

مع مرور الوقت وزيادة حجم البيانات لا يمكن لجهاز واحد أن يتحمل كل هذه البيانات، فلا بد من زيادة عدد الأجهزة وتخزين البيانات عليها، وهنا يمكننا توزيع الـ Read Requests على أكثر من جهاز فبدلًا من قراءة البيانات من جهاز واحد فقط، يمكنك قراءة البيانات من أكثر من جهاز والذي يجعل النظام أو التطبيق يخدم عدد أكثر من الـ Requests.
ويوجد لدينا بعض الأجهزة الموزعة أو distributed devices بشكل تلقائي مثل الهاتف المحمول.
لماذا نحتاج إلى توزيع البيانات؟
الأجهزة الموزعة توفر لنا الموثوقية أو ما يعرف بالـ Reliability بمعنى إذا حدث خطأ في Node أو أكثر يستمر التطبيق في العمل دون حدوث عطل أو مشكلة وهذا بسبب وجود Redundant Node تقوم بعمل هذه الـ Node، وهذا يجعل التطبيق Fault Tolerant أي متسامح مع وجود الأخطاء.
لا بُد من توزيع الـ Servers أو الخوادم بطريقة سليمة لتقليل وقت استجابة الخادم والذي يسمى بالـ Latency، خصوصًا عندما يكون التطبيق يعمل في أماكن ومناطق جغرافية مختلفة، فعندما يرسل المستخدم Request فيتم إرسال هذا إلى مكان قريب منه؛ والذي يسرع عملية إسترجاع البيانات.
توزيع البيانات يتيح لنا حل مشاكل أكبر مثل عمل معالجة بيانات كثيرة -الـProcessing- على عدد من الأجهزة بشكل أسرع بكثير من معالجتها على جهاز واحد أو عدد أقل من الأجهزة.
ومع كل هذه المميزات للأنظمة الموزعة يوجد عيوب كذلك.
عيوب الأنظمة الموزعة:
1- اعتماد الأنظمة الموزعة على شبكة غير معتمد عليها -Unreliable network-، يجعل من الوارد جدًا حدوث مشاكل في الشبكة تسبب عدم اكتمال الـ Request.
2- عمل تطبيق أو نظام يكون قابل لتحمل الأخطاء Fault Tolerant ليس بالشئ السهل وقد يواجهك العديد من التحديات.
يوجد شكلين للبيانات الموزعة
- إما أن تكون نفس البيانات موجودة على أكثر من جهاز ويطلق عليها “Replication”.
- وإما أن تكون البيانات مقسمة أو مجزأة على أكثر من جهاز ويطلق عليها “Sharding”.
ما هي الـ Data Replication أو تكرار البيانات؟
وجود أكثر من نسخة من نفس البيانات على أكثر من جهاز متصلين بنفس الشبكة.
لماذا نحتاج إلى تكرار البيانات؟
- تقليل وقت الاستجابة – Reduce Latency: بجعل البيانات مخزنة على خادم أو Server قريب جغرافيًا من المستخدم بحيث يجعل الـ Request أسرع.
- زيادة الإتاحة أو التوفر – Increase Availability: إذا حدث عطل في أي جهاز يوجد بديل له يقوم بنفس المهام ومخزن عليه نفس البيانات حتى لا يحدث عطل للنظام.
- زيادة عمليات القراءة – Increase Read Throughput: عندما يوجد Read Load فيمكنك توزيع الـ Reads على أكثر من جهاز، فكل جهاز ينفذ عدد من الـ Requests فيمكنني خدمة عدد أكبر من الـ Requests.
ما هي المشكلة التي نواجهها في عمل تكرار للبيانات؟
دعنا نعرض المشكلة أولًا ثم فيما بعد نعرض حل هذه المشكلة.
في حالة إذا ما كنا سنكرر بيانات لا يحدث عليها أي تغيير، سيكون الحل بأننا نأخذ نسخة من البيانات فقط وانتهى الأمر. ولكن تظهر مشكلة عندما يتم عمل تغييرات بشكل دائم على هذه البيانات، فنحتاج إلى جعل هذه البيانات متسقة مع كل تغيير؛ بمعنى إذا حدث تغيير على البيانات فنحتاج إلى أن تكون النسخ الأخرى هي نسخة طبق الأصل من البيانات الاصلية ولا ينقصها أي بيانات. من خلال هذا المقال سوف نناقش حل هذه المشكلة وما هي المشاكل التي سوف نواجهها.
مثال أولي لتوضيح المشكلة وكيفية حلها:
يوجد لدينا قاعدة بيانات ونحتاج إلى عمل Replica 1 و Replica 2 أي نسختين طبق الأصل منها على جهازين.
ولكن أولًا ما معنى Replica؟
– أي جهاز يوجد عليه نسخة من قاعدة البيانات الخاصة بك.
وبما أن قاعدة البيانات الأصلية سوف يحدث عليها تغييرات وتحديث للبيانات بشكل دوري، فمن المفترض عندما تأتي هذه التحديثات نقوم بعمل commit وإرسال هذه البيانات المحدثة إلى باقي النسخ المطابقة لها. update هنا بمعنى أي write query مثل insert أو delete أو update، فعند حدوث أي تغيير للبيانات سوف نحتاج إلى إرسال هذا التغيير إلى باقي النسخ الموجودة.
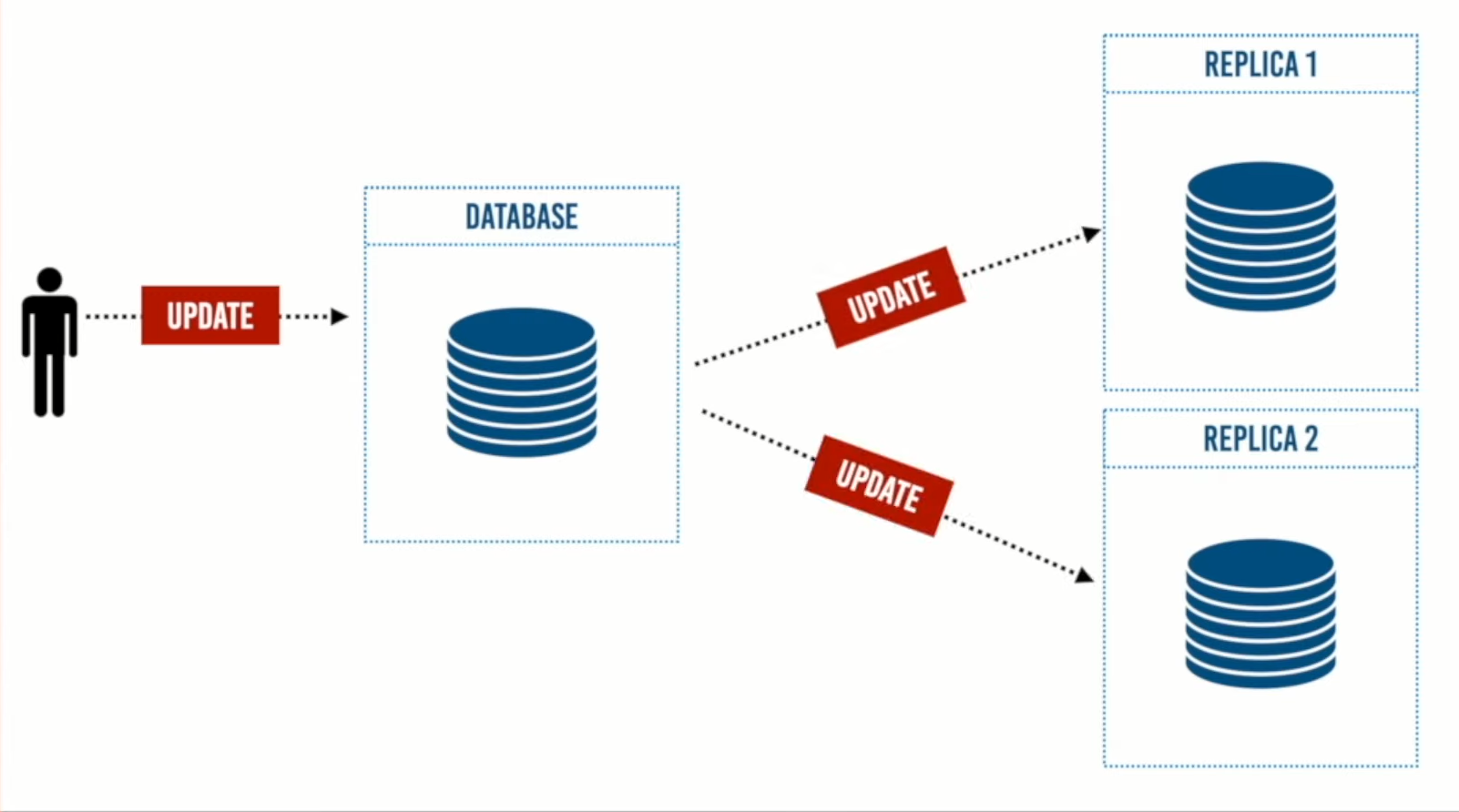
ومن هنا نبدأ بالتفكير في عدة مشاكل:
- كيف يتم إرسال هذه التغييرات هل بطريقة sync أو async؟
- ما هي مميزات وعيوب كل طريقة؟
- ماذا لو حدث خطأ أو عطل في أحد الـ Replicas عند إرسال التعديلات إليها وكيفية استرجاعها؟
- كيفية تهيئة قواعد البيانات على العمل كأنها قاعدة بيانات واحدة -بالنسبة إلى المستخدم عند إرسال التعديلات-؟
- كيف نتعامل مع حدوث خطأ أو فشل في قاعدة البيانات الأصلية؟
Leader-Based Replication أو Single Leader
هي طريقة لعمل تكرار للبيانات.
