مهمة Canva ورؤيتهم إنهم يمكنوا أي شخص في العالم من تصميم أي حاجة ونشرها في أي مكان. وجزء مهم من تحقيق الهدف ده هو برنامج Canva Creators.
من ساعة إطلاق البرنامج من 3 سنين تقريبًا، واستخدام المحتوى اللي بيقدموه الـ creators تضاعف في خلال 18 شهر. وحاليًا هم بيحسبوا ويدفعوا بناءً على مليارات الاستخدامات للمحتوى ده كل شهر للـ creators.
وطبعًا البيانات دي مش بتشمل templates بس، لكنها كمان بتضم الصور، والفيديوهات، وغيرهم من المحتوى اللي بيتم استعماله.
فبناء وصيانة خدمة لتتبع البيانات دي علشان الدفع يكون مظبوط وموثوق للـ creators كان فيه تحديات كتير زي:
الدقة (Accuracy): عدد الاستخدامات لازم يكون مظبوط 100% لأن الدخل المالي وثقة الـ creators معتمدين عليه.
القابلية للتوسع (Scalability): تخزين ومعالجة البيانات اللي بيتم استخدامها بشكل مهول وكبير جدًا بالإضافة لإنها في تزايد مستمر.
سهولة التشغيل (Operability): مع زيادة حجم بيانات الاستخدام، بيزيد التعقيد في الصيانة، والتعامل مع المشاكل اللي ممن تحصل، وأيضًا استرجاع البيانات في حالة أي مشاكل حصلت.
رحلة التطوير والبداية مع MySQL
في الأول كانوا بيستعملوا MySQL لأنهم كانوا متعودين عليه. وبالتالي بنوا الأجزاء الكبيرة من الـ Architecture بشكل منفصل باستخدام Worker Services، وكان عندهم طبقات متعددة من النتائج الوسيطة أو الـ Intermediary Output.
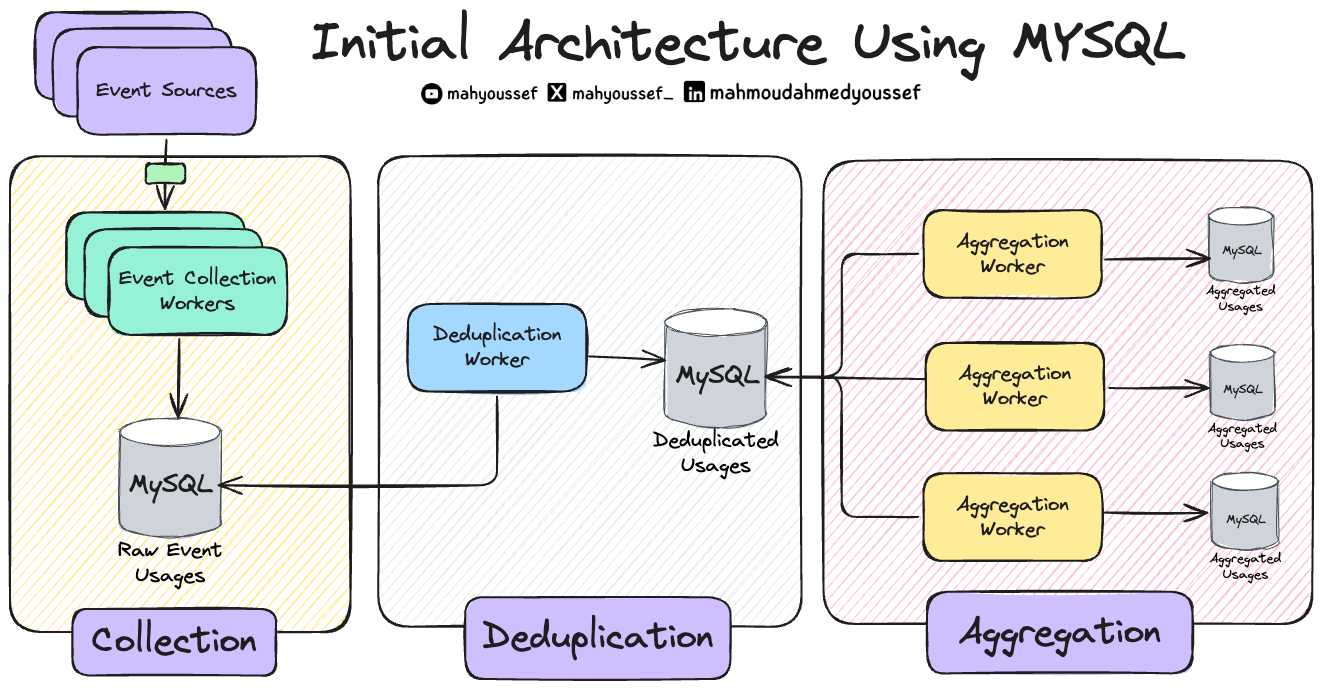
