

المقدمة
بعد انتشار الأقاويل بأن GPT-4 يعتمد على عدة نماذج تعمل معًا لإنتاج مخرجاته، ظهر مصطلح "Mixture of Experts" واختصاره (MOE). هذه المنهجية تعتمد على تجميع مجموعة من النماذج الصغيرة (Experts)، حيث يتخصص كل منها في معالجة مهام معينة.
الفكرة تشبه استشارة مجموعة من الخبراء المتخصصين في مجالات متعددة بدلاً من الاعتماد على خبير واحد شامل، مما يؤدي إلى تحسين دقة وفعالية الأداء.
في هذا المقال، سنتناول آلية عمل MoE، مميزاته، واستعراض نموذج Mixtral من شركة Mistral AI الذي يطبق هذا المفهوم.
فرصة تكسب 20,000 جنيه!
لو عايز تطوّر مهاراتك وتشتغل على تحسين AI Coding Agent مصري مش بس كده ده كمان open source ، وتنافس مبرمجين تانيين، دي فرصتك!
🎯 شارك في مسابقتنا واشتغل على تحسين وتطوير الـAI Coding Agent (س18)، وكمان عندك فرصة للفوز بجائزة 20,000 جنيه مصري! 💰
🔹 إيه اللي هتستفيده؟
✅ تشتغل على مشروع Open Source حقيقي
✅ تتعلم وتنافس مع أفضل المبرمجين
✅ فرصة للفوز بجائزة مالية محترمة
✅ المساهمة في تحسين أداء وبرمجة الـ AI Agents لتكون أكثر كفاءة
📌 ما تفوّتْش الفرصة! سجل دلوقتي لينك فى اول كومنت وكن جزء من التحدي! 🚀
ما هو Mixture of Experts (MoE)
الMixture of Experts هو ببساطة مجموعة من الmodels، حيث يُطلق على كل نموذج "خبير" (expert) ومع الوقت كل expert بيكون مسؤول عن حاجه معينه. يمكن تشبيه هذا بنظام يجمع خبراء متخصصين في مجالات متعددة لمناقشة موضوع معين. بدلاً من الاعتماد على خبير شامل لمناقشه الموضوع معه وحده، لذلك الأفضل أن نستعين بمجموعة من الخبراء المتخصصين لتحقيق أفضل النتائج.
عناصر تكوين Mixture of Experts (MoE)
يتكون MoE من عنصرين رئيسيين:
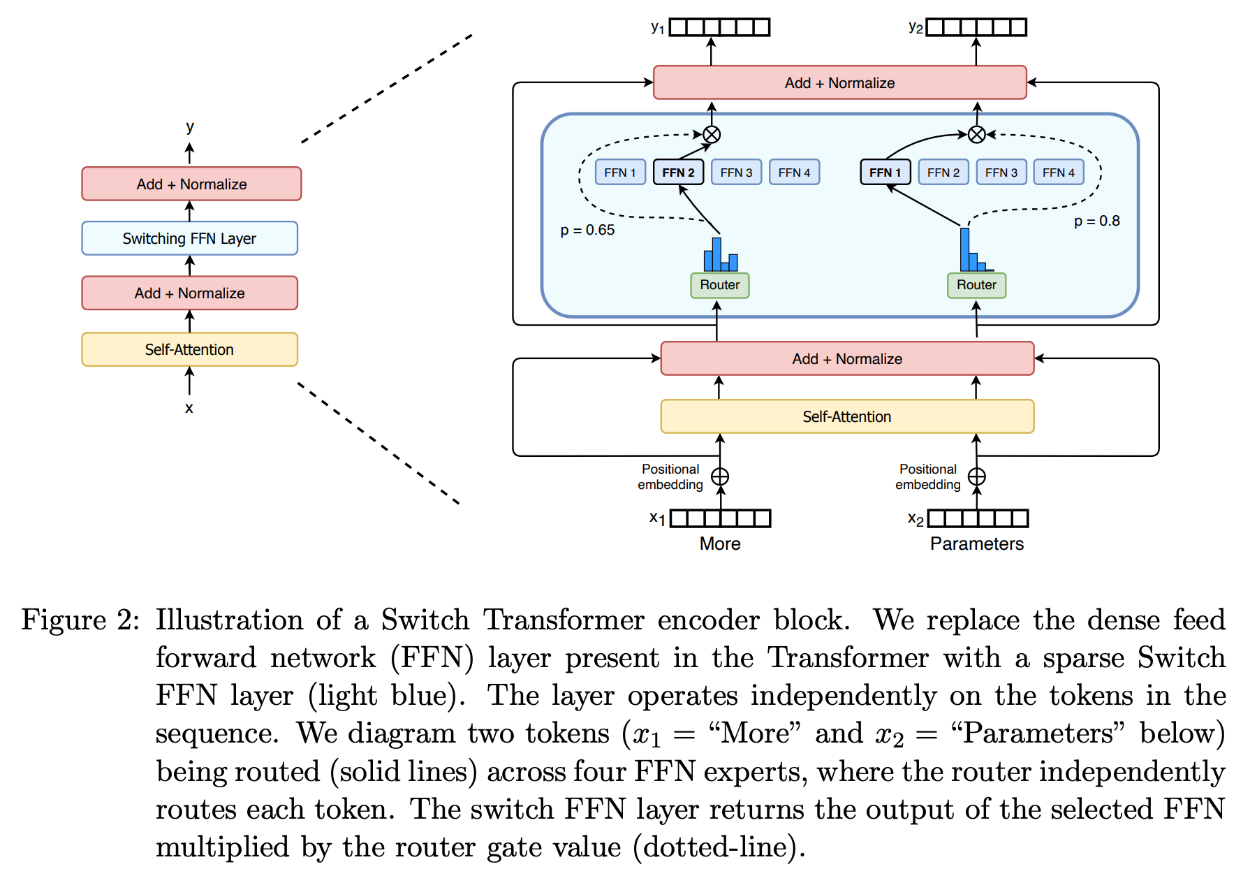
- Sparse Layers: تُستخدم بدلاً من FFN layers و تحتوي على عدد معين من experts (مثلًا experts 8)، ويمثل كل expert شبكة FFN، لكن يمكن أن تكون أيضًا شبكات أكثر تعقيدًا أو حتى نموذج MoE بنفسه، مما يؤدي إلى إنشاء نماذج MoE هرمية.
