

المقدمة
علم الإحصاء هو البوابة لفهم البيانات الكبيرة واستخدامها فيما بعد في الذكاء الاصطناعي. بينقسم إلى نوعين؛ الإحصاء الوصفية اللي بتبسط الداتا والإحصاء الاستدلالية اللي بتضع فرضيات معينة وتختبر صحتها فيما بعد.
بعد ما البيانات بتتجمع من مصادر عشوائية ومختلفة بيصعب التعامل معاها حتى بعد ما تعدى بمراحل ال Cleaning والمراحل المبدأية لفهمها، دا له سببين:
- إن البيانات غامضة جدًا فبنعمل تحليل استكشافي ليها (EDA) واللي بيعتمد بشكل كامل على الأساليب الإحصائية وقوانينها.
- إن البيانات تكون كبيرة وفي تزايد مستمر ولحظي زي بيانات السكان مثلًا؛ عدم توافرها كلها بيصعّب علينا تجميعها ورصدها.. ودا بنحله بأخذ عينة عشوائية صغيرة وإيجاد العلاقة بينها وبين البيانات الكبيرة والمتزايدة دي.

The Exploratory Data Analysis (EDA) Magic Funnel
بداية وتعريف علم الإحصاء
في كل حالة من الحالات كان علم الإحصاء هو البوصلة اللي بتوجهنا للطريق الصح دايمًا؛ الإحصاء هو علم قديم جدًا منتشر من زمان بشكل بديهي وبسيط عند البشر وتم تطويره لاحتياجنا الدائم ليه، بدأ من أول ما كان الإنسان قديمًا بيلاحظ ظهور أشياء غريبة في أوقات معينة من اليوم، فكان يتجنب أوقات ظهورها ويتنبأ بيها في أحيان أخرى في محاولات مستمرة لحماية نفسه..
بنفس منطق ملاحظة البيانات القديمة والاستفادة منها في المستقبل، تطورت الإحصاء إلى أن أصبح علم كامل من علوم الرياضيات لأنها بتطبق مفاهيم الرياضيات التطبيقية والعملية.
لحد ما أصبحت بتوجهنا بشكل أساسي للقرارات المهمة في الكثير من المجالات على حسب نوعها ودورها في المجال دا.
البيانات من وجهة نظر الإحصاء
الإحصاء بشكل عام بتتعامل مع البيانات الرقمية، عشان كدا في البداية مهم نحدد نوع البيانات المستخدمة وفهمها كويس لتحديد الأساليب الاحصائية المناسبة للتعامل معاها..
البيانات بتنقسم إلى نوعين:
- البيانات النوعية (Qualitative Data): هي بيانات وصفية لا تحتوى على أرقام، مثل التقدير الدراسي، نوع المهنة.. وهنا الإحصاء بتستخدم التوزيعات التكرارية (Frequency Distribution) لتوضيح عدد مرات تكرار كل قيمة وصفية في البيانات.
من تطبيقاتها العملية: تحليل استطلاعات الرأي المعتمدة على تصنيفات محددة زي رأي العملاء في خدمة معينة سواء بالإيجاب أو بالسلب.
- البيانات الكمية (Quantitative Data): ودي بيانات بتحتوي على أرقام وقيم عددية وبتنقسم لنوعين:
- بيانات نقدر نحصرها في أرقام معينة زي عدد الأشخاص أو عدد السيارات مثلًا ودي اسمها البيانات المتقطعة (Discrete Data).
- تاني نوع هو البيانات المستمرة (Continuous Data) وهي بيانات بنعبر عنها بمجموعة أرقام ولكن في نطاق من القيم ، زي مستويات درجات الحرارة والفئات العمرية والوزن.

النوع دا من البيانات بنستخدم معاه أساليب إحصائية زي ال mode وال median وال standard deviation هيتم مناقشتها فيما بعد.
من تطبيقاتها العملية: تحليل أسعار المنتجات واستهلاك العملاء ليها والتنبؤ باحتياجنا لمنتج معين بكثرة في المستقبل بمساعدة قوانين الإحتمالات (Probabilties).