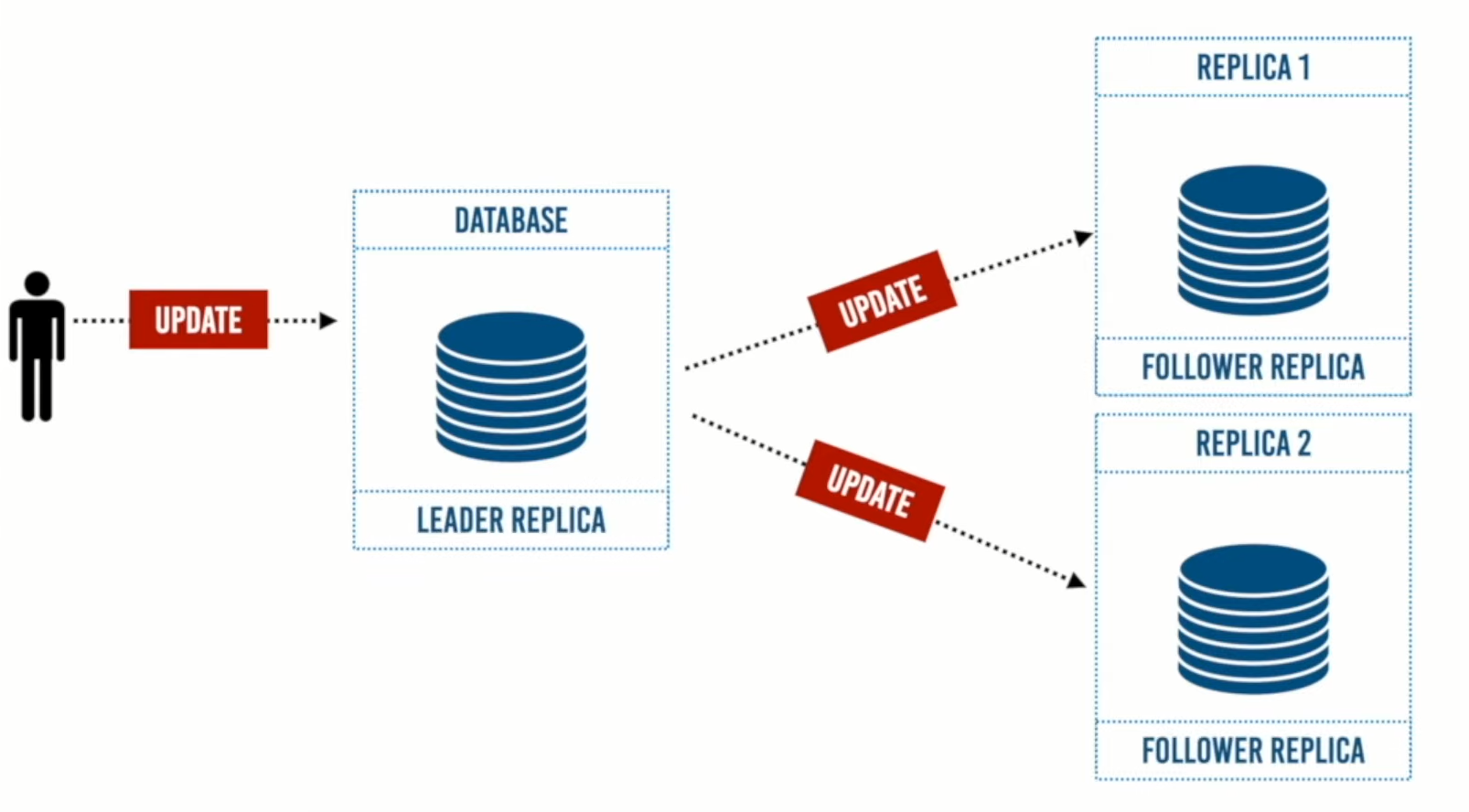
الصورة السابقة توضح عمل Leader Based Replication
الـ Leader Replicaهو الذي يستقبل التحديثات من المستخدم وترسلها إلى النسخ التابعة Follower Replica، وفي هذه الطريقة ال Leader Replica يأتي إليه عمليات القراءة والتحديث بينما النسخ التابعة لها يأتي إليها عمليات القراءة فقط.
وهذا النهج هو الأكثر شهرة واستخدامًا وموجود بشكل مدمج في معظم قواعد البيانات الشهيرة مثل postgreSQL و SQL و Oracle وSQL Server MongoDB و RethinkDB وEspresso DB. بالإضافة انها موجودة في Message Broker مثل Kafka وRabbitMQ، بل يمكنك تهيئة قاعدة البيانات التي تعمل بها مع أي طريقة على حسب أي من هذه الطرق مناسبة للتطبيق الخاص بك.
كيف يتم إرسال التحديثات في هذا النهج إلى النسخ التابعة بطريقة Sync أم Async؟
يتم تحديد طريقة الإرسال بـ Sync أو Async طبقًا لما يرسله الـLeader Replica للمستخدم أنه تم إضافة أو تعديل بيانات.
1. طريقة الـ Async
في نهج الـ Async، عند قيام المستخدم بإرسال تحديث للبيانات، يقوم زعيم النسخ بإرسال تأكيد لحظي بنجاح عملية تحديث البيانات، دون التأكد من تطبيق هذه التغييرات على النسخ التابعة له.