Canva Initial Architecture Using MySQL
فبكل بساطة كان عندهم Raw Usage من الـ Events اللي بتحصل وفيه Worker Service بيقوم بعمل الـ Deduplication على الـ raw usage events وبعدين يحطهم في قاعدة بيانات مستقلة للـ deduplicated usage events وفيه عندنا Aggregation Workers هم اللي بيقرأوا من قاعدة البيانات دي ويبدأوا يعملوا الحسابات وزيادة الـ usage counters ويعملوا update في الـ Aggregated Usages ودي برضو قاعدة بيانات منفصة.
بس للأسف ظهر عندهم 3 مشاكل:
1- قابلية التوسع في معالجة البيانات (Processing Scalability)
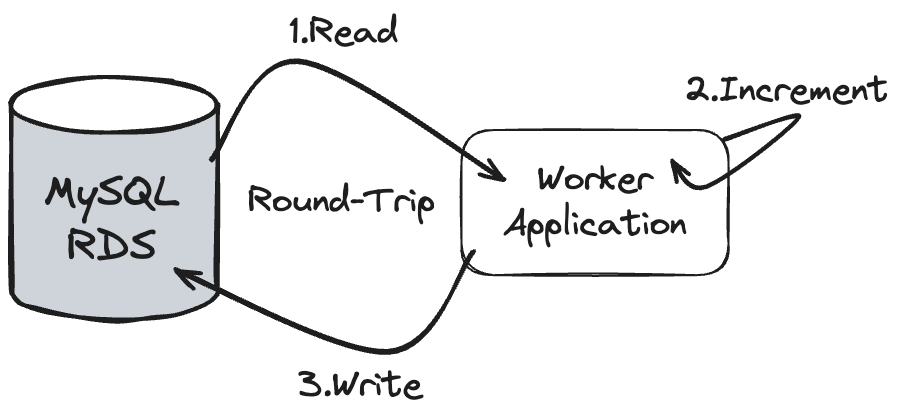
كل record عشان يحصله processing أو معالجة كان بيتطلب round-trip رايح جاي من الـ Database، وده كان غير عملي مع زيادة الحجم الضخم للـ events.
Processing Scalability - Database Round Trips
2- التعامل مع الـ Incidents
أي مشكلة كانت بتحصل كانت معقدة وبتاخد وقت كبير للتعامل معاها. وده لإن المهندسين كانوا مضطرين يبصوا في الـ Database ويشوفوا المشكلة فين ويصلحوا الـ data اللي فيها مشكلة. وقدروا إنهم يعملوا categorization لأنواع المشاكل اللي بتحصل وكانت كالآتي:
مشكلة الـ Overcounting: الزيادة بتحصل لما الـ (Event Source) يضيف نوع جديد من الـ event المفروض إنه ما يتمش حسابه، والـ (Consumers) مايعرفوش ده. النتيجة إنه النوع الجديد ده بيتحسب بالغلط في مراحل الـ Deduplication والـ Aggregation.
