

تخيل ان عندنا مجموعة ضخمة من الكتب , والكتب دي محطوطة على أرفف المكتبة بشكل عشوائي تمامًا , تقدر تتخيل مدى صعوبة أن كل شوية اما نحتاج ندور على كتاب معين هتكون عاملة ازاي ؟
الموضوع هيكون صعب جدًا مش كده ؟
عشان كده لولا الـ Indexing في الـ Database كان زمانا دلوقتي في كل Web Page محتاجين نعمل عليها أي عملية متطلبة انها تـ Fetch Data من الـ Database مستنيين كتيير ومش بعيد بالساعات على ما العملية تتم بنجاح
ما هو الـ Indexing ؟
خلونا نرجع لمثال المكتبة والكتب المحطوطة بشكل عشوائي , ايه رأيكوا لو عملنا تغير بسيط هنا , وهو أننا هنبدأ نعمل فهرسة للأرفف دي , ونديلها ارقام بناء على اسامي عناوين الكتب , وليكن عناوين الكتب اللي بادئة بحرف A تبدا من الرف رقم كذا لرقم كذا ,, مش الموضوع هيكون اسهل ؟
طب ماذا لو زودنا كمان طريقة للفهرسة وهي إننا نحدد الأرفف من خلال الأرقم + نحط كل Category مع بعض , يعني كتب التاريخ في مكان وكتب علم النفس في مكان , والروايات في مكان تاني ,, وكل واحد من دول هيترقم برضو وفقًا لعنوان الكتاب والحروف الأبجدي ,,
مش كده الموضوع هيبقى ـسهل كتير ؟ لو انطلب مننا ندور على كتاب دلوقتي , كل اللي محتاجين نعرفه هو بيتكلم في مجال إيه + عنوانه عشان نعرف أول حرف من اسمه , وبالتالي هنروح للمكان المطلوب,,
فبدل ما نروح نعدي على كل كتب المكتبة عشان ندور عليه , روحنا لمكان مخصص ومحدد بعينه واحنا واثقين تماما اننا هنلاقي الكتاب ده هناك , لانه محطوط Physically هناك على الرف ده,,
وهي دي ببساطة فكرة الـ Indexing
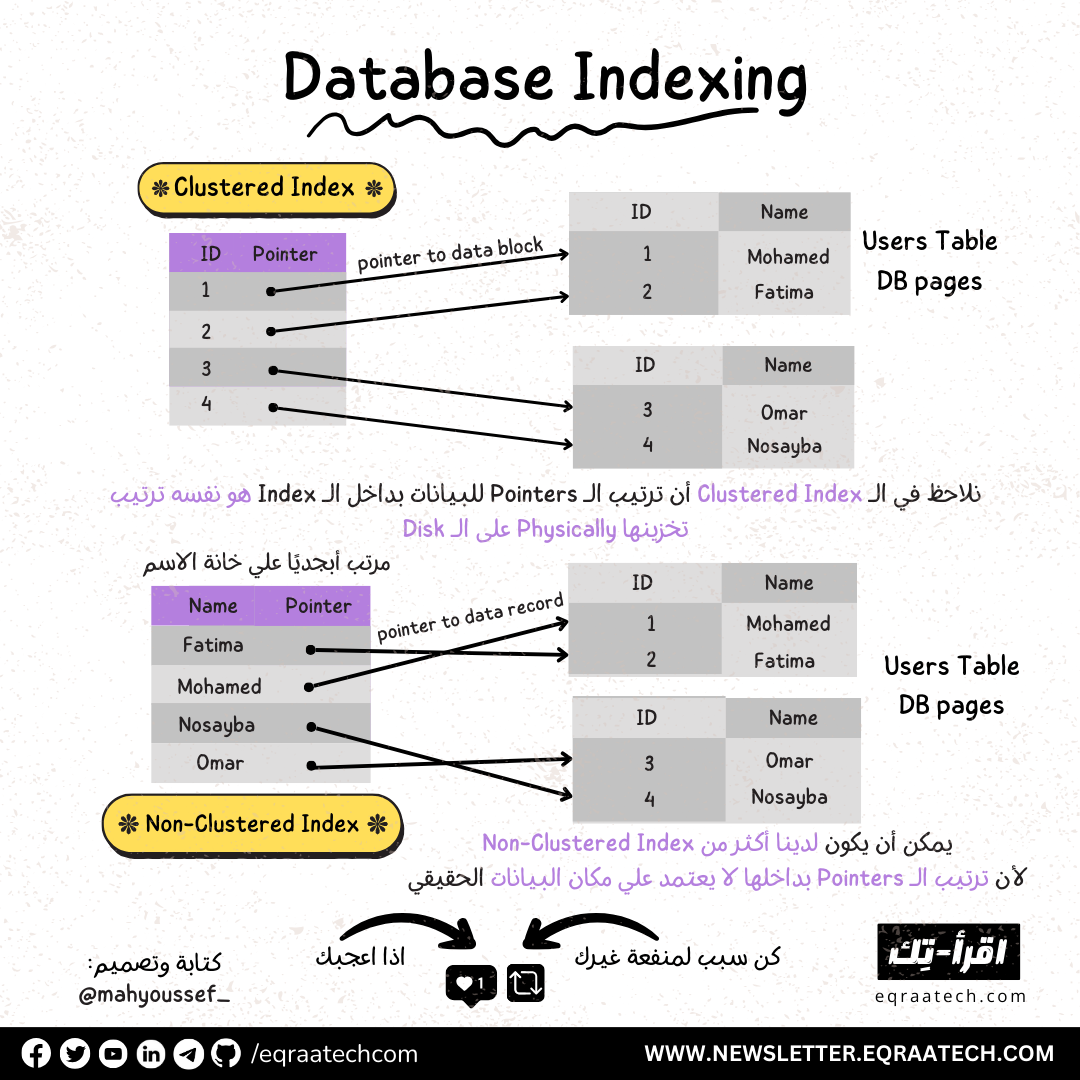
شكل ال Indexing في عالم الـ Database
تخيل دلوقتي قاعدة بيانات بحجم Facebook أو قاعدة بيانات لشركة وفيها عدد من الموظفين , لو انت بتدور على فلان , فهل هتحب ان قاعدة البيانات تاخد الـ Query بتاعتك وتروح تعدي عليهم كلهم واحد واحد لحد ما تلاقيه ؟ طب لو هم كانوا ملايين من الناس ؟ الموضوع هيقعد بالدقايق وممكن يطول صح ؟
فاحنا عشان نسرع من عملية البحث دي ونجيب الـ Data بسرعة ونحسن من أداء الـ Query بنتجه لاننا نعمل حاجة اسمها Indexing عاملة بالظبط زي موضوع ترتيب الكتب في المكتبة , وهي هياها الـ Index في الكتاب اللي بتبص عليه عشان تروح لصفحة بعينها ( عرفتوا دلوقتي فكرتها جت منين ؟ )
فمن خلال الـ Indexing بنقول للـ Database الجدول اللي اسمه Employees أو Users انا عاوز اعمل فهرس عليه من خلال الـ Firstname أو والله محتاج اعمل فهرس عليه من خلال Field تاني أنا مهتم بيه ,,
