_API_KEY_HERE" بمفتاح الـ API الفعلي الذي أنشأته من Google AI Studio API Key.
كده احنا ضمنا إن مفتاح الـ GOOGLE_API_KEY هيتم تعيينه طول مانا مفعل ال environment. للتاكد من ان ال API مسجل في ال environment يمكن كتابه هذا الامر في ال terminal بعد عمل Activation للenvironment.
echo $GOOGLE_API_KEYتجربة Google API
هنستعرض هنا بعض التجارب العملية -بإستخدام -python codeاللي تقدر تطبقها بنفسك عشان تستكشف ال API . الأمثلة دي هتساعدك تتأكد إن كل حاجة جاهزة ومُعدّة بشكل صحيح عشان تبدأ في استخدام Gemini
First Prompt to Test API
في الخطوة دي، هنتأكد إن الـ API Key شغال صح من خلال إرسال request لنموذج Gemini. أيضا بستخدم Markdown Function بدلا من print لتوضيح الخرج وسهوله قراءته.
test = genai.GenerativeModel('gemini-1.5-flash')
response = test.generate_content("ُاشرحلي الذكاء الاصطناعي وكأني طفل")
Markdown(response.text)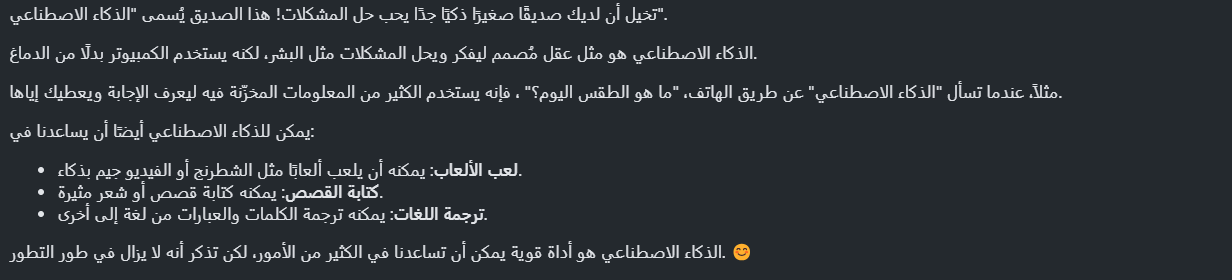
Start a Chat
المثال اللي فات كان مجرد نص واحد داخل وخارج، لكن ممكن كمان تعمل محادثة مستمره مع الAPI.
chat = test.start_chat(history=[])
response = chat.send_message('أهلا! انا هبة')
Markdown(response.text)
response = chat.send_message('قولي اي حاجه فنيه ممكن الذكاء الاصطناعي يشارك فيها لانى بحب الفنون')
Markdown(response.text)
خلال وجودك على كائن الـ chat، هتفضل المحادثة مستمرة. جرب كده واسأل النموذج لو فاكر اسمك.
response = chat.send_message('فاكر اسمي؟')
Markdown(response.text)
response = chat.send_message(' انا بحب ايه؟')
Markdown(response.text)
طبعا ممكن يبقي مش عارف انت بتحب ايه لان مقولتش بشكل مباشر. ممكن نماذج اخري تعرف تستخلصها من النص لوحدها بشكل افضل من gemini-1.5-flash
Choose a Model
الـ Gemini API بيقدم مجموعة من النماذج اللي ممكن تستخدمها. تقدر تعرف أكتر عن النماذج المتاحة من خلال صفحة نظرة عامة على النماذج من هنا. أو إستخدم الـ API علشان تعرض كل النماذج المتاحة:
list(model.name for model in genai.list_models())
الاجابة هتحتوي على أسماء جميع النماذج الخاصه ب Gemini API.
Explore Generation Parameters
Output Length
عند توليد النصوص باستخدام LLM، يؤثر طول الناتج على الcost و latency . زيادة عدد ال tokens تزيد من استهلاك الطاقة وتزيد من الوقت والتكلفة. علشان تتحكم في طول النص الناتج، تقدر تحدد قيمة max_output_length عند استخدام Gemini API، وده هيوقف الرد عند حد معين من الtokens بدون ما يؤثر على أسلوب أو شكل النص.
