

الحمد لله الذي علَّم بالقلم، علَّم الإنسان ما لم يعلم، والصلاة والسلام على خير معلِّم الناس الخير محمد — صلَّى الله عليه وسلم … أما بعد،
كما تحدثنا بالمقالة السابقة بأن ال (Power BI) هو الحصان الرابح حاليا في سوق البرمجيات المختصة بتحليل وعرض البيانات، وكما أشرنا بأننا من خلال هذه المقالات – على بساطتها – نحاول أن نلقي حجرا" في الماء الراكد لعل أحدهم يلتقط طرف الخيط ويهب لصنع ما لم نستطع!
فإننا اليوم مع مقالة أخري تقوم بالأساس على شرح مبسط وسهل للتركيب الداخلي لبرنامج (Power BI) لعل أحدهم يستكمل ما بدأنا ونري يوما" ما برنامجا عربيا" يقوم بما يقوم به التطبيق محل النقاش ... بل ... ويكون أفضل!
لماذا؟
حقيقة الأمر أن دراسة التكوين الداخلي ل (Power BI DAX Engines) قد يبدو شيئا" من الرفاهية العلمية التي يظن الكثيرون عدم جدواها لسبب أو لأخر، ولكن هنا أسرد ثلاثة أسباب – أرجو أن تكون منطقية – لأهمية هذه الدراسة التي قد لا أكون مبالغا" إن وسمتها بالضرورية والتي لا غني عنها لاستخدام البرنامج بشكل عالي الجودة والاحترافية:
- معرفة كيفية عمل المحرك الداخلي المسؤول عن تنفيذ الاستعلامات المكتوبة بلغة DAX بالتأكيد سيجعلنا أكثر وعيا" أثناء اختيار الشكل المناسب للبيانات كما" ونوعا" وذلك عند اتخاذ القرار بنقل البيانات من المصدر (Data Import Mode)، أو الاتصال بالبيانات بدون نقلها (Direct Query Mode)، أو حتى العمل بالنظام المختلط (Composite Query Mode).
- السبب الثاني هو أن قدرتنا على كتابة استعلامات DAX أكثر كفاءة – أي تقوم بتنفيذ المهمة المطلوبة في أسرع وقت بأقل استهلاك ممكن للموارد – ستكون أكبر، لأننا قد علمنا كيفية عمل المحرك المسؤول عن تنفيذ ذلك الاستعلام وأصبحت لدينا القدرة على تشغيله بشكل فعال.
- السبب الثالث والأهم من وجهة نظري، هو أن تعمل وأنت في كامل الوعي والقدرة على توقع مخرجات الاستعلام المكتوب، فأنت تعلم بشكل مبدئي ماهي النتيجة وكم من الوقت سيستغرق التنفيذ!
التكوين الداخلي: ماذا بداخل ذلك الصندوق الأسود؟!
دعونا مبدئيا" نقسم البرنامج إلى عدة أجزاء أولية، الجزء الأول وهو ال (Power Query) وهو الجزء المسؤول عن بناء خطوط الإمداد بالبيانات والمعروفة باسم (Extract – Transform - Load) وفي هذا الجزء نستخدم لغة برمجة (M-Language) ومجموعة واسعة من الأزرار الجاهزة لتنفيذ مهام استخراج، تنظيف وتحويل، وتحميل البيانات – وهذا الجزء خارج نطاق هذه المقالة.
الجزء الثاني والخاص بال (Power Pivot) وهو الجزء الخاص بعمل النموذج (Data Model) الذي سيتم من خلاله ربط الجداول ببعضها – وهذا الجزء خارج نطاق هذه المقالة. أما الجزء الثالث، هو ما نعتبره الجزء الخاص بإنشاء كلا" من الأعمدة المستحدثة (Calculated Columns) لإثراء الجداول بمعلومات جديدة لم تكن موجودة بالمصدر الأصلي للبيانات وكذلك القيم الحسابية (Measures) التي تعمل على اختصار عدد كبير جدا" من البيانات في رقم واحد ويتم تغيير هذا الرقم المعروض مع تغيير سياق الفلتر المستخدم (Filter Context) وهذا هو محل دراسة هذا المقال بالتحديد.