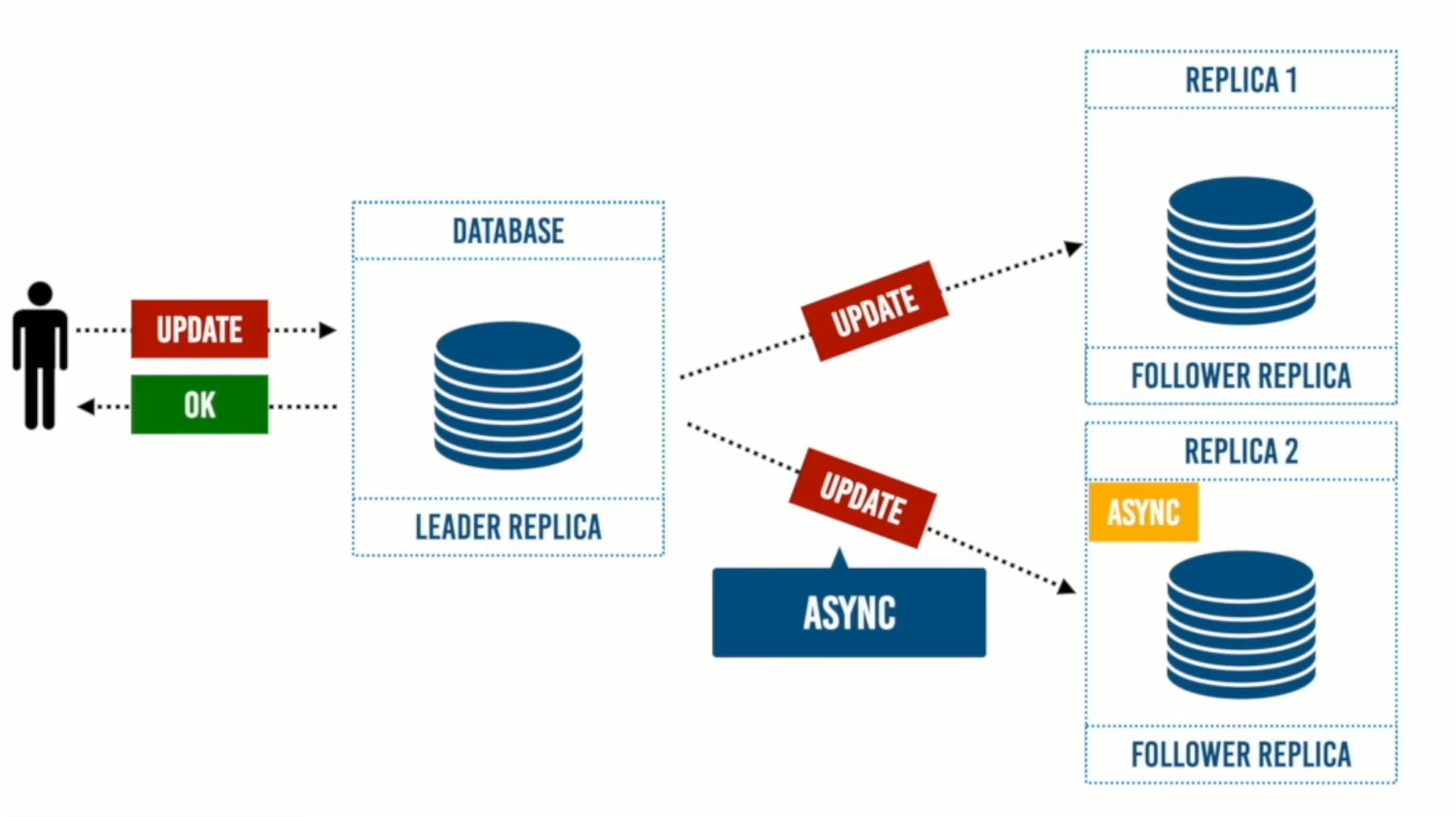
في هذا المثال سوف نجعل النسخة رقم 2 هي Async ونرى ما الذي يحدث بدايًة من إرسال المستخدم للتحديثات. يرسل المستخدم التحديث إلى الـLeader Replica ثم يتم عمل commit لهذه التحديثات من خلال إرسال التحديثات إلى الـ Follower Replica. في هذا النهج لا ينتظر الـ Leader Replica أي رد من Async Replica ثم يرسل إلى المستخدم أنه تم تحديث البيانات بنجاح، دون اخبار الـ Leader Replica هل تم إضافة أو تحديث البيانات بنجاح أم لا.
فهي طريقة سريعة لأنها ترسل الرد سريعًا إلى المستخدم دون انتظار أي وقت والذي يتم فيه إضافة أو تحديث البيانات، والذي قد يأخذ بعض الوقت من ثوان وقد يصل إلى عدة دقائق تعتمد على سعة النظام.
وبالرغم من أن هذه الطريقة سريعة ولكن يوجد بها مشاكل:
- عدم التأكد من وجود البيانات في الـ Follower Replica ومن الممكن إرسال المستخدم طلب لقراءة البيانات التي تم إدخالها في الحال ولا يجدها!
- يوجد أي ضمانات عند وقوع أو حدوث عطل في الـ Leader Replica أن التحديثات تم إرسالها إلى الـ Follower Replica وسيتم ضياع هذه البيانات.
2. طريقة الـ Sync أو Synchronous
في نهج الـ Sync لا يتم إرسال acknowledge تحديث للبيانات من خلال الـ Leader Replica إلى المستخدم حتى يتم الرد بنجاح عملية التحديث من خلال الـ Follower Replica إلى الـ Leader Replica وإرسال acknowledge لها بأن تم تحديث البيانات بنجاح.
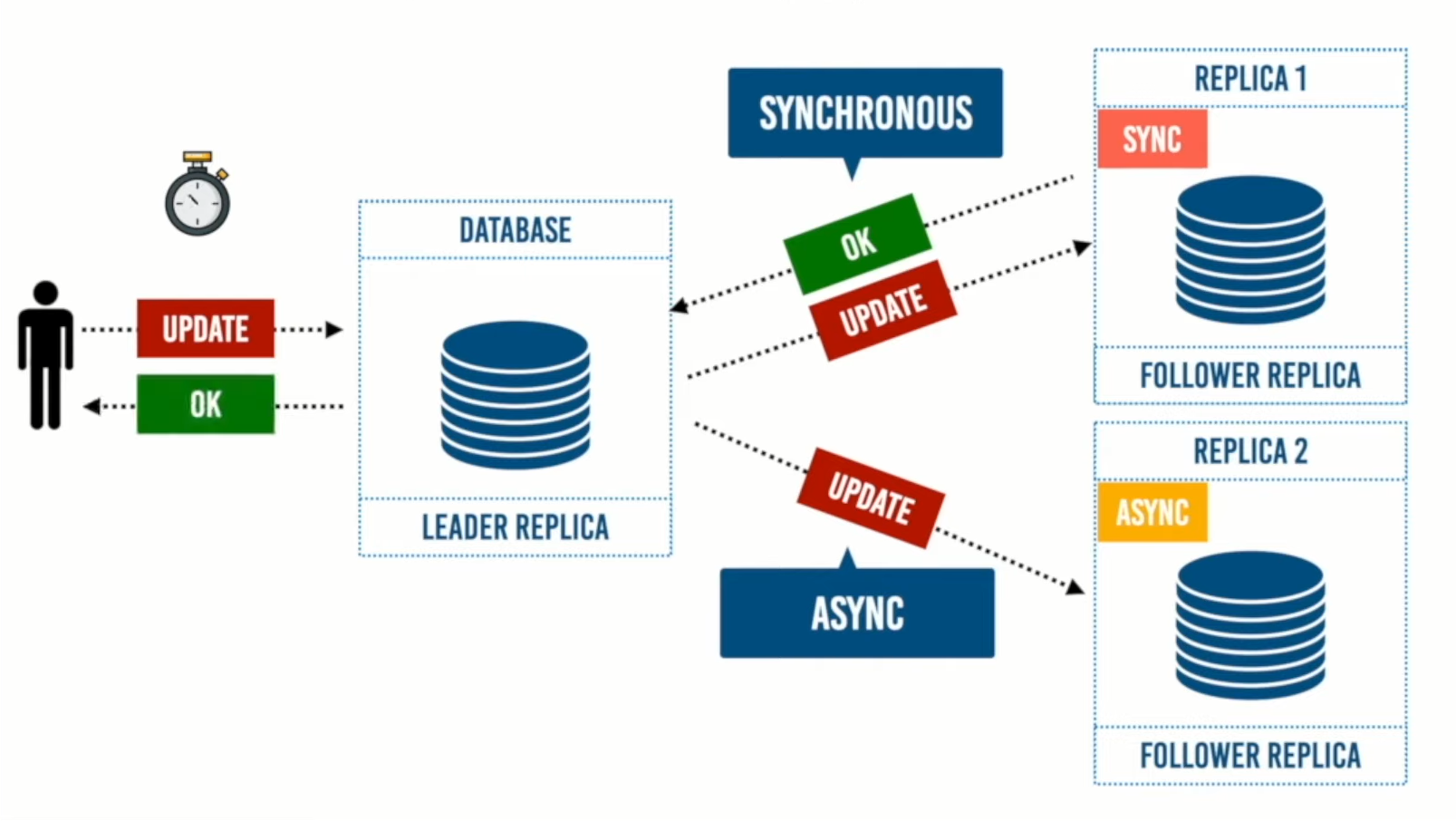
في هذا المثال سوف نجعل النسخة رقم 1 هي Sync ونرى ما الذي يحدث بدايًة من إرسال المستخدم للتحديثات.