- Gate Network أو Router: والتي تحدد أي الtokens تُرسل إلى أي expert. كما سنستكشف لاحقًا، يمكننا إرسال توكن إلى أكثر من expert واحد. ويعتمد تدريب الـ Router على توجيه الtokens بشكل فعال إلى ال experts المناسبين.
شركة Mixtral ونموذج Mistral AI
ظهرت شركة Mistral AI على الساحة بتقديم نموذجها Mixtral 7B، الذي تمكن من منافسة نماذج كبيرة مثل LLAMA2. ثم أطلقت الشركة نموذجًا أكثر تطورًا، Mixtral 8x7B، الذي يعتمد على 8 خبراء، كل خبير بحجم7B parameters وأظهر Mixtral 8x7B أداءً أفضل في عدة مهام، خصوصًا في التعامل مع لغات متعددة، بينما كان LLAMA 70B يعتمد بشكل أساسي على اللغات اللاتينية.
أيهما أفضل التدريب بين النماذج الكبيرة والصغيرة ؟
عند اتخاذ القرار بين تدريب نموذج كبير لعدد محدود من الفترات الزمنية (epochs) أو تدريب نموذج صغير لفترات زمنية أطول، يعتمد الأمر على الأولويات والموارد المتاحة.
لنفرض أن هناك ميزانية ثابتة. هل يتم تدريب نموذج كبير (large model) على 10 epochs ، أو نموذج صغير (small model) على 100 100 epochs ؟
النماذج الكبيرة لديها القدرة على التعلم بشكل أسرع وأعمق، حتى لو تم تدريبها لعدد أقل من ال epochs، مما يعطيها ميزة في مرحلة ال fine-tuning. ولكن عند الانتقال إلى الإنتاج(production) ، تظهر تحديات في الأداء وسرعة التنفيذ، حيث يمكن أن تكون النماذج الصغيرة أسرع وأقل تكلفة.
- إذا كانت الأولوية هي دقة النموذج يمكن أن يكون الlarge model هو الخيار الأفضل، حتى مع عدد أقل من ال epochs
- إذا كانت الأولوية هي سرعة التنفيذ (inference) والكفاءة في الإنتاج (production) ، فإن الsmall model قد يكون أكثر ملاءمة، خاصة في التطبيقات التي تتطلب أداءً سريعًا وتكلفة تشغيل منخفضة.
النماذج الكثيفة مقابل النماذج المتناثرة Dense vs. Sparse Models
الفروقات الأساسية بين Dense و Sparse تتعلق بكيفية استخدام ال nodes أثناء التدريب (training) والتنفيذ(Inference)
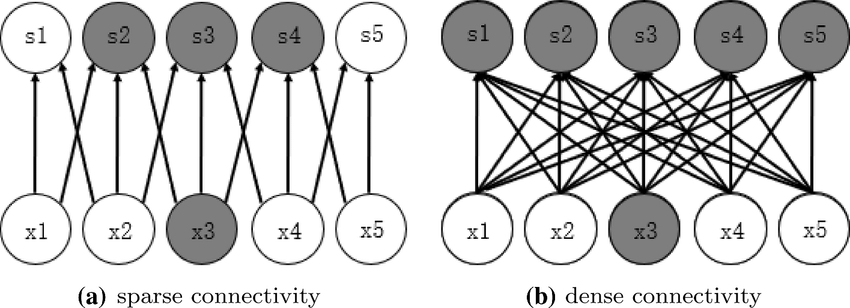
مثال للايضاح:
- إذا كان لدي مثلاً 100 خانة لأضع فيها جميعا أرقاماً، حيث تكون جميع الخانات مشغولة هنا يمكن القول إن النموذج مكثف (Dense)
- لكن إذا كان لدي 100 خانة، وليست جميعها مشغولة، بمعنى أن هناك بعض الخانات تحتوي على قيمة صفر، في هذه الحالة نسميه نموذج نادر (Sparse). ومع ذلك، فإن الشبكة العصبية لا تحتوي على قيم صفر، بل دائماً تحتوي على قيم، حتى وإن كانت ضعيفة أو صغيرة.