Configs = genai.GenerationConfig(max_output_tokens=200)
limit_output_model = genai.GenerativeModel(
'gemini-1.5-flash',
generation_config=Configs)
response = limit_output_model.generate_content('أكتب مقاله من الف كلمه عن إقرأ-تيك https://eqraatech.com/')
Markdown(response.text)
تنبيه: ممكن يظهر بعض الهلوسة ودا بسبب ان منصة اقرأ-تك جديدة فالنموذج بيألف من دماغه لو جربت تسأل اي سؤال تاني هنلاقي أن الإجابة مش هتتاثر خالص ولكن هتوقف اول ماعدد ال tokens يخلص. جرب تعمل طلبات مختلفة مع max_output_length متنوعة، وعدّل الـprompt للاستكشاف.
response = limit_output_model.generate_content(" أكتب قصيده باللكنه المصريه ذات قافيه في مدح إقرأ-تيك")
Markdown(response.text)
Temperature
الـ Temperature بتتحكم في مستوى العشوائية في اختيار الtokens. الـ Temperature العالية بتنتج اختيارات أكتر وعشوائية، الـ Temperature المنخفضة بتكون أكثر تماسكًا، يعني إذا كانت 0، هتختار الرموز الأكثر احتمالًا.
import time
high_temp_model = genai.GenerativeModel(
'gemini-1.5-flash',
generation_config=genai.GenerationConfig(temperature=2.0))
for _ in range(10):
response = high_temp_model.generate_content('أختر لون عشوائي... (قم باختيار كلمة واحده فقط)')
if response.parts:
print(response.text)
# Slow down a bit so we don't get Resource Exhausted errors.
time.sleep(10)
high_temp_model = genai.GenerativeModel(
'gemini-1.5-flash',
generation_config=genai.GenerationConfig(temperature=0.0))
for _ in range(10):
response = high_temp_model.generate_content('أختر لون عشوائي... (قم باختيار كلمة واحده فقط)')
if response.parts:
print(response.text)
# Slow down a bit so we don't get Resource Exhausted errors.
time.sleep(10)هنلاحظ فعلا ان في تنوع في المخرجات لما كانت ال temp كبيره كانت الالوان كلها واحده (اختار نفس الكلمه كل مره) علي عكس لما كانت ال temp صغيرة كان في تنوع في الكلمات المختاره واستخدم الوان مختلفه وحتي الوان مش basic.
Top-K and Top-P
زي الـ Temperature، الـ Top-K و Top-P بيتحكموا في تنوع النص الناتج.
- Top-K بيحدد عدد الرموز الأعلى احتمالًا اللي ممكن يختار منها النموذج.
- Top-P بيحدد الحد الأدنى للcumulative probabilities اللي لو تخطاه، بيتوقف عن اختيار ال tokens.
في الكود التالي قم بتغير قيم ال hyperparameters لتوضيح تاثير كل منهم:
model = genai.GenerativeModel(
'gemini-1.5-flash-001',
generation_config=genai.GenerationConfig(
# These are the default values for gemini-1.5-flash-001.
temperature=1.0,
top_k=64,
top_p=0.95,
))
story_prompt = "قم بكتابه قصه عن قط أبيض ذو شخصيه قويه وقلب طيب يتجول في انحاء مصر"
response = model.generate_content(story_prompt)
Markdown(response.text)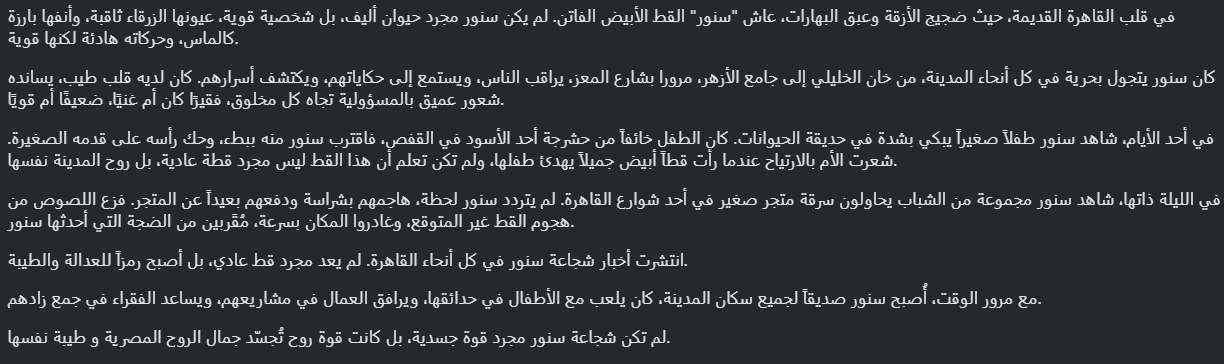
Prompting
هنا هنستعرض بعض الtechniques المختلفه في كتابه ال prompt الموجهه لل LLM. جرّب تغيير النص علشان تشوف إزاي ال prompt بيؤثر على الأداء و الإستجابة.