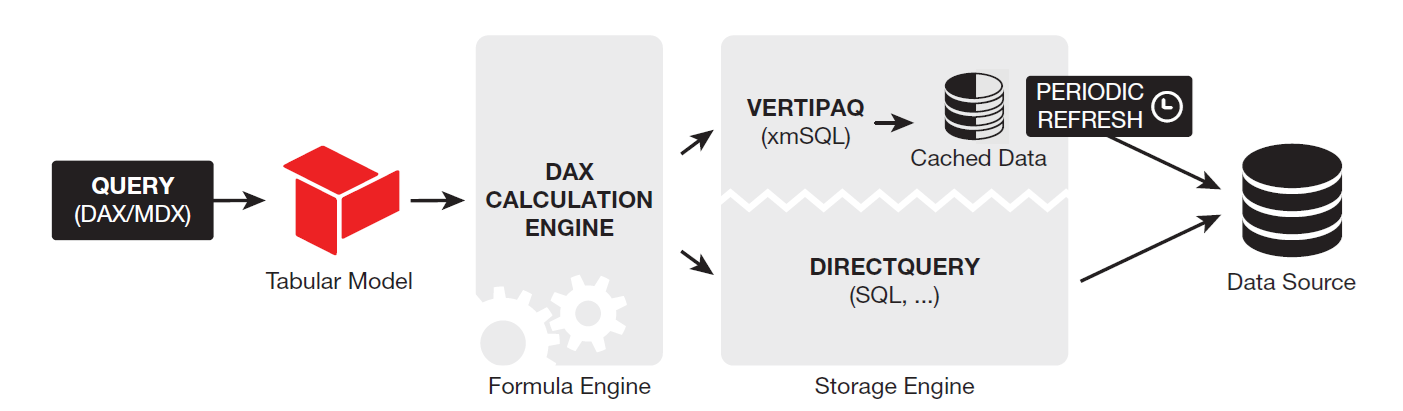
لغة كتابة الاستعلامات (DAX / MDX)
والان، فلنبدئ البداية الصحيحة ... لماذا لدينا لغتين للاستعلامات بالشكل الموضح؟!
الحقيقة ان المحرك الداخلي الموضح بالصورة هو نموذج متواجد بأكثر من منتج من منتجات مايكروسوفت وتحديدا" (Power Pivot in Excel, Power BI, and SQL Server Analysis Service (SSAS)) وعليه فنحن نعلم بأن اللغة المستخدمة للاستعلام في أول تطبيقين هي لغة DAX في حين أن اللغة المستخدمة في التطبيق الأخير (SSAS) هي لغة ال MDX. وبالتالي نحن الأن نعلم بأن ما يسري علي إحدى اللغتين يسري علي الأخرى.
ملحوظة: قد يكون هناك بعض الاختلافات ما بين البرامج الثلاثة، فبعض المميزات المتواجدة بال Power BI ليست موجودة في Power Pivot in Excel وهكذا.
نحن لن نخوض في هذه المقالة في تاريخ اللغتين لأننا نجهز لهذا الأمر مقالة أخري إن شاء الله.