إذا افترضت أنك قادر على بناء نموذج يحتوي على 100 مليار معلومة (parameters)، وإذا قمت ببنائه على هيئة كتلة واحدة، هنا تتحدث عن شبكة عصبية مكثفة (Dense NN). لكن إذا تمكنت من تقسيم الـ 100 مليار parameters إلى مجموعات تتكون كل منها من 10 مليارات، وفي أثناء التدريب تقوم بتشغيل مجموعة واحدة فقط من ال parameter وليس جميعها، هنا قد أنشأت نموذجاً نادراً (Sparse Model).
وبالرغم من أنك تمتلك 100 مليار معلمة، إلا أنك تتحكم في تشغيل 10 مليارات فقط في وقت التنفيذ (inference) لذا، لدينا نموذج كبير، لكن في وقت التنفيذ ، جزء منه فقط هو الذي يعمل، وبالتالي ينطبق عليه مصطلح (sparse)
| المميزات | النماذج الكثيفة (Dense Models) | النماذج المتناثرة (Sparse Models) |
|---|---|---|
| نشاط الnodes | جميع الnodes نشطة ومتصلة أثناء التدريب والتنفيذ | بعض الnodes غير نشطة أو غير مستخدمة في لحظة معينة |
| استخدام الnodes | تُستخدم جميع الnodes في كل المراحل | تُفعل مجموعات محددة من الnodes حسب الحاجة |
| استهلاك الموارد | تتطلب processing power and RAM كبيرة | تقلل من عدد الحسابات، مما يقلل استهلاك الموارد |
| الدقة | تتميز بدقة عالية بسبب كمية كبيرة من المعلوماتparameters | قد تكون أقل دقة في بعض الحالات مقارنة بالنماذج الكثيفة، ولكنها عمليه اكثر في ال inference |
| الكفاءة | تحتاج إلى موارد أكبر أثناء عملية الاستدلال | أكثر كفاءة من حيث استهلاك الموارد. |
آلية عمل MoE توزيع المهام بين ال Experts
يتولى الـ gate أو router مسؤولية اختيار أي expert سيعالج كل token بمعنى أن الـrouter لا يعتمد على فكرة أن المهمة مثلا الخاصه بال coding يتم ارسالها للexpert الخاص بالcoding tasks، أو أن المهمة تتعلق بالنظام الصحي فيرسلها لexpert متخصص في health tasks. بل يعمل على مستوى كل token على حدة، ويختار الخبير المناسب بناءً على التحليل الفردي لكل جزء من المدخلات.
يتم اختيار (k experts) للتعامل مع كل Token،ولكن كيف؟
لنفترض أن لدينا 8 experts -→ E1,E2,E3,E4,E5,E6,E7,E8، ونريد اختيار 3 experts لمعالجة token معين وليكن eqraatech"".
- ادخال الToken : يتم ادخال ال token لل Gate لحساب gating scores (logits) وعادة يكون من خلال FFN
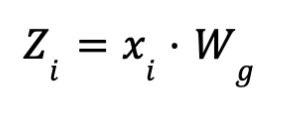
- xi token embeddings:
- Wg: مصفوفة الأوزان الخاصة بال gating network
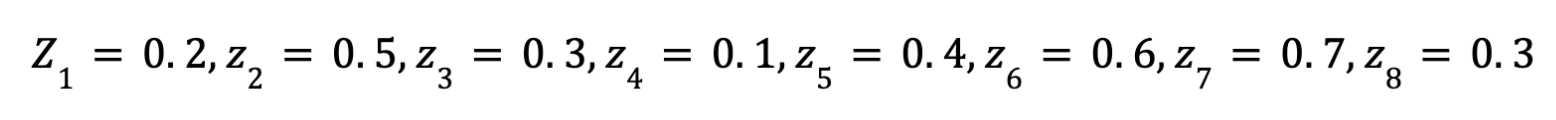