- يرسل المستخدم التحديثات إلى الـ Leader Replica ومن خلالها يتم عمل commit للتحديثات وإرسالها إلى الـ Follower Replica أو Replica 1
- ثم ينتظر الـLeader Replica حتى يتم الرد عليه من خلال الـ Follower Replica بأنه تم تحديث البيانات.
- ثم يرسل الـ Leader Replica للمستخدم بأنه تم تحديث البيانات بنجاح.
وفي هذه الطريقة، يضطر المستخدم للانتظار لوقت أطول من طريقة الـ Async لحين استقبال الرد من الـ Follower Replica عكس الـ Async.
ولكن يوجد مشكلة في طريقة الـ Sync خلاف انتظار المستخدم لوقت أطول، انه يتم حجب جميع عمليات التحديث في الـ Leader Replica إلى حين إرسال تأكيد بنجاح عملية التعديل من خلال الـ Follower Replica؛ مما يعني في حالة حدوث عطل في النسخة الـ Async مثل مشاكل في الشبكة أو إنهيار بها، يتعطل كل النظام إلى حين إرسال النسخة الـ sync الرد إلى الـ Leader Replica.
المعظم يفضلون استخدام طريقة Hybrid بمعنى وجود نسخة واحدة تعمل بطريقة الـ Sync وتعمل باقي النسخ بطريقة الـ Async
كيف نضيف Follower Replica جديدة مع التأكد من أنها تملك نسخة طبق الأصل من الـ Leader Replica؟
تكمن المشكلة في إضافة الـ Follower Replica هي عدم حجب عمليات التحديث الجارية على الـ Leader Replica، حيث ذلك ينتهك أحد أهداف إنشاء نسخ موزعة وهي الـ availability أو الإتاحة.
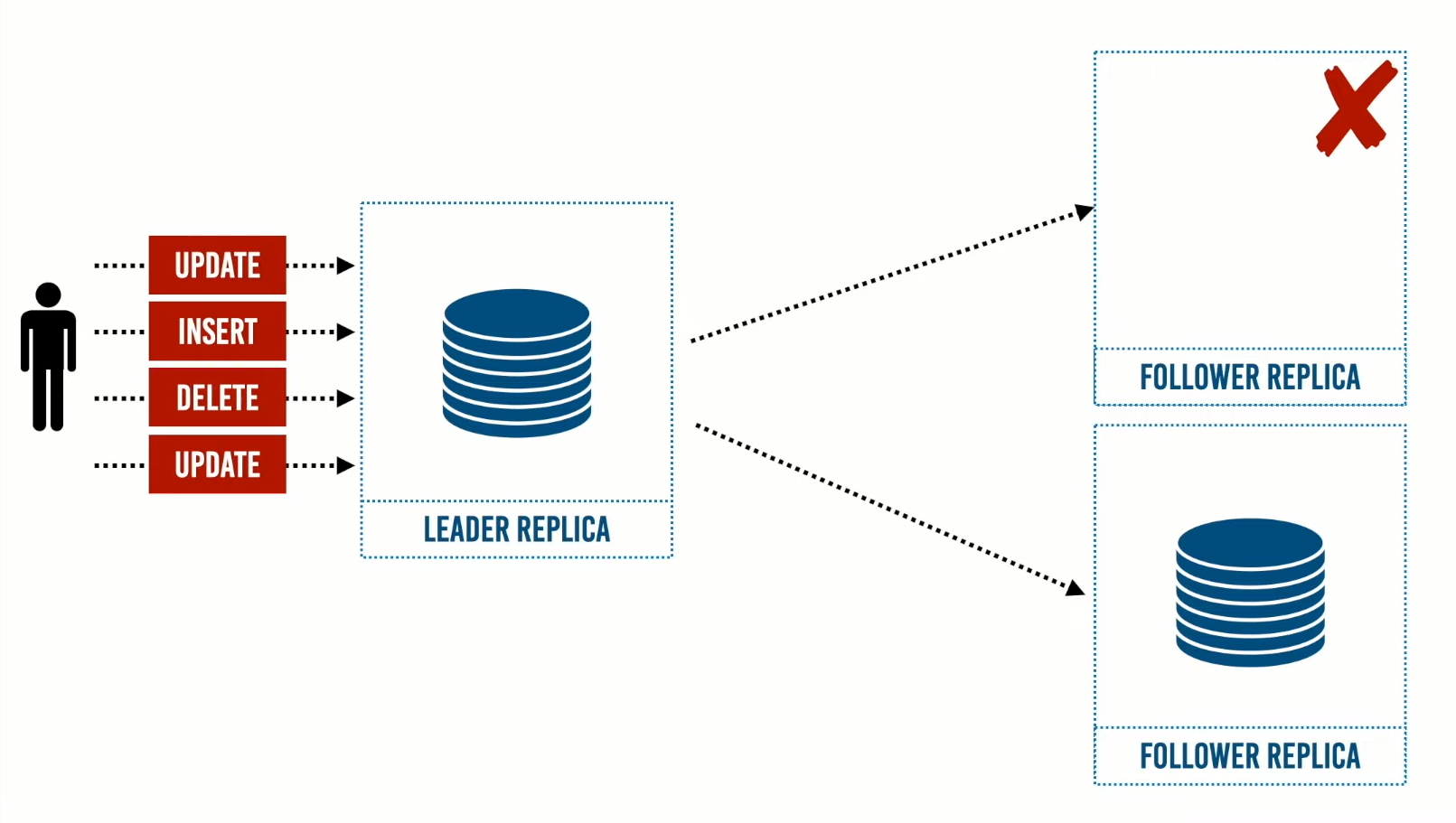
ما هي الحلول التي توفرها قواعد البيانات لحل هذه المشكلة وما هي الخطوات التي نحتاجها لبناء نسخة طبق الأصل من الـ Leader Replica؟
أولًا الـ Leader Replica تحتوي على snapshot وتعمل كنسخة إحتياطية Backup.