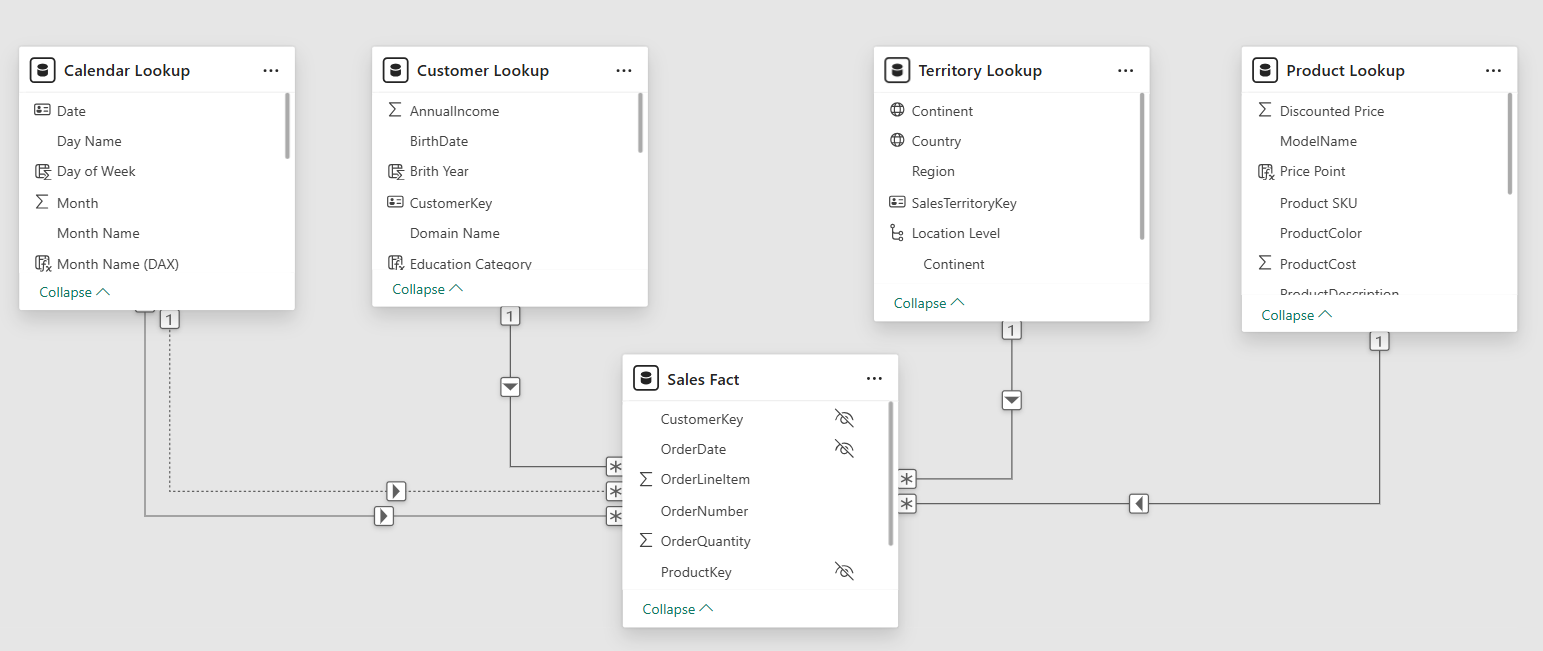
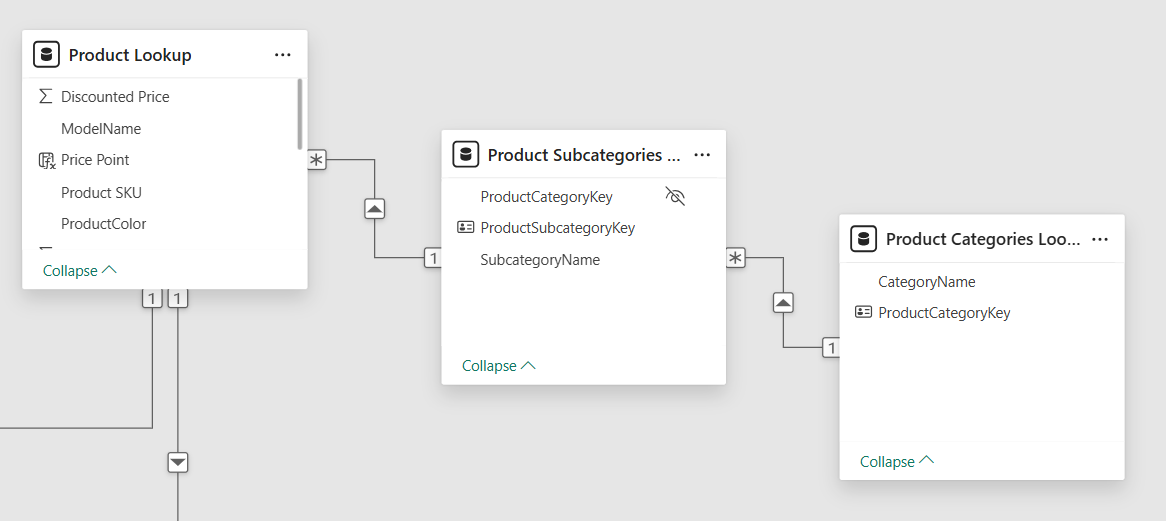
عندما نربط كل شيء معا" (Tabular Model)!