- تنفيذ SoftMax : يقوم ال gate بتنفيذ الSoftMax function علي ال8 نواتج فيكون الناتج بعد الSoftMax كالتالي، الأمر كأني بدي وزن لكل expert علي فقط eqraatech token وليس علي الtask ككل او علي الجمله ككل
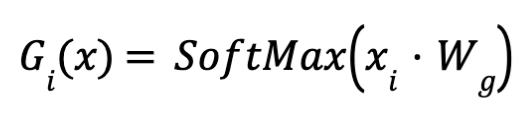
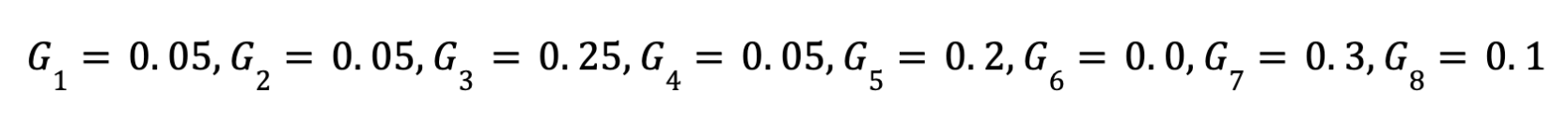
- اختيار : 3 experts يتم ترتيب الاوزاران الناتجه عن الGate or Router ثم اختيار أعلي ثلاث قيم لان الهدف من البدايه هو اختيار top 3 experts ومن خلال المثال المذكور يكون افضل ثلاث خبراء لعمل معالجه لكلمه eqraatech هم الخبراء التاليه
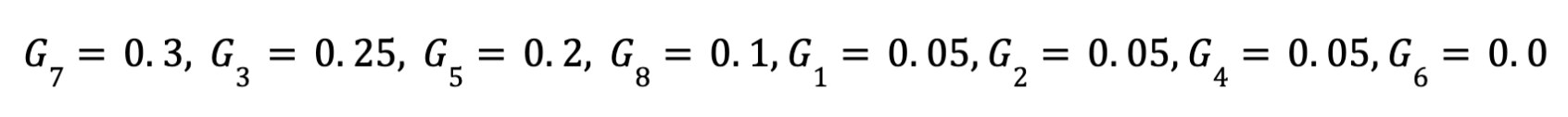
- التجميع: (Aggregation) يتم تجميع نتائج ال3 experts بعد ضرب كل نتيجة في ال weight الخاص بكل expert ثم عمل عمليه جمع للنواتج في ناتج واحد يعبر عن هذا ال token
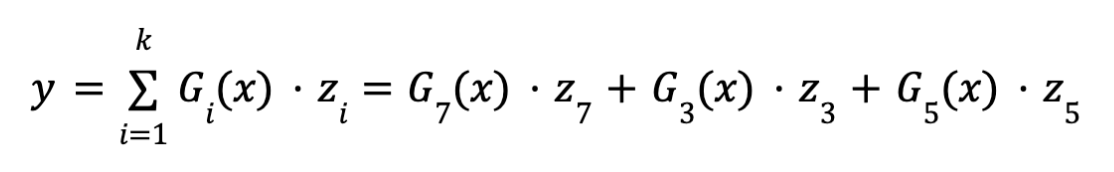
- : K=3نريد عمل معالجه للكلمه عن طريق تلت خبراء من مجموع 8
- Gix: هو وزن يحدد مدي اهميه كل معالجه كل خبير
- zi:المعالجه الخاصه بالكلمه او ال token
- y: ناتج المعالجه (processing) النهائيه لكلمة eqraatech
تحديات الـ Overfitting وحلولها
من أبرز التحديات التي تواجه MoE هي مشكلة ال overfitting، حيث يمكن أن يتحيز الـ router مع الوقت إلى مجموعة معينة من الخبراء (few popular experts) ، فبعض الexperts قد يتم اختيارهم بشكل متكرر، في حين أن الآخرين يتم تجاهلهم بشكل شبه دائم، مما يؤدي إلى توزيع غير عادل للمهام. وهذا الوضع غير مثالي لأن بعض الخبراء قد يتدربون بشكل أفضل وأسرع من غيرهم، مما يعزز اختيارهم بشكل أكبر ويؤدي إلى تفاقم المشكلة.
للتغلب على هذه المشكلة، يتم إضافة ضوضاء (Auxiliary Loss) في عمليه التدريب، مما يجبر النموذج على توزيع العمل بشكل عادل بين ال experts ويقلل من الانحياز.
الـ Auxiliary Loss وكيفية عمله
يتم إضافة ضوضاء قابلة للتعديل علي نتائج الـ logits لتحديد الexperts الأنسب لمعالجة ل token. باستخدام تقنيات مثل noisy top-k gating، يتم توزيع ال tokens بشكل عادل بين الexperts لضمان عدم تحيز لأي expert معين.
- اضافة noise قابلة للتعديل (tunable noise) على ال logits ينتج عنها Hix وهي noisy logits

- ثم يختار أعلى القيم فقط (Noisy Top-k Gating)
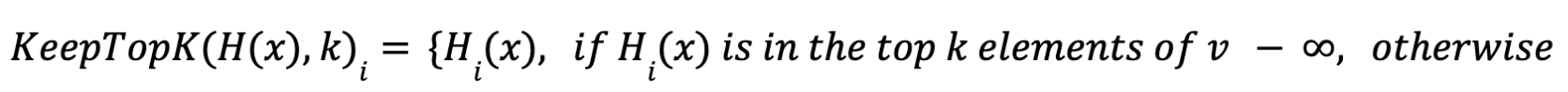
- تنفيذ SoftMax
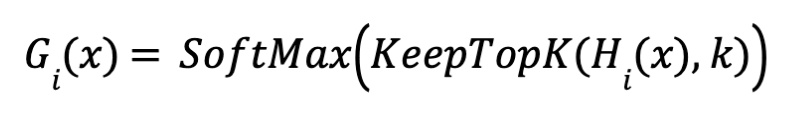
يعمل auxiliary loss على تفعيل جميع الexperts بشكل متساوٍ خلال التدريب، مما يضمن أن كل expert يحصل على حصة عادلة من البيانات، ويمنع expert معين من السيطرة على البقية.