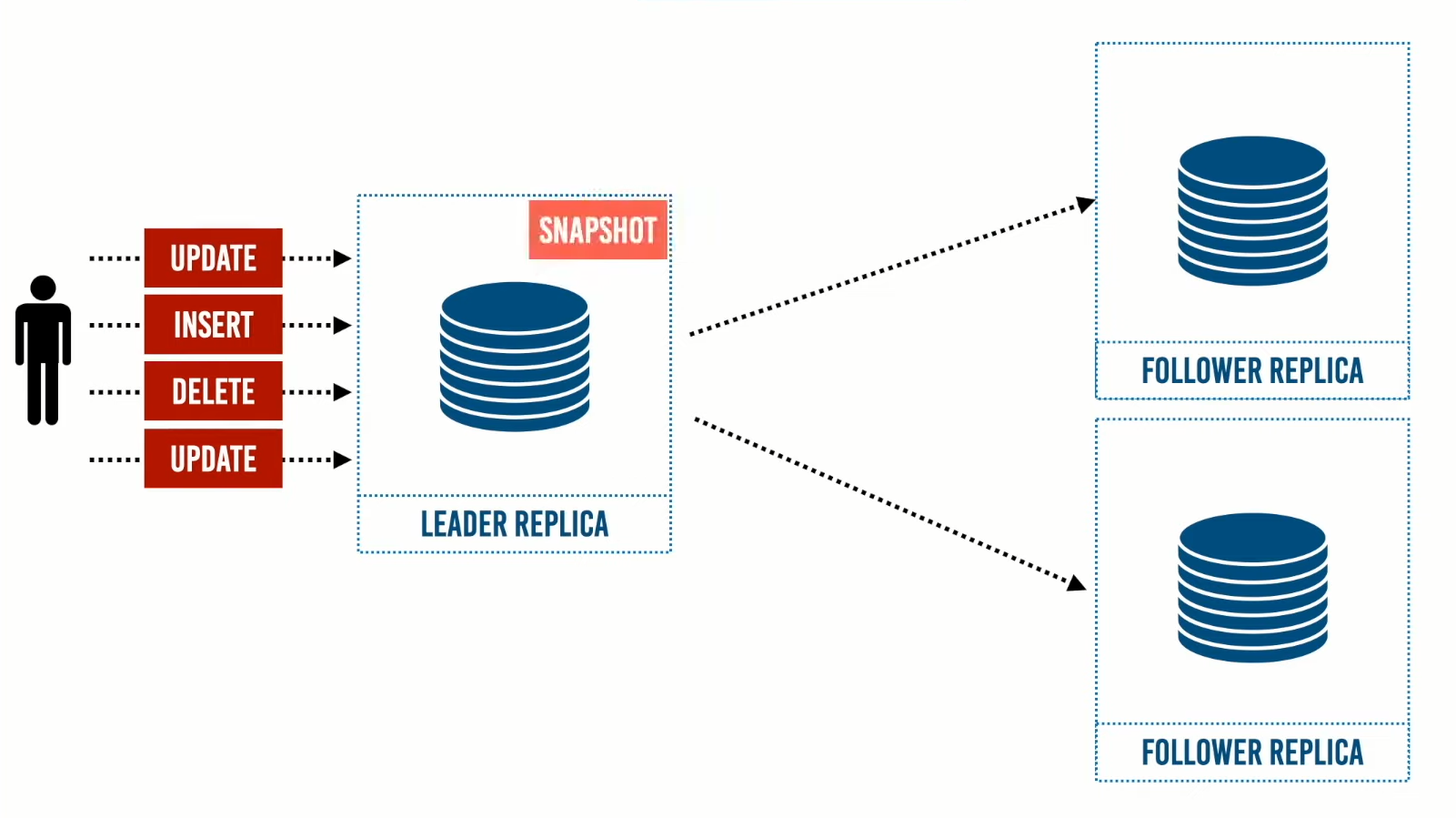
فعند إنشاء Follower Replica جديدة،تقوم تقوم تلك النسخة بطلب snapshot الخاصة بالـ Leader Replica ومن خلال الـ snapshot تبدأ في بناء قاعدة البيانات الخاصة بها.
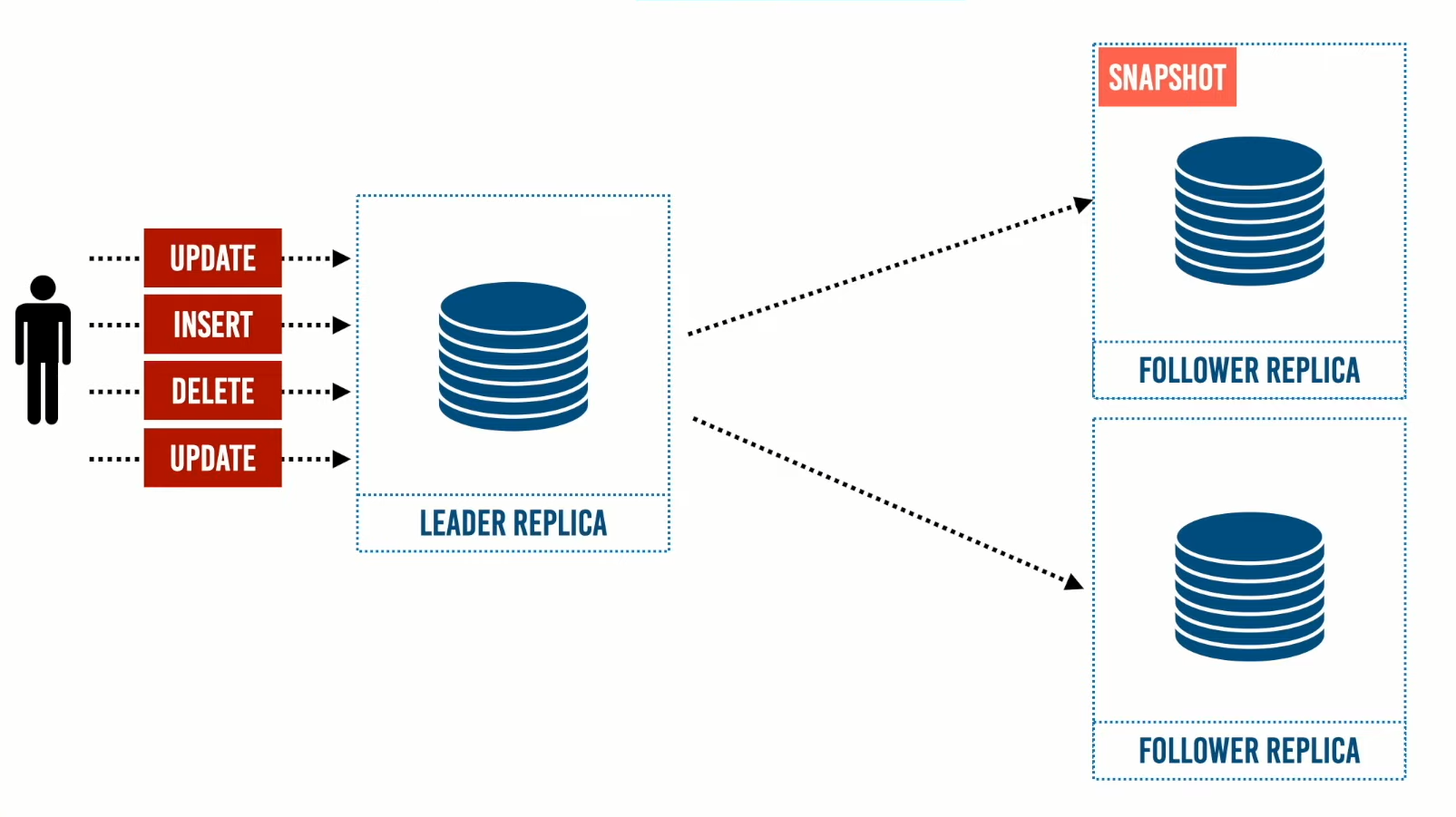
عند إنشاء الـ Follower Replica يكون لديها نسخة قديمة من البيانات، وتقوم ال Follower Replica بطلب التحديثات الموجودة عند الـ Leader Replica لإستكمال البيانات الخاصة بها. والذي يكون لديه log sequence number ومن خلال هذا الرقم يمكن معرفة إذا كان الـ Follower Replica أرسل إليه لإسترجاع البيانات بداية من هذا الرقم فيرسل إليه البيانات الجديدة لاستكمال النسخة الخاصة به، والتي تكون نسخة مطابقة للنسخة الأصلية، وبعد إرسال التحديثات أصبحت الـ Follower Replica جاهز لدخول النظام وتسمى هذه العملية بـ Catch-up Recovery.