ال (Tabular Model) هو ما يطلق على " مجموع كل الجداول والعلاقات ما بينها داخل ال Excel, Power BI, and SSAS) والتي تعرف ب (Data Models) - وموضح أدناه شكل هذا النموذج في ال Power BI وبه سنجد نوعين من النماذج (Star and Snowflake Schemas) – والاستعلامات التي يتم كتابتها من المستخدم (User Queries)".
محرك معالجة الاستعلامات (Formula Engine)
إذا وبعد أن تعرفنا على الجزئين الأول والثاني من المحرك الداخلي، جاء الأن الدور على الجزء الثالث وهو ال (Formula Engine). ولو أردنا تصور ماهية هذا الجزء - والذي نستطيع تسميته بالعقل – يمكننا تخيله الجزء الذي يتلقى الكود المكتوب بلغة ال DAX ويقوم بفهمها جيدا" واستيعابها وتحديد ما المطلوب تنفيذه بالضبط، وهنا نستطيع تقسيم عملية التنفيذ الي جزئين، الجزء الأول هو المعادلات الحسابية وما فيها من معاملات سواء للمقارنة أو للعمليات الرياضية وما الي غيرها من معاملات والجزء الثاني ويختص بالبيانات التي سيتم إجراء هذه العمليات الحسابية والمقارنات عليها. وبالتالي نستطيع من هنا أن نقول إن ال Formula Engine يقوم بتحديد البيانات المطلوب استرجاعها كمرحلة أولي، حيث لن يتم إجراء أي عمليات حسابية الا على مجموعة من البيانات ... ولكن هنا تظهر مشكلة وهي أن ال Formula Engine لا يمتلك القدرة على التعامل بشكل فعال مع عمليات استدعاء البيانات وبالتالي تظهر هنا الحاجة الماسة لمحرك أخر يقوم ال Formula Engine بتكليفه بمهمة استدعاء تلك البيانات وتمريرها له ومن ثم يقوم هو بتطبيق العمليات الحسابية، الزمنية، المقارنات، إلخ. ومن ثم أرسال النتيجة الي ال Tabular Model ومنه الي المستخدم على شكل Calculated Column أو Measure!
ماذا لو اتصلنا بالمصدر؟ ... (Direct Query Mode)
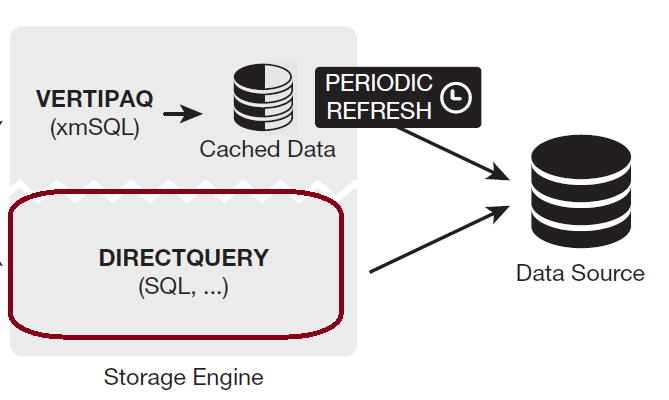
إذا"، وصلنا الي نقطة مفصلية هنا وهي أن ال Formula Engine غير قادر – ولم يصمم من أجل ذلك – على استدعاء البيانات المنصوص عليها داخل الاستعلام لبدء اجراء العمليات الحسابية عليها، وبالتالي يقوم بتكليف ال Storage Engine بهذه المهمة، إذا ما هو هذا ال Storage Engine؟!