نتيجة لاختلاف أنواع البيانات؛ ظهرت بالتبعية أنواع كتيرة من التحليلات اللي بتعتمد بشكل أساسي على علم الإحصاء عشان تناسب الاختلافات دي.
الإحصاء بتنقسم إلى نوعين أساسيين:
أنواع الإحصاء
الإحصاء الوصفي(Descriptive Statistics)
بنستخدمه لما تكون البيانات كاملة وعندي القدرة على التعامل معاها كلها ولكن بتكون عشوائية، دورها هنا بيكون تبسيطها وتحويلها لبيانات قابلة للفهم.
الأساليب المستخدمة في الإحصاء الوصفي:
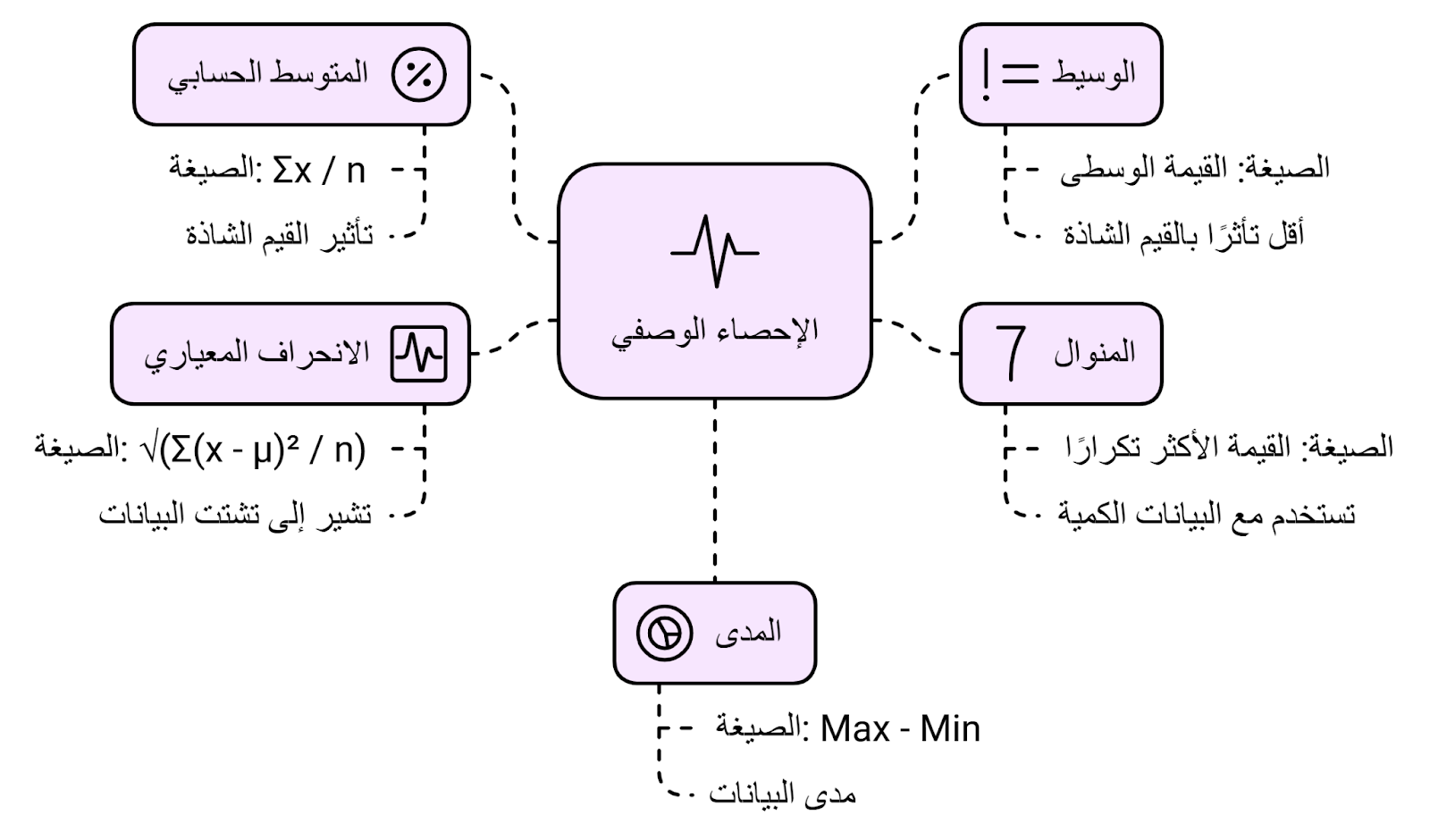
- المتوسط الحسابي (Mean): وهو مجموع القيم على عددها، بيتم استخدامه لمعرفة المركز العام للبيانات والقيم اللي بتتوجه ليها، المتوسط بيتأثر بوجود قيم شاذة لأننا بنلاقي قميته منحاذة ليهم وغير معبرة عن قيم أغلبية البيانات.