وطبعًا عشان يعالجوا النوع ده من المشاكل:
أول حاجة بيحددوا الـ events اللي اتحسبت بالغلط ويقفوا الـ Pipeline بتاع الـ Deduplication والـ Aggregation.
بعد كده بيحسبوا عدد الـ events اللي اتعالجت بالغلط ويشيلوها من جدول الـ Deduplication ويصححوا البيانات في جدول الـ Aggregation.
العملية دي بتاخد وقت ومجهود كبير من فريق المهندسين.
مشكلة الـ Undercounting: أحيانًا بيتم إضافة نوع جديد من الـ events اللي المفروض يتحسب في عملية الدفع، ولكن الـ (Event Source) فشل بطريقة ما إنه يـ integrate مع الـ (Usage Services)، وبالتالي الـ events دي ما بتتجمعش.
وطبعًا عشان يعالجوا النوع ده من المشاكل:
بيحددو ا الفترة الزمنية اللي فيها البيانات المفقودة (Missing Data Window).
بعد كده بيبجيبوا البيانات دي من (Backup Data Source)، ودي أكتر خطوة بتاخد وقت ومجهود.
بعد ما يتم جمع البيانات من الـ Backup، بيرجعوها للـ Service مرة تانية المسئولة ويبدأوا يعيدوا معالجتها.
طبعًا لو حجم البيانات كبير، العملية دي ممكن تاخد أيام، وده ممكن يأخر الدفع بسبب مشاكل الأداء اللي اتكلمنا عنها قبل كده.
مشكلة الـ Misclassification: الخطأ ده بيحصل أثناء مرحلة الـ Deduplication، لما event معين (Usage Event) المفروض يتصنف على إنه نوع "A" ويتم تصنيفه بالغلط على إنه نوع "B". المشكلة هنا إنهم بيدفعوا أسعار مختلفة على حسب النوع.
والنوع ده من الأخطاء شائع جدًا لأن الـ classification rules اللي ذكرناها بتتغير باستمرار.
وطبعًا عشان يعالجوا النوع ده من المشاكل:
أول حاجة بيحددوا سبب المشكلة، وغالبًا ده بيكون Bug في الكود.
بيصلحوا الـ Bug وطبعًا يوقفوا الـ Pipeline.
بعد كده بيصححوا البيانات في جدول الـ Deduplication وجداول المراحل اللي بعد كده عن طريق إعادة حساب البيانات مرة تانية.
العملية دي مرهقة جدًا وبتاخد أيام، وبتحتاج أكتر من مهندس علشان يتأكدوا من صحة البيانات بعد التصليح.
مشكلة الـ Processing Delay: دي مشكلة Performance بسبب إن المعالجة كانت بتعتمد على عملية Sequential بتتم من خلال الـ (Single-threaded Sequential Scan) ومع عدد كبير من الـ round-trips بين الـ Service وقاعدة البيانات.
السرعة ممكن نقول معقولة في الظروف العادية، لكن أحيانًا الـ Worker بتاع الـ Deduplication أو الـ Aggregation ممكن يعطل ويهنج لأسباب مختلفة، زي وجود بيانات غير متوقعة في الـ events، وده كان بيأخر كل مراحل الـ processing اللي بعد كده.