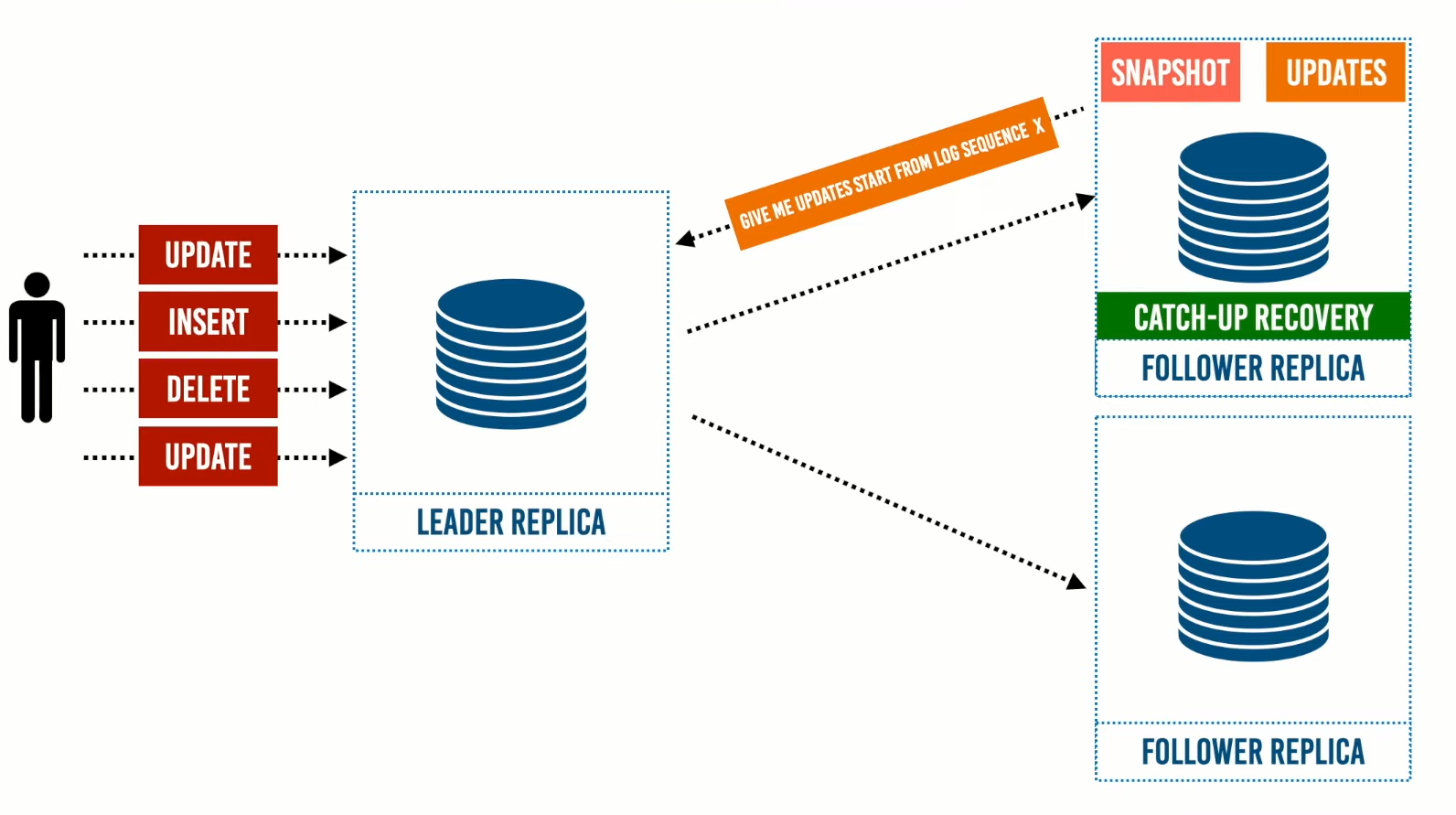
بناء Follower Replica جديدة ومعرفة جميع التفاصيل الخاصة ببنائها مهمة لأن الهدف الرئيسي تحقيق ال high availability بمعنى إذا حدوث عطل لـ Replica معينة يكون النظام قادرًا على العمل لحين إنشاء Replica جديدة، وتقليل الوقت لإنشاء Replica جديدة غاية في الأهمية لتحقيق إتاحة قاعدة البيانات ،يمثل القدرة على إعادة تشغيل أحد النسخ في أسرع وقت عملية غاية في الأهمية
كيف نحقق الـ high availability باستخدام طريقة الـ Leader Base Replication؟
لتحقيق الـ high availability لابد من التأكد من أن عملية استرجاع الـ Replica تتم بدون وجود أي مشكلة وبدون وقت تعطيل لهذه الـ Replica.
كيف نقوم ببناء Leader Replica جديد؟
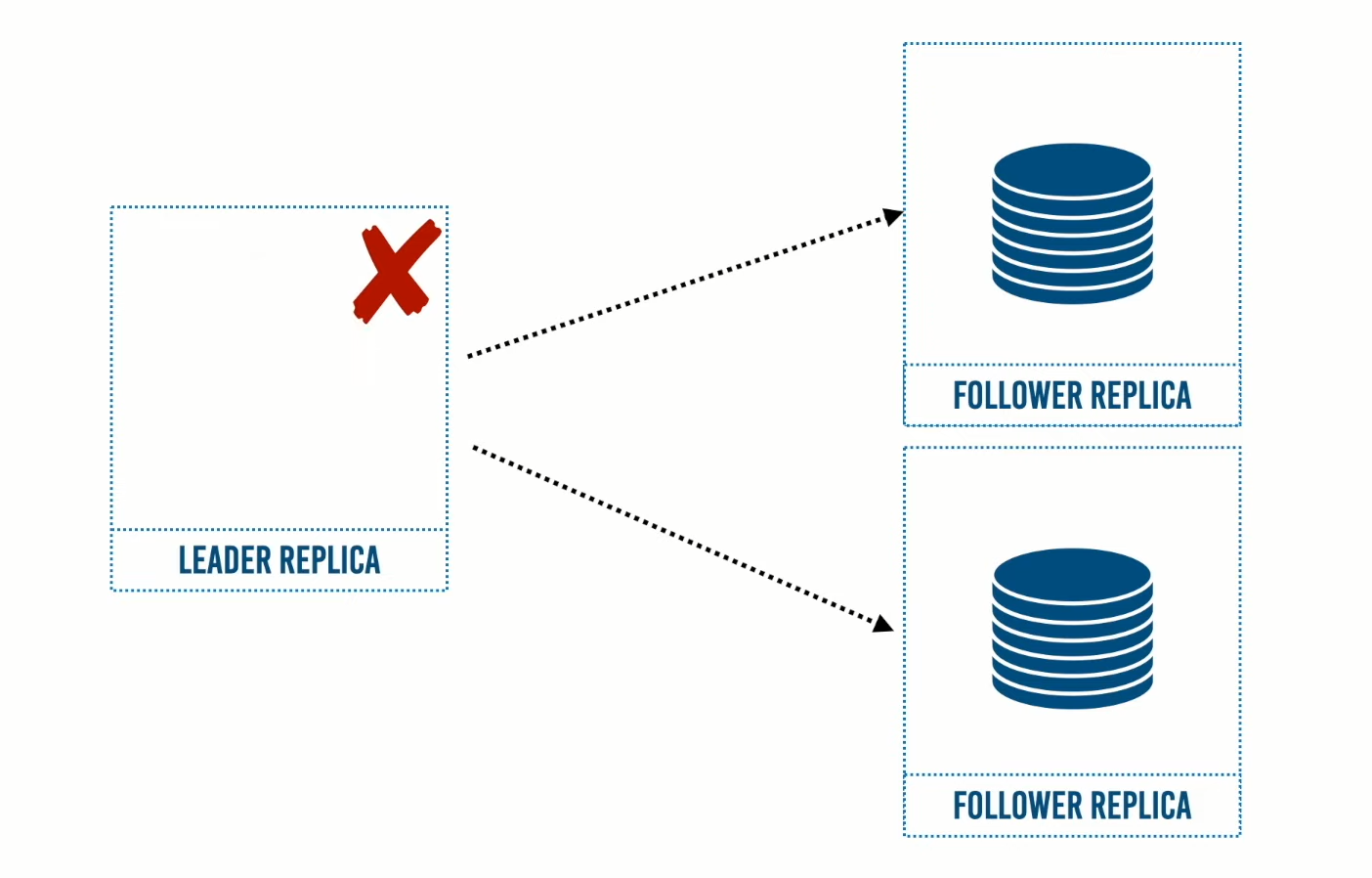
أولًا إذا تعطل الـ Leader Replica يحل محله منه أحد الـ Followers Replica ويتم تحويل الـ requests إلى الـ Leader Replica الجديد ويتم اختيار ذلك الزعيم بناءًا على أي النسخ تملك أحدث نسخة من البيانات.