نماذج MoEs والـ Transformers
تعتبر ال Transformers مثالًا واضحًا على أن زيادة عدد parameters يحسن الأداء. بناءً على هذا المبدأ، قامت Google باستكشاف هذا المجال من خلال GShard، وهي تقنية تسمح بزياده حجم ال Transformer لتتجاوز 600 مليار parameters
في تقنية GShard، يتم استبدال كل طبقة FFN بأخرى من نوع MoE باستخدام طريقةTop-2 Gating ، وذلك في كل من ال Encoder وال Decoder
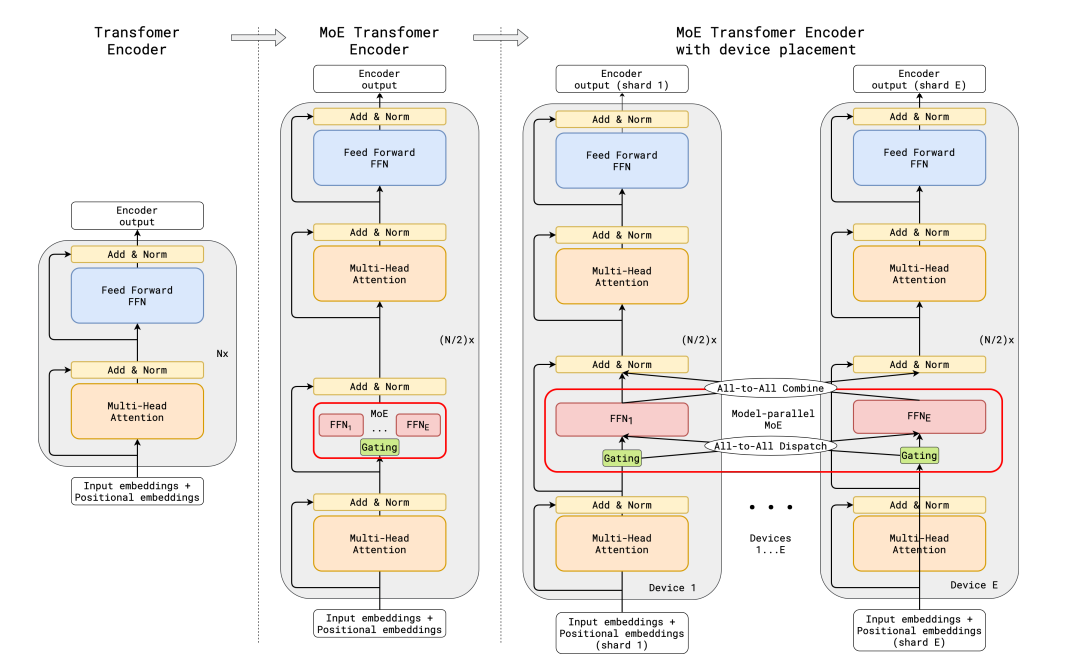
قدم مؤلفو GShard عدة تغييرات بالإضافة إلى auxiliary loss التي تم مناقشته سابقًا:
- التوجيه العشوائي : (Random Routing) في إعداد Top-2، يتم اختيار الخبير الأول دائمًا، ولكن يتم اختيار الخبير الثاني بناءً على احتمال يتناسب مع وزنه.
- يتم تحديد Expert Capacity: حيث يتم تعيين حد أقصي لعدد ال tokens يمكن لكلExpert معالجتها إذا وصلت سعة ال Top-2experts إلى الحد الأقصى، يتم اعتبار الـ token فائضًا (overflowed)، ويتم إرساله إلى الطبقة التالية عبر residual connections أو يتم إسقاطه تمامًا (drop token). تُعتبر هذه الفكرة من أهم المفاهيم في MoEs، لأنها تساهم في تحسين الأداء عند التدريب والمعالجة على نطاق واسع.
الـ Experts وتخصصاتهم
في النماذج المعتمدة على Transformers، يوجد لدينا جزئين أساسيين: جزء خاص بـ Encoder وآخر بـ Decoder. لوحظ أن experts الموجودين في Encoder بدأوا يتخصصون في أنواع محددة من البيانات. على سبيل المثال، قد يتخصص خبير معين في التعامل مع الأفعال (verbs)، بينما يتخصص خبير آخر في الصفات (adjectives). هذا التخصص يساهم في تحسين قدرة النموذج على فهم البيانات بشكل أعمق وأكثر تعقيدًا مقارنة بالنماذج التقليدية، مما يعزز من دقة النموذج وكفاءته.