ال Storage Engine هو ذلك المحرك الذي أنشئ بالأساس للتعامل مع البيانات داخل Power BI Workflow فهو القادر علي فتح قناة اتصال مباشرة مع مصادر البيانات لمساعدة ال Formula Engine على إجراء العمليات الحسابية على هذه البيانات بالمصدر نفسه وذلك فيما يعرف ب Direct Query Mode.
مثال: إذا قمنا بالاتصال بقاعدة بيانات بها جدول للمبيعات يحتوي على كمية المنتجات المباعة وكذلك سعر كل منتج وقمنا بكتابة استعلام موجه الي Formula Engine بحيث يقوم بحساب إجمالي مبلغ المبيعات خلال فترة زمنية معينة فان الخطوات ستصيح كالتالي – في حالة الاتصال بمصدر البيانات Direct Query Mode:
- يقوم ال Formula Engine باستقبال الاستعلام ومن ثم توزيع المهام.
- المهمة الأولي ستكون ل Storage Engine وهي فتح قناة الاتصال مع مصدر البيانات.
- ثم يقوم ال Storage Engine بالطلب من مصدر البيانات بأن يقوم بتطبيق الفتر الخاص بالفترة الزمنية الموضحة بالاستعلام لضمان عدم تواجد أي بيانات غير مطابقة لهذا الفلتر الزمني.
- ثم يقوم ال Storage Engine بالطلب من مصدر البيانات أن يقوم بإجراء عملية حسابية على مستوي كل صف من الصفوف المختارة وفقا" للمعادلة (سعر المنتج المباع * الكمية المباعة).
- ثم يقوم مصدر البيانات بعمل عملية الجمع لكل القيم الناتجة من العملية الحسابية على مستوي كل صف وايجاد الإجمالي.
- ثم يقوم ال Storage Engine بإرسال النتيجة الإجمالية الي ال Formula Engine ليقوم بدوره بإرسالها الي Tabular Model ومنه الي المستخدم.
وهنا نلاحظ عدم انتقال أي بيانات من المصدر الي Power BI وهنا عدة مميزات وعيوب دعونا نناقشها سريعا:
المميزات
- عدم نقل البيانات يعني بالضرورة عد استخدام موارد الجهاز الذ خرج منه الاستعلام وخصوصا موارد الذاكرة.
- الاعتماد على المحرك الداخلي لمصدر البيانات وفي هذه الحالة هو Database Management System سيكون له عظيم الأثر في عمل الحسابات بشكل أسرع وأقوي.
- عند الاتصال بالمصدر يقوم ال Storage Engine بعمل ما يعرف باسم Query Folding وهو كتابة كود بلغة SQL على ان يكون هذا الكود فعال جدا" ليصبح هو الوسيلة لإجراء معالجة البيانات والحسابات بشكل فعال وسريع.
العيوب
- الاتصال بالمصدر والاعتماد عليه عند تنفيذ كل استعلام سيكون بالضرورة أبطئ.
وبالنهاية، في هذا النظام – Direct Query Mode – الاعتماد الأكبر يكون على موارد المصدر الذي تأتي منه البيانات وكما قولنا لهذا مميزاته وعيوبه.