Zero-Shot
الـZero-shot prompts هي ال prompt اللي بتوصف المهمة للنموذج مباشرة بدون أي أمثلة سابقة. تقدر ترجع لل prompt علي AI Studio
configs = genai.GenerationConfig(
temperature=0.1, top_p=1,
max_output_tokens=5)
model = genai.GenerativeModel('gemini-1.5-flash-001', generation_config=configs)
zero_shot_prompt = """Classify movie reviews as POSITIVE, NEUTRAL or NEGATIVE.
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. I wish there were more movies like this masterpiece.
Sentiment: """
response = model.generate_content(zero_shot_prompt)
Markdown(response.text)
# output: Sentiment: **POSITIVE**Enum mode
يمكن أن ينتج الLLM نصوص أكبر من المطلوب أحيانًا. خاصية Enum mode بتخليك تحدد قيم محددة للإجابة عشان ميجودش من عنده. لمعلومات اكتر من هنا.
import enum
class Sentiment(enum.Enum):
# The response should be one of the following options
POSITIVE = "positive"
NEUTRAL = "neutral"
NEGATIVE = "negative"
configs = genai.GenerationConfig(
response_mime_type="text/x.enum",
response_schema=Sentiment
)
model = genai.GenerativeModel(
'gemini-1.5-flash-001',
generation_config=configs)
response = model.generate_content(zero_shot_prompt)
Markdown(response.text)
# output : positiveOne-Shot و Few-Shot
الـ "One-shot prompt" بيعتمد على تقديم مثال واحد للرد المتوقع، و"few-shot prompt" بيتضمن تقديم أكتر من مثال.
configs = genai.GenerationConfig(
temperature=0.1,
top_p=1,
max_output_tokens=250,
)
model = genai.GenerativeModel('gemini-1.5-flash-latest', generation_config=configs)
few_shot_prompt = """Parse a customer's pizza order into valid JSON:
EXAMPLE:
I want a small pizza with cheese, tomato sauce, and pepperoni.
JSON Response:
```
{
"size": "small",
"type": "normal",
"ingredients": ["cheese", "tomato sauce", "peperoni"]
}
```
EXAMPLE:
Can I get a large pizza with tomato sauce, basil and mozzarella
JSON Response:
```
{
"size": "large",
"type": "normal",
"ingredients": ["tomato sauce", "basil", "mozzarella"]
}
ORDER:
"""
customer_order = "Give me a large with cheese & pineapple"
response = model.generate_content([few_shot_prompt, customer_order])
print(response.text)
JSON mode
استلام JSON فقط بدون أي إضافات. نفس فكره ال Enum ولكن هنا علش شكل JSON.
import typing_extensions as typing
class PizzaOrder(typing.TypedDict):
size: str
ingredients: list[str]
type: str
configs = genai.GenerationConfig(
temperature=0.1,
response_mime_type="application/json",
response_schema=PizzaOrder,
)
model = genai.GenerativeModel('gemini-1.5-flash-latest', generation_config=configs)
response = model.generate_content("Can I have a large dessert pizza with apple and chocolate")
print(response.text)
Chain of Thought – CoT
التوجيه المباشر للنماذج بيدّي نتائج سريعة، بس ممكن يظهر فيها بعض الأخطاء (هلوسات). تقنية Chain of Thought بتطلب من النموذج يولّد خطوات التفكير الوسيطة للوصول للإجابة، وده بيكون مفيد خصوصًا مع الأمثلة او مايسمي ال few-shot.
prompt = """When I was 4 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step by step."""
response = model.generate_content(prompt)
Markdown(response.text)
Reason and Act – ReAct
model_instructions = """
Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation,
Observation is understanding relevant information from an Action's output and Action can be one of three types:
(1) <search>entity</search>, which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it
will return some similar entities to search and you can try to search the information from those topics.
(2) <lookup>keyword</lookup>, which returns the next sentence containing keyword in the current context. This only does exact matches,
so keep your searches short.
(3) <finish>answer</finish>, which returns the answer and finishes the task.