حجم نموذج MoE وعملية الـ Inference
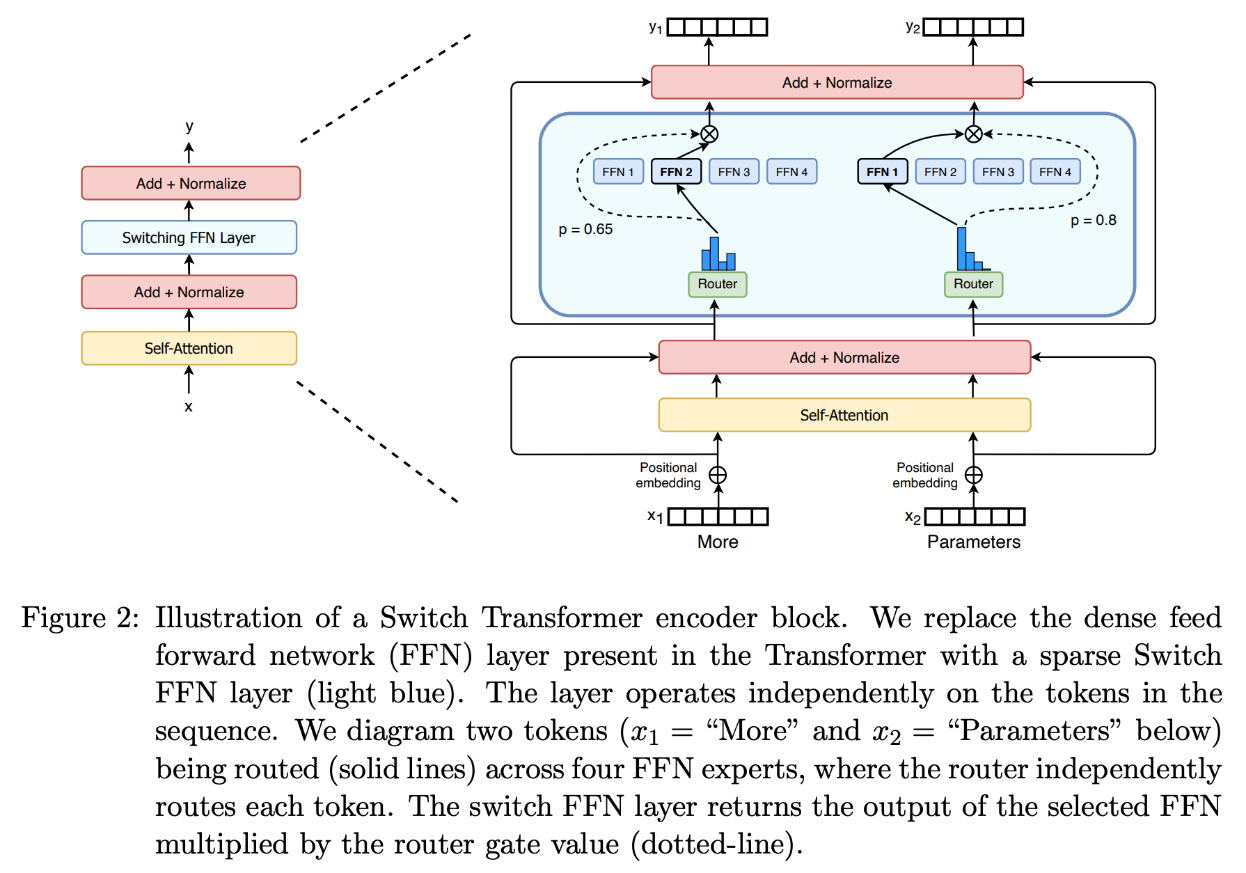
يحتوي النموذج علي 8 experts كل منهم يحتوي علي 7 مليارات parameters ، وبالتالي من المتوقع أن يكون الحجم الإجمالي للنموذج 56 مليار parameters. ولكن ال MoE مكون فقط 47 مليار parameters وذلك لوجود عمليه مشاركه لعدد من ال parameters في بعض العمليات الحسابية مثل عمليه ال Self-attention المشار اليها باللون الأصفر في الصوره.
فأثناء التنفيذ (inference)، لا يتم تفعيل جميع الexperts، وبذلك يتم تشغيله بنفس الresources التي نحتاجها لتشغيل الخاصة ب dense model بحجم 12B parameters، وإذا استخدمنا Top-2 سيتم استخدام 14Bمن المعاملات. ولكن نظرًا لأن عمليات مثل Self-Attention مشتركة بين جميع الexperts، فإن العدد الفعلي للparameters المستخدمة يبقى عند 12B
ومع هذا فلا يمكن مقارنة عدد الـ parameters بين النماذج الـ Sparse والـ Dense مباشرة، ذلك لأن كل نوع يمثل هيكل مختلف، الـ Sparse يحتوي على عدد كبير من الـ parameters ولكنه يستخدم فقط جزءًا منها في كل مرة، بينما النموذج الـ Dense يستخدم كل الـ parameters في كل عملية.