مثال: مجموعة قيم 2،3،5،6،100 ، لو حسبنا المتوسط فهيكون 23.5 ودي قيمة بعيدة عن معظم القيم الفعلية فبالتالي مش هتكون أصح حاجة تعبر عن البيانات.
- الوسيط (Median): وهي القيم اللي بتقسَم البيانات إلى نصفين متساويين بعد ترتيبها وبيكون أقل تأثرًا بالقيم الشاذة والمنحرفة عن البيانات.
لو أخدنا المثال السابق: الوسيط هيكون 5 وهي قيمة قريبة ومعبرة عن معظم البيانات الموجودة.
- المنوال (Mode): بيعبر عن القيم الأكثر تكرارًا وبيستخدم مع البيانات الفئوية اللي ناقشناها في البداية.
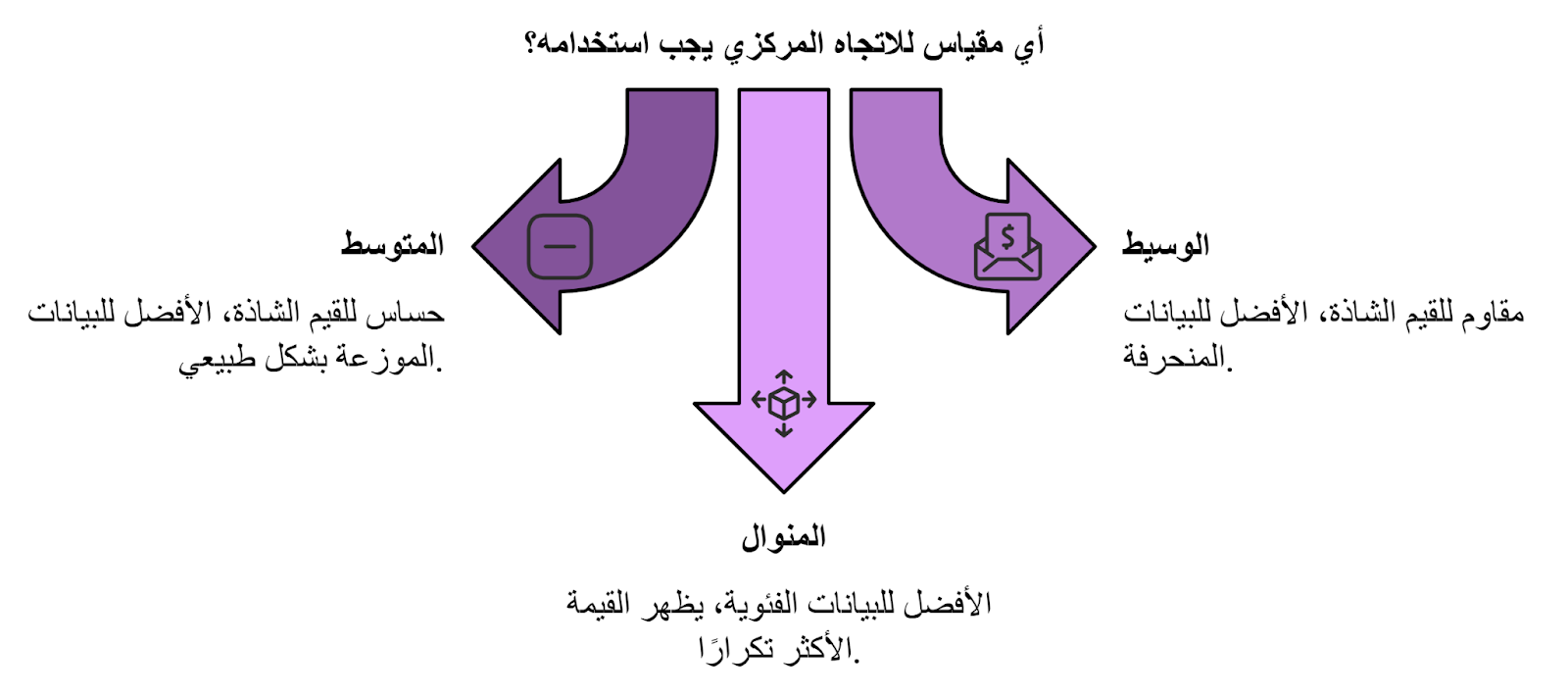
- الانحراف المعياري (Standard Deviation): بيعبر عن مدى اختلاف وتشتت البيانات عن المتوسط، يعني لو قيمته عالية ف دا دليل على إن البيانات متباعدة عن متوسط القيم.
- المدى (Range): قيمته بتساوي الفرق بين أكبر قيمة وأصغر قيمة في البيانات، بيُعتبر مؤشر لمدى لانتشار البيانات.
الشكل الآتي بيوضح قوانين وخصائص كل منهم:
الإحصاء الاستدلالي (Inferential Statistics)
النوع دا من الإحصاء بيقدم توقعات واستنتاجات حول بيانات غير معروفة بشكل كامل، دا بيكون بسبب صعوبة تجميعها بشكل كامل زي بيانات التعدادات السكانية أو استطلاعات الرأي حول شيئ معين.
طيب دا بيتم إزاي؟
عن طريق تطبيق أساليب الإحصاء الاستدلالي على عينة من البيانات بيتم اختيارها بأساليب محددة بحيث تعبر مجازًا عن باقي البيانات المفقودة، طبعًا بيتم تقييم الاساليب دي وفحص كفاءتها..
الأساليب المستخدمة في الإحصاء الاستدلالي:
- اختبار الفرضيات (Hypothesis Testing): الأسلوب دا في البداية بيحط فرضية للتعبير عن البيانات الموجودة وبعد كدا يبدأ يختبر صحة الافتراض دا أو عدم صحته.
مثال: لو افترضت إن متوسط درجات الطلاب هو 55% ولكن المتوسط للعينة عندي هو 70%، مين هنا الصح؟
ببدأ أختبر الفرضيات عن طريق تحديد Rejected Inervals ولو الفرضية بتاعتي كانت في الفترة دي بتكون غلط والعكس صحيح.