ماذا لو نقلنا البيانات من المصدر إلينا؟ ... (Import Mode)
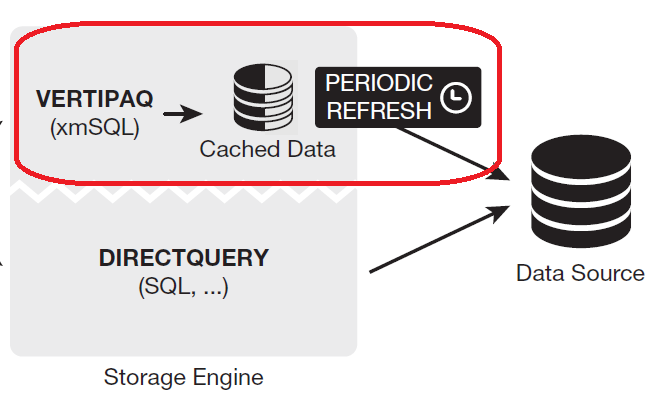
بما اننا قد ذكرنا بالفقرة السابقة ان الخيار الأول هو الاتصال بالمصدر واستخدامه في عملية معالجة البيانات واجراء العمليات الحسابية فإننا في هذا الجزء من المقال سنتطرق الي الخيار الثاني وهو استدعاء البيانات من المصدر الي جهازنا الذي يعمل عليه ال Power BI فيما يعرف باسم Data Import Mode وهنا لنا وقفة!
في هذا النظام تكون الخطوات كالتالي – ارجو التركيز لأننا قد نكون أصحاب القرار الذي يؤدي الي أداء أفضل أو أسوء أثناء هذه المرحلة!
- عند بناء ال ETL Pipeline فنحن نقوم بتحديد الجداول التي سنستدعيها الي ال Data Model وهنا يأتي الدور البشري في فهم كيفية بناء ETL بشكل فعال وغير مكلف – سنري التكلفة من أين تأتي خلال السطور القادمة.
- عند استدعاء تلك الجداول نقوم بتفعيل نظام Data Import Mode وبالتالي يتم الاستعداد لتحميل هذه الجداول من البيانات الي الذاكرة العشوائية الخاصة بالجهاز الذي يعمل عليه ال Power BI.
- لماذا قلنا يتم الاستعداد لتحميل البيانات ولم نقل يتم التحميل مباشرة؟ هنا تأتي كلمة السر ومحل النقاش بهذه المقالة – ال VertiPaq وهو الخوارزمية الخاصة بتجهيز البيانات المستدعاه لتحميلها الي الذاكرة العشوائية للجهاز، وهنا تبدأ المقالة!
محرك إدارة الذاكرة (VertiPaq) ... إذا، أين مكمن القوة؟!
محرك إدارة الذاكرة VertiPaq يقوم بعمل شيئين عظيمين من أجل Power BI أسرع وأداء أفضل، هاذين الشيئين هما في بعدين مختلفين:
- البعد الأول هو خاص بألية تخزين البيانات نفسها وهنا لابد وأن نشرح الفارق ما بين الطريقتين:
- طريقة التخزين الأفقية – وهو تبسيط مخل أعتذر عنه – وتعرف ب Row Level Storage وهي تستخدم في قواعد البيانات وكذلك في Excel.
- طريقة التخزين الرأسية - وهو تبسيط مخل أعتذر عنه – وتعرف ب Column Level Storage وهي تستخدم في بعض قواعد البيانات المعروفة باسم Columnar Database والان عرفنا انها تستخدم أيضا في ال Power BI.
- البعد الثاني هو محاولة تخزين أكبر قدر ممكن من البيانات في أقل حيز ممكن من ذاكرة الوصول العشوائي RAM وبالتالي زيادة فعالية عملية التخزين – فالفعالية هي عملية تعظيم المخرجات بأقل مدخلات ممكنة.
صفوف أم أعمدة، أيهما أفضل؟
إذا البعد الأول كما ذكرنا له علاقة بطريقة تخزين البيانات نفسها ما بين ال Row Level Storage او ال Column Level Storage وهنا لابد من شرح المر بالتفصيل لنفهم اين مكمن الكفاءة الخاص ب VertiPaq.