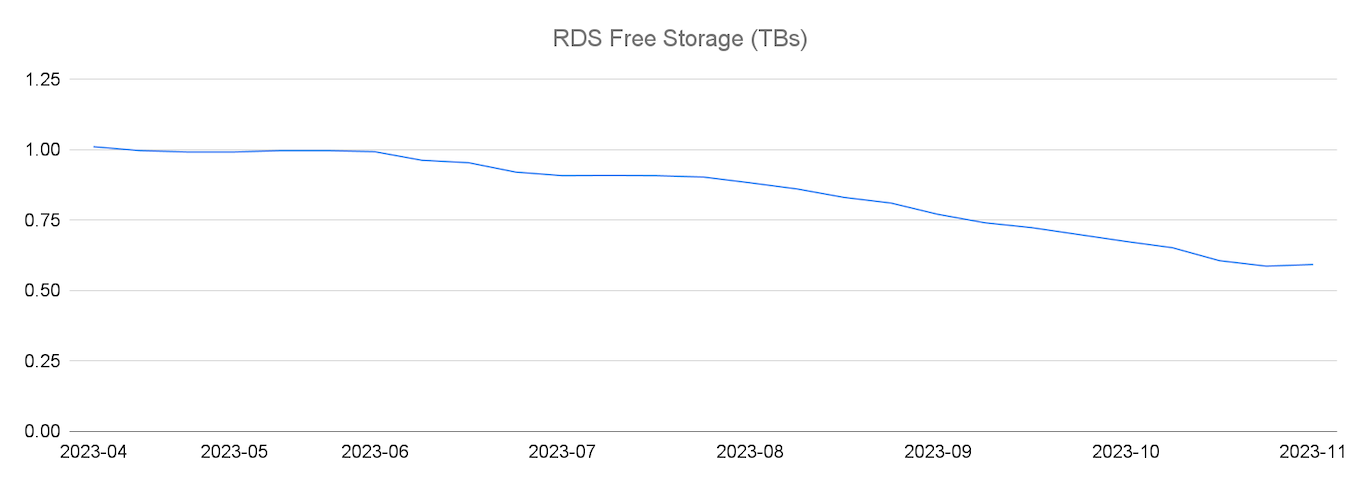
3- استهلاك التخزين
مساحة التخزين في MySQL RDS كانت بتتستهلك بسرعة جدًا، والمشكلة إن MySQL مش بتعمل Horizontal Scaling من خلال الـ Partitioning بشكل تلقائي على سبيل المثال. فكان الحل مضاعفة حجم الـ RDS Instance كل 8-10 شهور.
ولكن لما حجم البيانات وصل لعدة terabytes، بقت الصيانة أصعب بكتير. وعشان الـ Database كانت اصلا بيتم مشاركتها مع Critical Features تانية فكان أي Downtime بيحصل بيسبب مشاكل كبيرة للـ Functionalities التانية.
وطبعًا عشان يعالجوا النوع ده من المشاكل:
قسموا قواعد البيانات (Database Split) علشان يوزعوا الحمل.
عملوا أدوات زي الـ (Sweepers) بتنضف البيانات القديمة من فترة للتانية.
بس مع زيادة عدد الـ events بشكل كبير، كان واضح إن الحل ده مش هيكمل على المدى الطويل.
مبدئيًا عشان يحلوا مشكلة الـ Scalability اللي كانت ظاهرة بشكل مستمر ، أول حاجة عملوها هي إنهم نقلوا الـ Raw Usage Events اللي كانت في مرحلة الـ Collection لـ DynamoDB وده ساعد في تقليل الضغط على مساحة التخزين اللي كانت بتتزايد بشكل مستمر.
المرحلة التانية كانت إنهم ينقلوا باقي البيانات كذلك للـ DynamoDB وطبعًا ده للأسف كان هيخليهم يضطروا إنهم يعملوا Re-write لمعظم الـ Codebase.
فبعد تفكير في المميزات والعيوب قرروا إنهم مايمشوش في الاتجاه ده ، والسبب الأكبر كان أثناء الانتقال لـ DynamoDB ده هيعالج مشكلة مساحة التخزين والـ Scalability المتعلقة بيها ولكن احنا ناسيين نقطة مهمة ألا وهي:
معالجة البيانات بشكل Scalable هتفضل مازالت تحدي قدامهم بسبب الـ Database Round-Trips اللي بتتم أثناء المعالجة.
Simplify using OLAP and ELT
في النهاية قرروا إنهم يغيروا من طريقة تفكيرهم ويقوموا بعمل دمج للمرحلتين الـ Deduplication والـ Aggregation من خلال Service تعمل end-to-end calculation باستعمال الـ raw usage events اللي هي المصدر الأساسي للبيانات.

















{kind=link}