متى تستخدم Sparse MoEs مقابل Dense Models
تعتبر الـ Experts مفيدة في سيناريوهات التي تحتاج high throughput مع العديد من الأجهزة. إذا كان لديك ميزانية محددة للحساب أثناء عملية الـ pre-training، سيكون النموذج الـ Sparse أكثر كفاءة. أما في السيناريوهات تحتاج low throughput وذاكرة الـ VRAM قليلة، سيكون النموذج الـ Dense هو الأفضل.
تحسين أداء MoEs
في البدايه كان يعمل MoE بالنظام التشعبي (branching) فأثّر ذلك على سرعة الحسابات، ويعني هذا أن كل expert يتلقى مجموعة من البيانات أو المهام، مما يؤدي إلى توزيع الحمل عبر عدة مسارات (branches) فمن خلال توزيع الحمل على عدد من الexperts، يمكن تحسين أداء الmodel، حيث يتمكن كل expert من التركيز على جزء محدد من البيانات أو نوع معين من المهام. لكن هذا الأسلوب يؤدي إلى بطء في الأداء بسبب الحاجة إلى إرسال البيانات وعمل communication بين ال experts لتجميع النواتج وقد يؤدي لحدوث bottleneck
لمعالجه ذلك تم اقتراح بعض التقنيات لعمل parallelization وجعل pretraining و inference أكثر كفاءة. وهناك عدة أنواع :
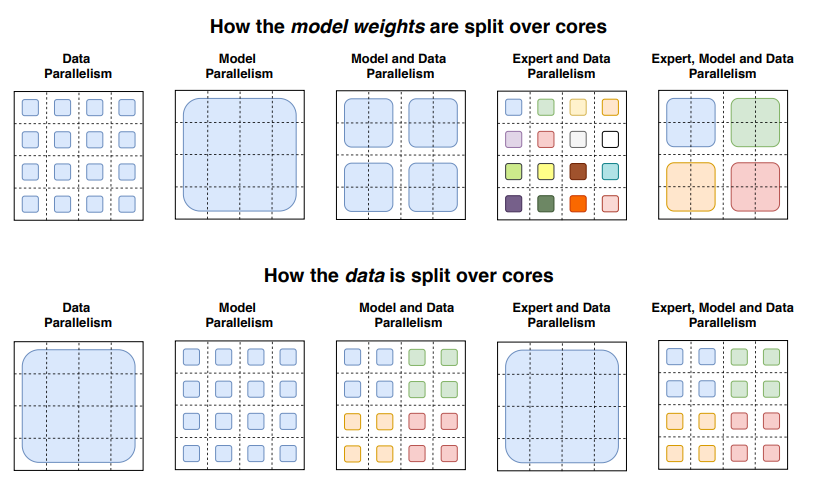
- : Data Parallelism ويتم تقسيم البيانات لbatches مختلفه عبر ال cores و تكرار نفس الparameters عبر جميع cores
- : Model Parallelism يتم تقسيم الmodel عبر الcores وتكرار الtraining samples عبر ال cores(كل core يأخذ نفس الsamples )
- او يمكن القول انه يتم تقسيم ال parameters لان الmodel احدي مكوناته الرئيسيه هي الparameters
- : Model and Data Parallelism يتم تقسيم الmodel وأيضا الtraining samples عبر الcores. لاحظ أن كل Core يعالج (batches) مختلفة من البيانات.
- Expert Parallelism : يتم وضع الexperts على workers مختلفه. وكل worker يأخذ batch مختلفة من الtraining samples. وفي ال layers الأخرى الغير مكونه من مجموعه experts مثل ال self-attention تكون نفس ال layer في كل worker ويتشاركوا جميعا في ال parametersبنفس نظام ال Data parallelism
تأثير زيادة عدد الـ Experts علي الـ Pre-Training
زيادة عدد experts تؤدي إلى تحسين الكفاءة وسرعة التدريب، لكن هذه الفوائد تتناقص بشكل تدريجي، خاصة بعد 256 أو 512 expert. كما أن زيادة عدد ال expertsتتطلب VRAM أكبر أثناء ال inference والدراسات التي قامت بها Google في Switch Transformers paper كانت على نطاق صغير حيث وُجد 2 أو 4 أو 8 expert في كل layer
أداء النموذج في المهام المختلفة
- بالمقارنة مع النماذج التقليدية (Dense Models)، نجد أن النماذج التقليدية تتفوق بشكل كبير في المهام التي تتطلب استدلال (Reasoning) مثل SuperGLUE ، بينما لا يعتبر MoE الخيار الأفضل لتلك المهام. ولكنه مثالي للمهام التي تعتمد على المعرفة (Knowledge-Based Tasks) مثل TriviaQA ، وأكثر كفاءة في عمليات التنفيذ (Inference).
- كما لُحِظ أن تقليل عدد الخبراء ساعد في عملية تحسين النموذج.