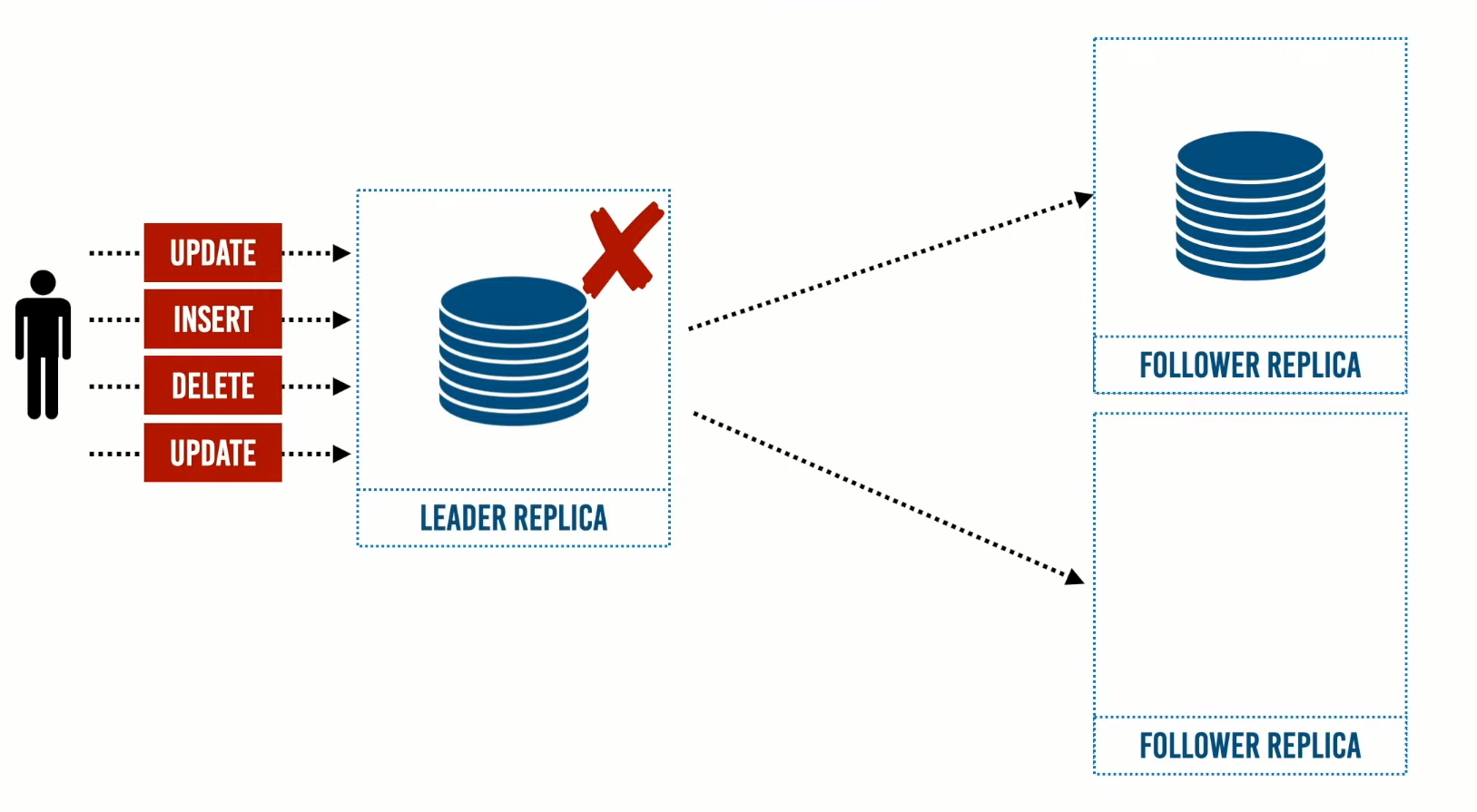
أولًا إذا تعطل الـ Leader Replica يحل محله منه أحد الـ Followers Replica ويتم تحويل الـ requests إلى الـ Leader Replica الجديد ويتم اختيار ذلك الزعيم بناءًا على أي النسخ تملك أحدث نسخة من البيانات.
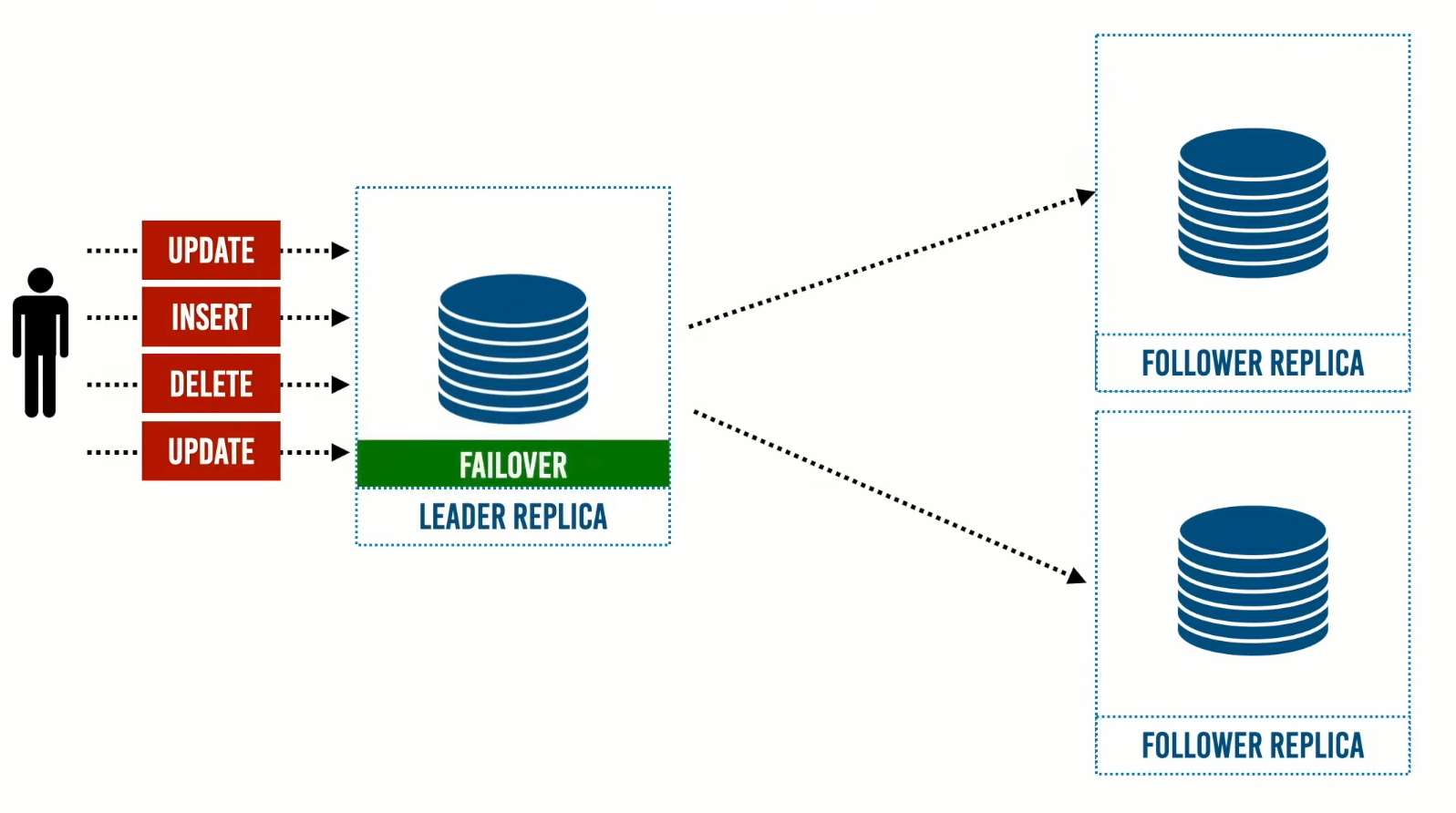
هل بناء الـ Leader Replica بهذه السهولة؟
إذا كنت تعمل بنهج ال Async فمن الممكن أن الـ Follower الذي أصبح Leader لا يملك البيانات كاملة وسوف نفقد جزءًا من التحديثات التي كان يمتلكها الـ Leader القديم فقبل اختيار هذه الطريقة يجب أن تعلم أنه من الوارد فقد جزء من تلك التحديثات والذي قد يسبب العديد من المشاكل.
