نتفليكس عندها مئات الملايين من المستخدمين اللي بيتفرجوا كل يوم، وطبعًا المستخدمين دول متوقعين إن الخدمة تفضل شغالة من غير أي مشاكل وده لإنهم بكل تأكيد مشتركين بفلوس. وعلشان ده يحصل ويتحقق، نتفليكس عندها backend systems ضخمة بتشتغل ورا الكواليس عشان توفر تجربة مشاهدة سلسة للمستخدمين.
بس المشكلة هنا إن الـ backend systems دي مش ثابتة، بل بالعكس، بتتطور بشكل مستمر وبيتضاف لها تحسينات علشان تواكب احتياجات المنتج والمستخدمين مع الوقت. والمشكلة الحقيقية بتكمن في إن أي migration هيتم لنظام جديد ممكن يكون فيه مخاطر كبيرة جدًا، خصوصًا لو النظام ده كان بيخدم Traffic عالي أو بيأثر بشكل مباشر على تجربة المستخدم. وبقاله فترة ومدة طويلة Stable.
فاحنا لما بنيجي نعمل migration من نظام قديم لجديد، أكبر تحدي بيقابلنا هو إننا نضمن إن كل حاجة شغالة زي ما هي، من غير حدوث أي downtime، ومن غير ما المستخدم يحس بأي مشكلة.
فخلونا نشوف ايه هي المفاهيم والأدوات والتقنيات اللي نتفليكس استخدمتها علشان تقدر تنقل الـ traffic العالي اللي بيجيلهم بدون أي تأثير سلبي ونتعلم من تجربتهم.
Netflix Migration Challenges
نتفليكس معتمدة على Highly Distributed Micro-Service Architecture، وده معناه إن فيه عدد ضخم من الـ services اللي بتشتغل مع بعض في وقت واحد، وكل service ليها دور معين في تشغيل المنصة.
علشان كده، أي migration مش بيحصل مرة واحدة، لكنه بيتم على مراحل مختلفة، زي مثلًا:
الـ Migration على مستوى الـ edge API اللي بيستقبل الـ Requests من المستخدمين.
الـ Migration بين الـ edge services والـ Mid-Tier Services.
الـ Migration بين الـ Mid-Tier Services واللـ databases.
ومش بس كده، فيه كمان عامل تاني مهم ألا وهو إن فيه فرق بين الـ Migration لأنظمة بتتميز بطابع إنها stateless APIs (اللي مش بتحتفظ ببيانات المستخدم بين الـ Requests وبعضها)، وبين الـ Migration لأنظمة بتتميز بإنها stateful APIs (اللي محتاجة تحتفظ بحالة المستخدم زي الـ sessions).
Netflix Migration Strategies
نتفليكس استخدمت استراتيجيات منظمة علشان تقلل من المخاطر اللي ممكمن تحصل، وقسموا الـ Migration لمراحل:
1. Pre-Migration Validation
في المرحلة دي، بيتم اختبار الأنظمة الجديدة عشان يتأكدوا من:
صحة الـ Functionality بتاعتها وإنها شغالة زي ماهم عاوزين.
قابليتها للتوسع (Scalability).
أدائها تحت الضغط (Performance).
استقرارها في ظروف مختلفة (Resilience).
2. Gradual Traffic Migration
بعد ما يتأكدوا إن النظام الجديد سليم، بيبدأوا ينقلوا الـ traffic بالتدريج، وده بيتم من خلال:
مراقبة مستمرة للأداء.
مقارنة الـ Service Level Agreements اللي هي الـ SLAs والـ Business Key Performance Indicators اللي هي الـ KPIs بين النظام القديم والجديد.
التأكد من إن جودة الخدمة Quality of Experience عند المستخدم (QoE) ما تأثرتش.
الهدف هنا في المرحلة دي إن أي مشكلة تحصل، يتم اكتشافها بسرعة قبل ما الـ Migration يتم بالكامل.
Replay Traffic Testing
الـ Replay Traffic هو ببساطة الـ Traffic الحقيقي بتاع الـ production وبنعمله clone ونشغله على مسار مختلف تاني داخل الـ service call graph، وده بيدينا فرصة نجرب الأنظمة الجديدة أو المحدثة في ظروف شبه حقيقية من غير ما نأثر على المستخدمين الفعليين.
الفكرة هنا إننا بناخد نسخة من الـ production traffic، ونشغلها على الإصدار الجديد والقديم من النظام في نفس الوقت، وده بيساعدنا نعمل أي validations مهمة قبل ما ننقل الـ Traffic الفعلي.
المميزات
نقدر نختبر النظام الجديد بأمان من غير أي تأثير على تجربة المستخدم.
بنشوف الأداء والاستجابة تحت ضغط حقيقي لكن في بيئة sandboxed من نفس الـ Production Traffic.
بما إننا بنستخدم real traffic، بنقدر نغطي كل أنواع المدخلات المختلفة اللي بتيجي من الأجهزة المتنوعة وإصدارات الـ software المختلفة وده مهم جدًا كمان في الـ complex APIs اللي بتتعامل مع بيانات كتير متنوعة ومدخلات مختلفة.
بنقدر نختبر كمان السيناريوهات النادرة والـ edge cases اللي ممكن تكون مش واضحة في الـ unit tests العادية.
بنتأكد إن النظام الجديد بيشتغل صح وظيفيًا (functional correctness).
نقدر نستخدمه كمان في الـ load testing عشان نشوف أداء النظام تحت الضغط.
بيساعدنا إننا نظبط الـ scaling parameters بناءً على النتائج اللي بنحصل عليها عشان نحقق الأداء الأمثل واللي عاوزينه.