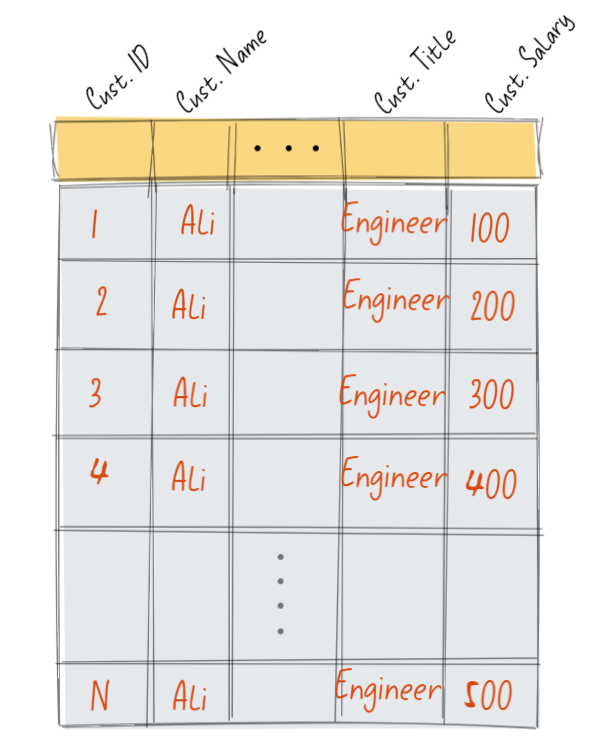
كما هو موضح بالصورة، جدول به مجموعة من البيانات والتي سيتم تخزينها في ملف Excel وبالتالي سيكون التخزين باستخدام طريقة ال Row Level Storage.
والان تخيل معي للحظة صديقي العزيز اننا نريد أن نحسب إجمالي مرتبات المهندسين بنفس الاسم (علي)، كيف سيكون الأمر؟
- سيقوم المحرك الداخلي لبرنامج الإكسيل بتحديد مكان تواجد البيانات بالذاكرة وتحديد بداية ونهاية كل صف من الصفوف وهي تكون متراصة بنفس ترتيب البيانات.
- سيقوم بالمرور على الصف الأول خلية بعد خلية بدءا" من خلية ال Cust. ID ومن ثم وبعد قراءتها سيخلص الي ان هذه الخلية ليست هي المطلوبة وبالتالي سيقوم بتجاهلها والانتقال الي الخلية التالية وهي Cust. Name.
- بعد قراءة الخلية الثانية والتأكد من عدم مطابقتها للبيان المستهدف سيقوم بتجاهلها ثم الانتقال للخلية التي تليها وهي Cust. Title والتي بدورها سيتم تجاهلها.
- حين يصل الي الخلية الأخيرة بالصف الأول وهي Cust. Salary سيتأكد من انها هي المستهدفة وبالتالي سيقوم بقراءة القيمة بداخلها ووضعها في مكان مخصص حتي يتم جمع باقي القيم عليها واحدة تلوا الأخرى ثم ينتقل للخلية الأولي بالصف الثاني وهكذا دواليك.
- يتكرر الأمر بعدد صفوف الجدول وعدد أعمدته.
مثال: إذا كان الجدول عبارة عن 1000 صف و4 أعمدة فإن الخوارزمية المتواجدة بالإكسيل ستقوم بقراءة 40000 خلية ومن ثم تجمع القيم المتواجدة في 1000 خلية فقط حتى تصل الي النتيجة المطلوبة وهنا تأتي المشكلة، نحن لابد من أن نهدر وقتا" يساوي في هذه الحالة 4 أمثال الوقت المستهدف لنقوم بقراءة مجموعة من البيانات غير الضرورية للعملية الحسابية المطلوبة!
ملحوظة: قد يقول قائل: ان الإكسيل به خاصية Cube Calculations والتي تقوم بعمل عديد العمليات الحسابية الجاهزة مثل إيجاد اجمالي، متوسط، عدد، القيمة الدنيا، القيمة العظمي لكل عمود رقمي وتخزينها وجعلها جاهزة بحيث عند الطلب من المستخدم تكون هذه القيم جاهزة، فأقول له: أصبت! ولكن ماذا عند عمل عمليات حسابية معقدة؟!