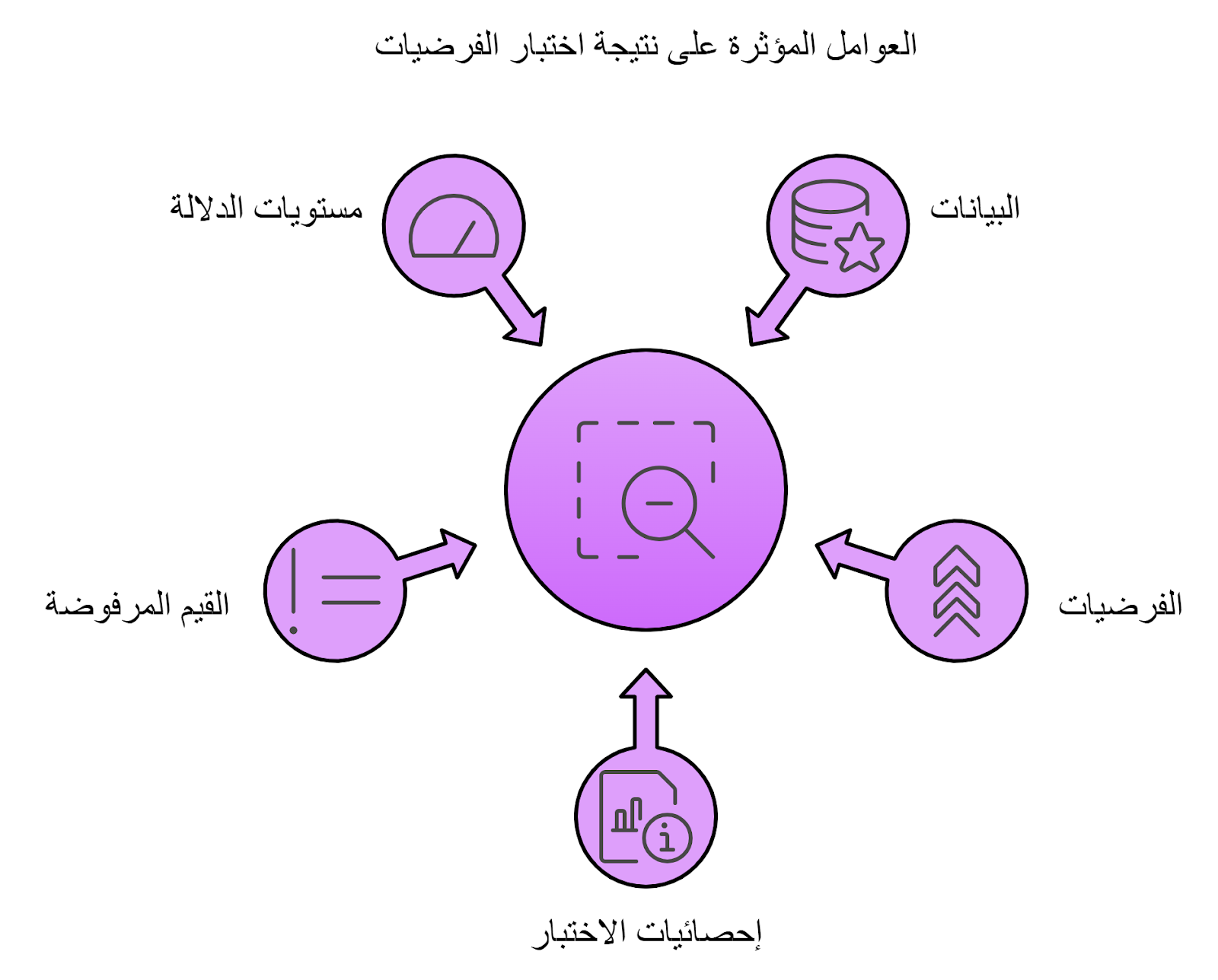
- تقدير فواصل الثقة (Confidence Intervals): في الأسلوب دا بنحدد أكبر مدى ممكن البيانات تكون موجودة فيه حوالين متوسط العينة العشوائية اللي اتاخدت من الداتا.
مثال: لو أخدنا عينة من داتا معينة وحسبنا المتوسط ليها، مش بالضروري إن المتوسط دا يعبر عن متوسط باقي الداتا.. عشان نتفادى الاختلاف دا؛ بنزود القيمة حوالين المتوسط بمقدار معين بحيث يكون عندنا Interval معبرة عن معظم البيانات.
طبعًا كل ما يكون الداتا متقاربة لبعضها_دا بنعرفه من ال Descriptive statistics كل ما تكون ال Interval دي صغيرة.
3) تحليل التباين (ِANOVA): دا بيعمل تحليل للتباين (Analysis Of Varience) بين أكتر مع عينة من البيانات عن طريق إنه بيحسب المتوسطات لكل عينة ويقارنهم؛ التباين هو مربع الانحراف المعياري والاتنين مقياس لتوزيع الداتا.