- أظهرت النتائج أن النموذج كان أسوأ في المهام الصغيرة ولكنه كان جيدًا في المهام الكبيرة.
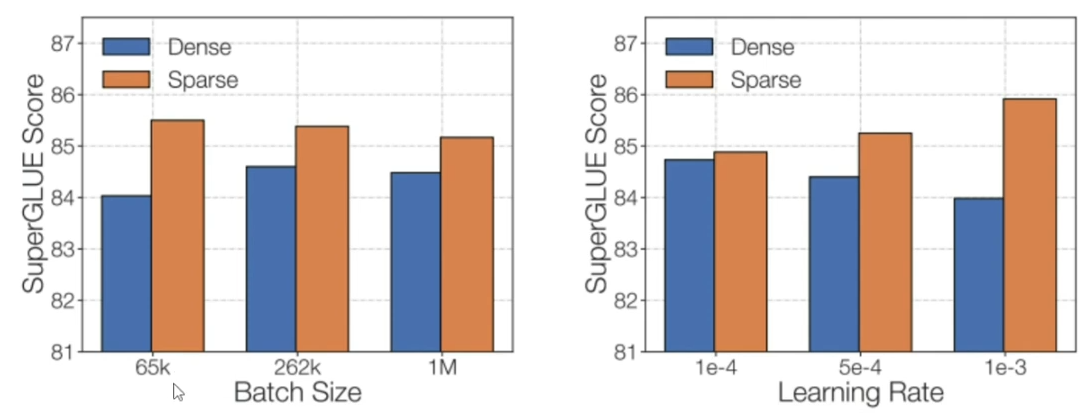
- أظهر MoE نتائج افضل مع ال batch size الصغيره
- أظهر MoE نتائج افضل مع ال learning rate الاكبر
مزايا MoE وسرعة التنفيذ
تم اطلاق نموذجًا يحتوي على 1.6 تريليون parameter على Hugging Face مكون من 2048 experts، و يمكنك تشغيله باستخدام Transformers وقد حقق تسريعًا بمعدل 4x في ال pre-train مقارنةً بـ T5-XXL. وعرف هذا ب هذا بفضل القدرة على تشغيل مجموعة صغيرة فقط من الexperts في كل مرة، مما يقلل من ال calculations complexity ويزيد من كفاءة التنفيذ (inference)
وعرف هذا بSwitch Transformers ويطول الحديث عنه لذلك سنخصص له مقاله اخري.
التحديات المستقبلية والتطبيقات
على الرغم من أن MoEs أظهرت وعودًا كبيرة، إلا أنها تواجه تحديات في استقرار training and fine-tuning instabilities.
ورغم أن MoE أثبت كفاءته في العديد من المجالات، إلا أن تطبيقه في الإنتاج يتطلب موارد ضخمة وتحديات كبيرة، مثل الحاجة إلى ذاكرة VRAM كبيرة تصل إلى 56 جيجابايت، مقارنة بـ 7 جيجابايت في النماذج التقليدية، مما يخلق تحديًا كبيرًا في عملية التشغيل (Deployment) ومع ذلك، يظل MoE واعدًا في تحسين السرعة والدقة.
ولكن السؤال هو لماذا الحاجه الي VRAM عالي في ال inference بالرغم من تشغيل عدد قليل من الparameters في كل مره؟
- عند استخدام الـ Sparse MoEs، لا يتم تفعيل جميع الـ Experts في كل عملية، مما يعني أن النموذج يقوم بمعالجة جزء من الـ parameters في كل مرة. هذا يمكن أن يقلل من استهلاك الذاكرة المؤقتة VRAMأثناء العمليات.
- ولكن يلزم تخزين النموذج بالكامل ولان النموذج ككل يحتوي على عدد كبير من الـ parametersلذا، حتى لو كان استهلاك الذاكرة مؤقتًا أقل بسبب التفعيل الجزئي، يجب أن يكون لديك VRAM كافية لتحميل النموذج بالكامل
في الختام
يمكن القول بأن Mixture of Experts يمثل تحولًا كبيرًا في عالم نماذج الذكاء الاصطناعي، حيث يتيح التعامل مع مهام مختلفة بكفاءة أكبر بفضل تخصيص مهام محددة لكل expert. وعلى الرغم من وجود بعض التحديات المتعلقة بالـ overfitting والتواصل بين النماذج المختلفة، إلا أن التحسينات المستمرة مثل إدخال الـ auxiliary loss والمحددات الذكية لاختيار الـ experts أظهرت نتائج واعدة. من خلال تجارب شركة Mistral AI ونماذجها مثل Mixtral، يمكن أن نرى كيف يمكن لـ MoE أن يحدث ثورة في أساليب تطوير النماذج، مما يجعلها أسرع وأكثر كفاءة في مواجهة التحديات المتزايدة في مجالات الذكاء الاصطناعي المختلفة.
المصادر
 huggingface
huggingface


















Discussion