"""
example1 = """Question
من هو مؤسس مجلة "الأهرام" المصرية؟
Thought 1
السؤال يطلب معرفة من هو مؤسس مجلة "الأهرام" المصرية. سأبحث عن "مؤسس مجلة الأهرام" على ويكيبيديا.
Action 1
<search>مؤسس مجلة الأهرام</search>
Observation 1
مؤسس مجلة الأهرام هو الصحفي المصري محمد علي.
Thought 2
الفقرة تحتوي على الإجابة. محمد علي هو مؤسس مجلة الأهرام.
Action 2
<finish>محمد علي</finish>
"""
example2 = """Question
من هو الشاعر المصري الذي كتب قصيدة "الأطلال"؟
Thought 1
السؤال يطلب معرفة من هو الشاعر المصري الذي كتب قصيدة "الأطلال". سأبحث عن "الشاعر الذي كتب قصيدة الأطلال" في ويكيبيديا.
Action 1
<search>قصيدة الأطلال</search>
Observation 1
قصيدة "الأطلال" كتبها الشاعر المصري إبراهيم ناجي.
Thought 2
الفقرة تحتوي على الإجابة. إبراهيم ناجي هو الشاعر الذي كتب قصيدة "الأطلال".
Action 2
<finish>إبراهيم ناجي</finish>
"""
question = """Question
ما هي أشهر معالم السياحة في مدينة الأقصر؟
"""
model = genai.GenerativeModel('gemini-1.5-flash-latest')
react_chat = model.start_chat()
# You will perform the Action, so generate up to, but not including, the Observation.
config = genai.GenerationConfig()
response = react_chat.send_message(
[model_instructions, example1, example2, question],
generation_config=config)
print(response.text)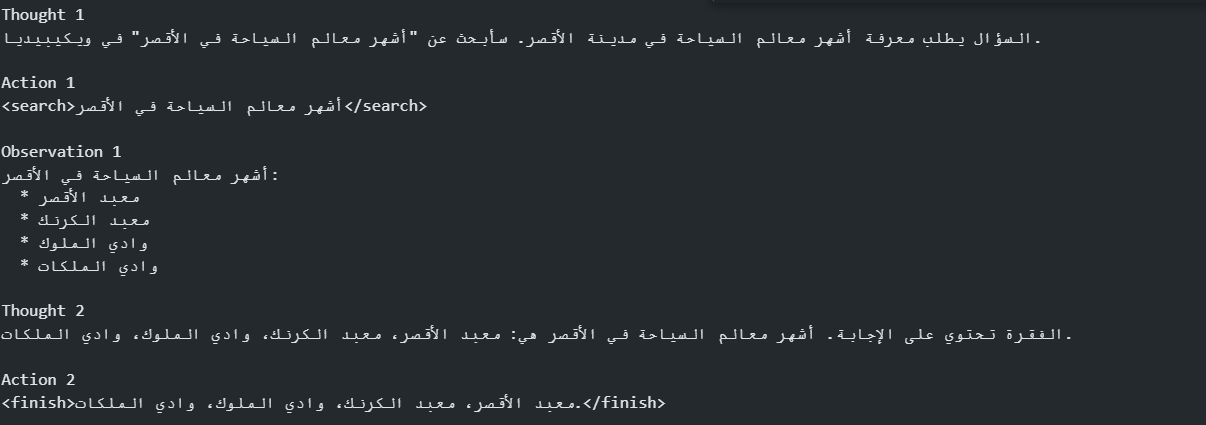
Code Prompting
Generate Code
يمكن للـ LLMs توليد الأكواد، تنفيذها، وشرحها، وده بيكون مفيد جدًا أثناء تعلم البرمجة، اكتساب لغة جديدة، أو للإسراع في إنتاج النسخة الأولى من الأكواد. لكن مهم تعرف إن LLMs مش بتستنتج زي البشر، وعلشان كده لازم تقرأ وتختبر الكود بعناية قبل استخدامه.
model = genai.GenerativeModel(
'gemini-1.5-flash-latest',
generation_config=genai.GenerationConfig(
temperature=1,
top_p=1,
max_output_tokens=1024,
))
# Gemini 1.5 models are very chatty, so it helps to specify they stick to the code.
code_prompt = """
Write a Python function to calculate the factorial of a number. No explanation, provide only the code.