إذا وما الجديد عند استخدام ال VertiPaq؟
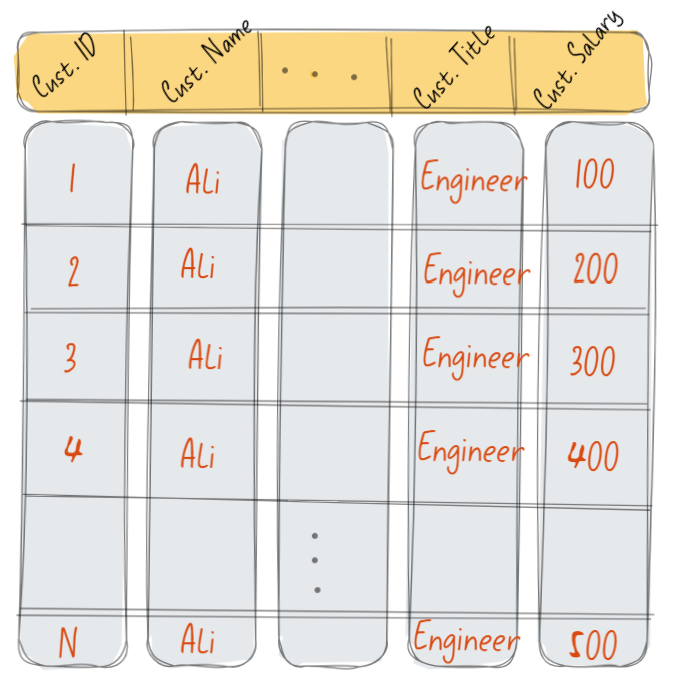
الجديد كما هو موضح بالصورة أننا الأن وباستخدام ال VertiPaq سنقوم بتخزين نفس البيانات، ولكن بشكل مختلف، سيتم تخزينها بشكل يسمح بتخزين القيم المتواجدة في نفس العمود – وليس الصف – في مساحة تخزينية متتالية ومتجاورة بالذاكرة وهنا تأتي الفعالية، دعونا نعيد المثال السابق، ولكن هذه المرة باستخدام ال VertiPaq Columnar Data Storage Algorithm:
- ستقوم الخوارزمية بالتعرف مباشرة على العمود المراد العمل عليه – إيجاد اجمالي مرتبات العملاء.
- بعد هذا التحديد سيتم الانتقال مباشرة الي المكان تخزين القيم المتواجدة بهذا العمود ثم الشروع في جمعها الواحدة تلو الأخرى بشكل مباشر.
- وبالتالي ووفقا" لأرقام المثال السابق سنجد ان الخوارزمية ستقوم بقراءة فقط 1000 قيمة ثم جمعها وهو ما يمثل 25% فقط من زمن القراءة المستغرق في الطريقة السابق ذكرها Row Level Storage!
- والان تخيل معي أن عدد الصفوف صار مليونا"، بل 100 مليون ... كيف الحال إذا؟!
اما البعد الثاني وهو تخزين أكبر قدر ممكن من البيانات داخل أقل حيز ممكن من المساحة سيكون هو موضوع مقالنا القادم ان شاء الله والذي سنتطرق فيه الي خوارزميات ضغط البيانات المستخدمة داخل ال VertiPaq والتي سيكون لها عظيم الأثر في رفع كفاءة وسرعة وأداء ال Power BI إذا فهمناها بشكل صحيح وطبقنا الممارسات الفضلي وفقا" لفلسفتها.
في الختام
وأخير" أرجو أن أكون وفقت الي إيصال الفكرة من المقال وأرجو أن تسامحوني إن أخطأت، وما من توفيق فمن الله وحده وما من خطأ فمني ومن الشيطان.














Discussion