بنقدر نقيس Metrics مهمة زي الـ latency وavailability تحت ظروف الـ production traffic المختلفة.
بنشوف تأثير التغيرات في أنماط الـ Traffic المتوقعة وغير المتوقعة على أداء السيستم.
بنتأكد إن كل حاجة شغالة كويس، زي metrics, logging, alerting قبل ما ننقل الـ Traffic الفعلي للسيستم الجديد.
ده بيدينا فرصة نضبط أي مشاكل قبل ما نأثر على المستخدمين الحقيقين.
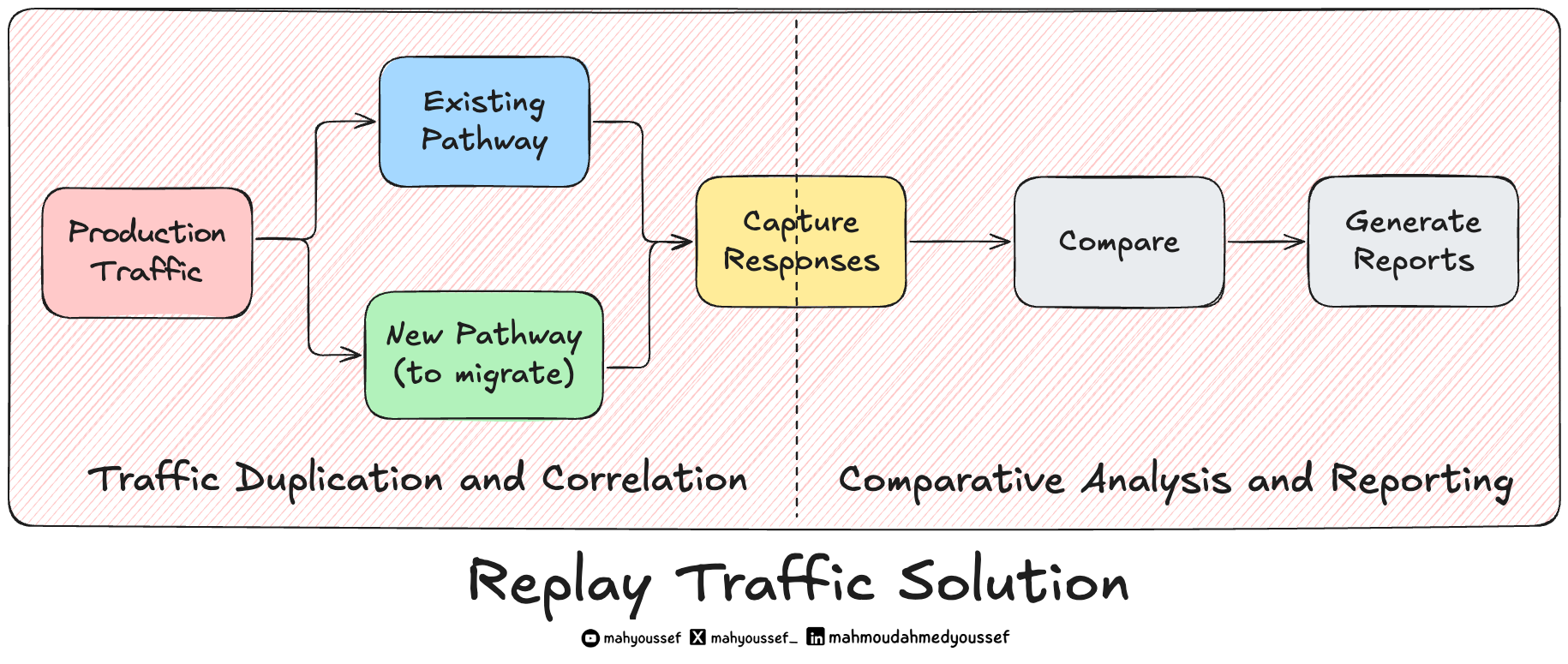
Replay Traffic Solution
علشان الـ Replay Traffic Testing يشتغل بكفاءة، فيه مكونين أساسيين لازم يكونوا موجودين:
Traffic Duplication and Correlation
أول خطوة هي إننا نعمل clone وfork للـ production traffic بحيث نبعته على المسار الجديد بجانب المسار القديم. لكن الموضوع مش مجرد نسخ الـ Traffic وخلاص، إحنا كمان محتاجين:
نسجل كل الـ Requests والـ Responses من المسارين (القديم والجديد).
نربط الاستجابات ببعض بحيث نقدر نقارنهم بعد كده ونعمل (Correlation).
Comparative Analysis and Reporting
بعد ما بنجمع كل البيانات، بنحتاج framework يساعدنا نحلل الفروقات بين الاستجابات اللي جت من المسارين، بحيث نطلع تقرير واضح عن:
هل في اختلافات في النتايج؟
هل النظام الجديد بيشتغل بنفس كفاءة القديم؟
هل فيه أي مشاكل في الأداء performance issues أو سلوك غير متوقع؟
Replay Traffic Solution
Traffic Duplication and Recording Approaches
نتفليكس جربت كذا طريقة علشان تعمل traffic duplication & recording خلال الـ migrations المختلفة، ومع كل محاولة كانوا بيحسنوا الطريقة أكتر. والحلول دي اشتملت على:
تشغيل الـ Replay Traffic من على الجهاز نفسه (Device-Side).
تشغيله من على السيرفر (Server-Side).
استخدام Service مخصصة لإدارة عملية التكرار والتسجيل.