- تحليل الانحدار (Regression Analysis): بيُستخدم لتحديد العلاقات بين المتغيرات لاستخدامها فيما بعد للتنبؤات المستقبلية، زي تحديد العلاقة بين مبيعات الشركة وعدد المنتجات أو بينها وبين الحملات الإعلانية.
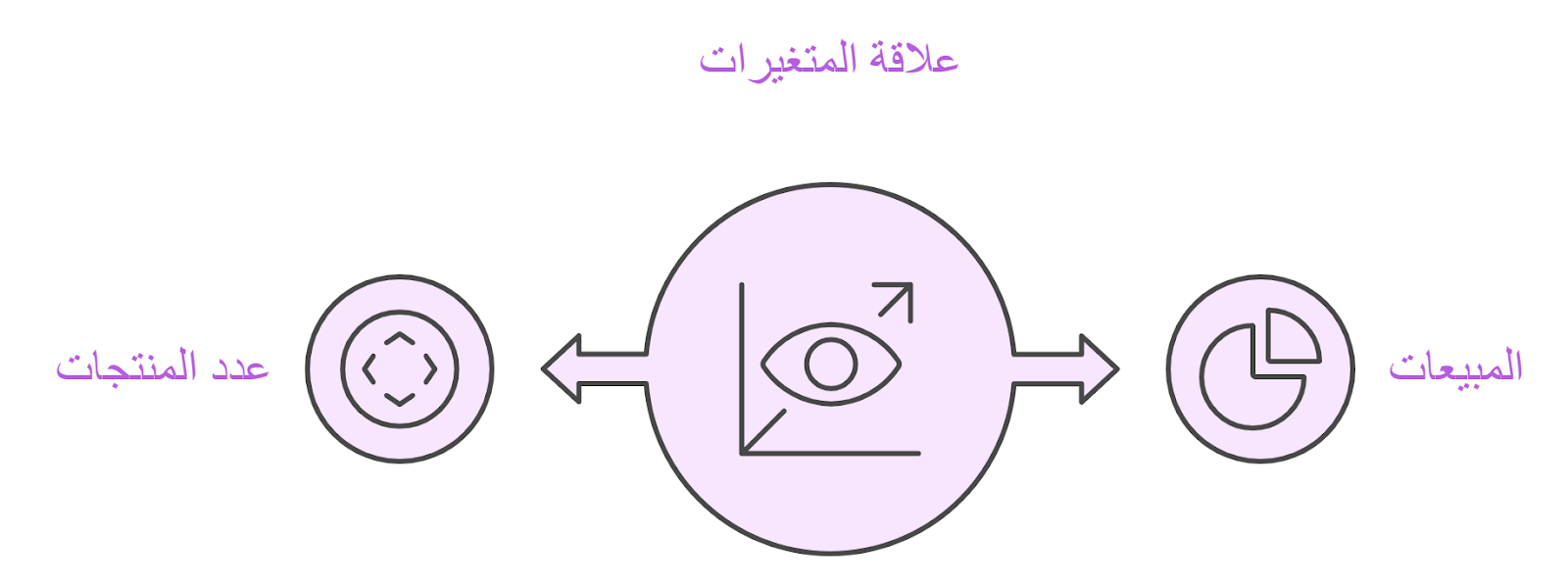
النوع دا من التحليلات الاحصائية كان هو بداية التفكير في علم ال Machine learning وأصبح قائم عليه بمساعدة قوانين ال Probability؛ دا لأن التعلم الآلى مُعتمد بشكل أساسي على وضع فرضيات واحتمالات والتأكد منها بعد كدا.
في الختام
علم الإحصاء هو البوابة لفهم البيانات الكبيرة واستخدامها فيما بعد في الذكاء الاصطناعي.
بينقسم إلى نوعين؛ الإحصاء الوصفية اللي بتبسط الداتا والإحصاء الاستدلالية اللي بتضع فرضيات معينة وتختبر صحتها فيما بعد.
مصادر إضافية وكتب للقراءة:
Statistics Fundamentals

An Introduction to Statistical Learning














Discussion