وده لأني هعمل عمليات قراءة كتير هتطلب إني ادور بالـ Field ده مثلا , فتقوم الـ Database هنا عاملة حاجة جميلة اوي , بتديلك خيارين حاجة اسمها Clustered Index وخيار تاني اسمه Non-Clustered Index
ما الفرق بين الـ Clustered Index و الـ Non-Clustered Index
الـ Clustered Index دي الـ Data Physically متفهرسة ازاي على الـ Disk اما الـ Non-Clustered Index وده بيكون Pointer لمكان الـ Data على الـ Disk وليس الـ Data Physically , فبيكون زي فهرس شايل عنوان البيانات موجودة فين بالظبط ,,
خلونا نشوف مثال على الـ Clustered Index / Non Clustered Index في الـ Database وفي مثال المكتبة والكتب
الـ Clustered Index لقواعد البيانات والـ Default لكتير منها بيكون على الـ ID Field للـ Row ومعظم قواعد البيانات ان لم يكن كلها بتسمحلك بـ Clustered Index واحد فقط لاغير وممكن انت تخلي على اي Field تاني غير الـ ID مش مشكلة
فأنت ممكن يكون عندك Indexing على مثلا الـ Age / Email لأن دول اكتر حاجتين أنت محتاج تدور بيهم على البيانات ومحتاج عمليات الـ Reading من خلال الـ Queries تكون سريعة ,, فدول هيكونوا الـ Non Clustered Index بتاعك ,, في حين انت مش محتاج تغير الـ Clustered Index فهتسيبه زي ما هو بالـ ID وده لان احيانا كتير هتحتاج تدور وتقارن في الـ Queries بالـ ID ده ,,
لو جينا نشوف الكلام ده في المكتبة والكتب هيكون عامل إزاي هيكون الموضوع لذيذ جدًا
خلونا نتخيل إن احنا عندنا المكتبة زي ما قولنا فوق عملنالها فهرسة من خلال الـ Category او Genre بمعنى أدق ونقول هو ده الـ Clustered Index بتاعنا , لان أي حد هيحتاج كتاب أول حاجة محتاجين نعرفها هو بيتكلم عن ايه , فده هيسهل علينا المشوار إننا نروح للمكان ده .. وهنقول إن الكتب هتكون مرصوصة بناء على الأبجدية ومترتبة فسهل وقتها نعرف من اسم الكتاب هنلاقيه فين بسهولة ,,
الـ Non Clustered Index
تخيل معايا إنك عملت فهرسة تانية بناء على أشهر الكتب او أحدث الكتب , والناس كل ما بتيجي تسالك الاقي الكتاب ده فين , أنت عملت فهرسة من خلال ورقة تقدر تبص عليها تقولك الكتاب الفلاني هتلاقيه في المكان الفلاني في الرف ده , كده انت بقيت بتشاور على مكان الكتاب وليس الكتاب ذات نفسه ,, فده بنسميه Non-Clustered Index هو بيحسن سرعة الأداء جدًا ولكنه مش بيودينا للـ Data Directly ولكن هو Pointer يعني بيشاور على مكان اللي محطوطة فيه الـ Data Physically
بكده نكون خلصنا كلام عن الـ Indexing وعرفنا إن عندنا نوعين من الـ Indexing وهم الـ Clustered Index / Non-Clustered Index

















Discussion