"""
response = model.generate_content(code_prompt)
Markdown(response.text)
Execute Code
الـ API Gemini قادر على تشغيل الأكواد اللي بينتجها مباشرةً، وبيظهر لك الناتج.
model = genai.GenerativeModel(
'gemini-1.5-flash-latest',
tools='code_execution')
code_exec_prompt = """
Calculate the sum of the first 14 prime numbers. Only consider the odd primes, and make sure you get them all.
"""
response = model.generate_content(code_exec_prompt)
Markdown(response.text)كمان نقدر نفحص الرد لرؤية كل خطوة: النص الأولي، توليد الكود، نتيجة التنفيذ، والملخص النهائي.
for part in response.candidates[0].content.parts:
print(part)
print("-----")Explain Code
نماذج Gemini بتقدر كمان تشرح لك الأكواد. في المثال دا انا ادتها لينك لكود عندي علي GitHub وعرفت تشرحة بطريقه مفيده جدا.
file_contents = !curl https://raw.githubusercontent.com/code-quests/open-source-analysis-notebook/refs/heads/main/src/data_collection.py
explain_prompt = f"""
Please explain what this file does at a very high level. What is it, and why would I use it?
```
{file_contents}
```
"""
model = genai.GenerativeModel('gemini-1.5-flash-latest')
response = model.generate_content(explain_prompt)
Markdown(response.text)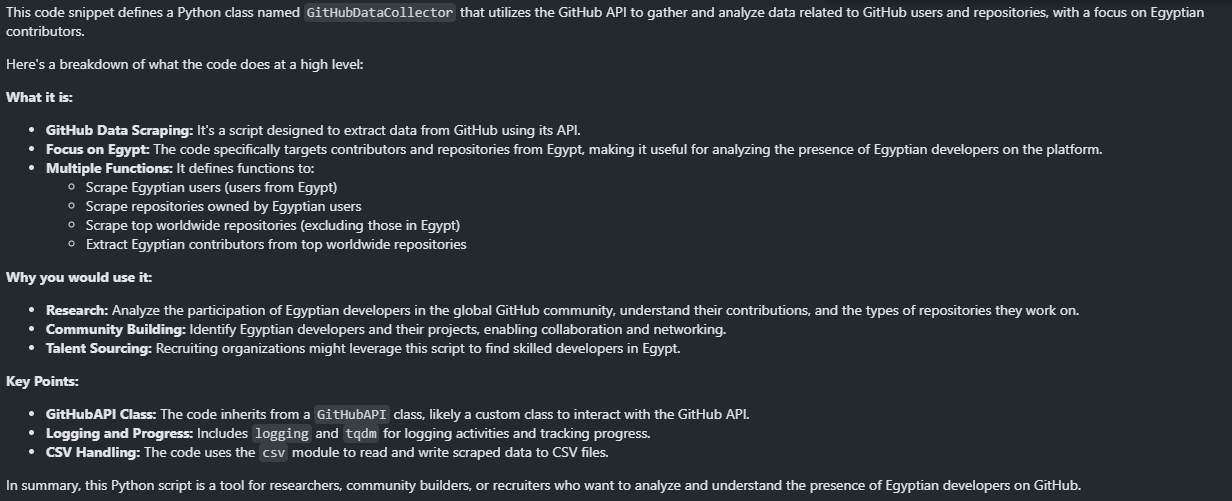
في الختام
ما تم عرضه في الـtutorial السابق بيعتمد على تشغيل الأكواد على جهازك الشخصي، وده بيساعد في توضيح النقاط الأساسية بشكل عملي، زي ما ذكرنا في جزء الـSetup ، طبعاً تقدر تستخدم أي منصة تانية لتشغيل الأكواد زي Kaggle أو Colab، لكن تشغيل الأكواد علي ال environment بتاعتك هيفيدك اكتر للتأقلم علي فكره ال virtual environment بشكل أفضل، وبيساعدك كمان على إتقانها ومتابعة النتائج مباشرة. علشان تستفيد بشكل كامل، جرب الأكواد بنفسك أو استخدم الرابط المرفق لتشغيلها.
المصادر
- https://github.com/heba14101998/Gemini-API
- https://www.kaggle.com/code/markishere/day-1-prompting
- https://ai.google.dev/gemini-api/docs/models/gemini
- https://github.com/google-gemini/cookbook/blob/main/quickstarts/Enum.ipynb
- https://github.com/google-gemini/cookbook/blob/main/quickstarts/JSON_mode.ipynb
- https://github.com/google-gemini/cookbook/blob/main/examples/Search_Wikipedia_using_ReAct.ipynb
















Discussion