يوجد مشكلة أخرى في بعض الأحيان، حيث يفترض النظام بأن الـ Leader أصبح غير موجود أو مفقود لأنه مر وقت معين بدون إسترجاع أي رد منه، ولكن كان عليه يوجد عليه load أو حمولة أو تم استرجاع الـ Leader سريعا ولكنه قد تم بالفعل إنشاء Leader جديد قبل استرجاع الـ Leader القديم.
في بعض الأحيان، الـ Leaders يستقبلون write queries تسبب مشكلة تسمى Split Brain، وبسبب عدم وجود طريقة لحل التداخل بين الـ Leaders فسوف نضطر لفقد بيانات أحدهما وبعض الأنظمة تعفي أحدهما لتجنب هذه المشكلة.
كيف يتم إرسال التحديثات من الـ Leader إلى الـ Followers؟
يوجد أكثر من طريقة تستخدمها قواعد البيانات داخليا:
- طريقة الـ Statement Base Replication: وهي طريقة يرسل الـ Leader الـLog الخاص بالـ write queries كـ SQL statement بمعنى أنه يتم تنفيذ هذا الأمر بداخل الـ Leader ثم يرسل الـ query بنفس الشكل إلى الـFollowers Replica ثم يتم تنفيذها داخل الـ Followers.
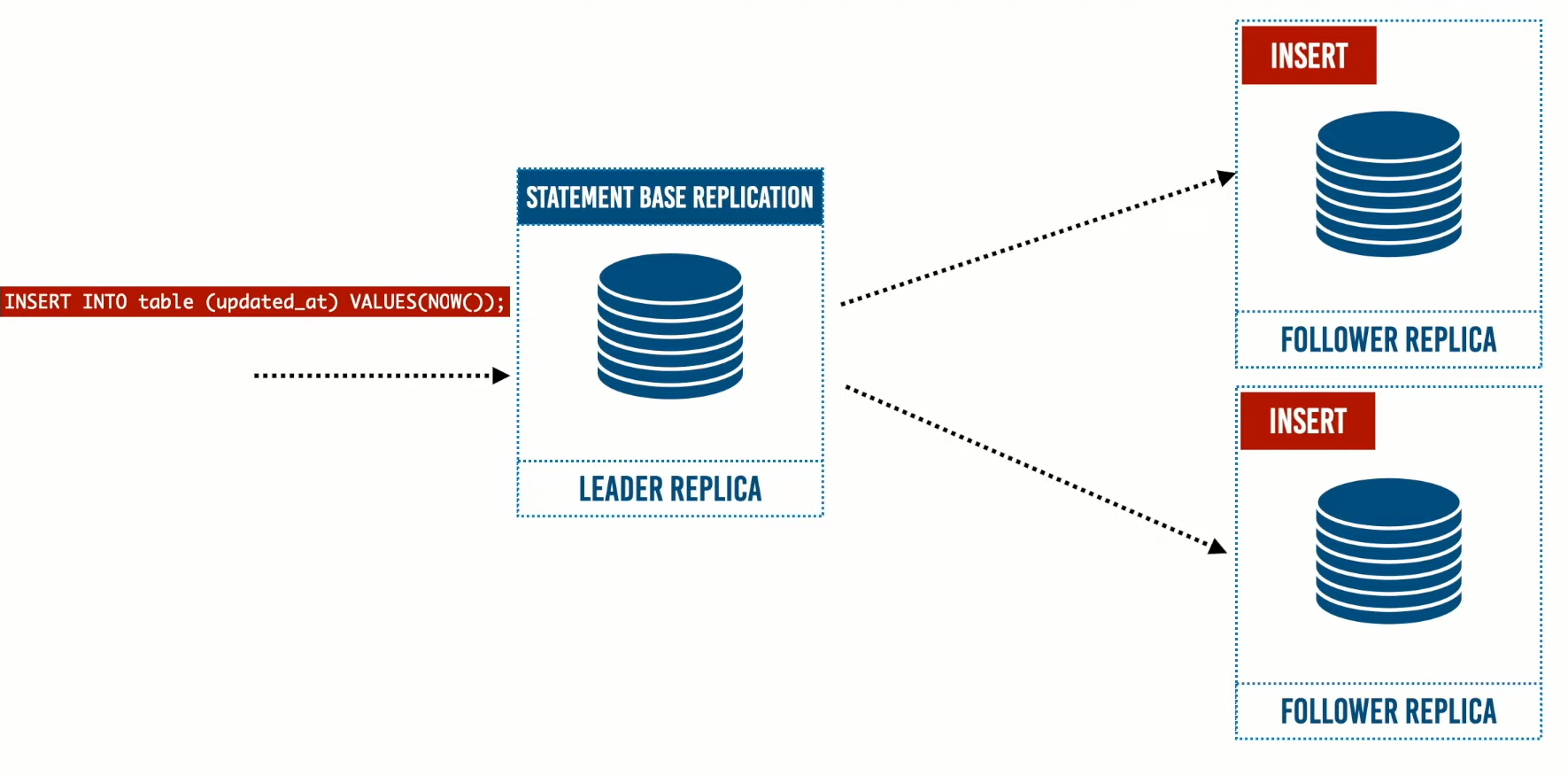
قد تبدو أن هذه الطريقة بسيطة ولكن يوجد بها العديد من المشاكل ومنها:
يوجد بعض الـ queries تستخدم built-in functions مثل NOW ونتيجة هذه الدوال تكون غير حتمية والناتج الخاص بهذه الدوال يتغير على حسب كل مرة يتم تنفيذها، وهذا يؤدي إلى اختلاف البيانات بين الـ Leader وال Followers لأن عندما ننفذ هذه الدوال في الـ Leader سنحصل على نتيجة وعند تنفيذ هذه الدوال مرة أخرى في الـ Followers سنحصل على نتيجة مختلفة كما يوجد في دالة NOW الوقت الناتج في الـ Leader مختلف عن الوقت الناتج في الـ Follower.
وحل هذه المشكلة أن الـLeader لا يرسل أي هذه الأوامر ولكن ينفذها ويحصل على النتيجة ويرسلها. هذا النهج كان مستخدم في MySQL إلى الإصدار الخامس وتم استبداله بالـ Row Based Replication.
- طريقة الـ Write Ahead طريقة الـ Write Ahead Log أو WAL:وهنا ال Log عبارة عن ملفات صغيرة تُدمج ويحدث لها garbage collected في الـ background. بعدما يستقبل الـLeader التحديثات سيتم كتابة هذا الـ Log في الـ Tree الخاصة به ثم يتم ارسال نفس الـ log إلى الـ Followers لبناء نسخة مشابهة من قاعدة البيانات الموجودة في الـLeader.
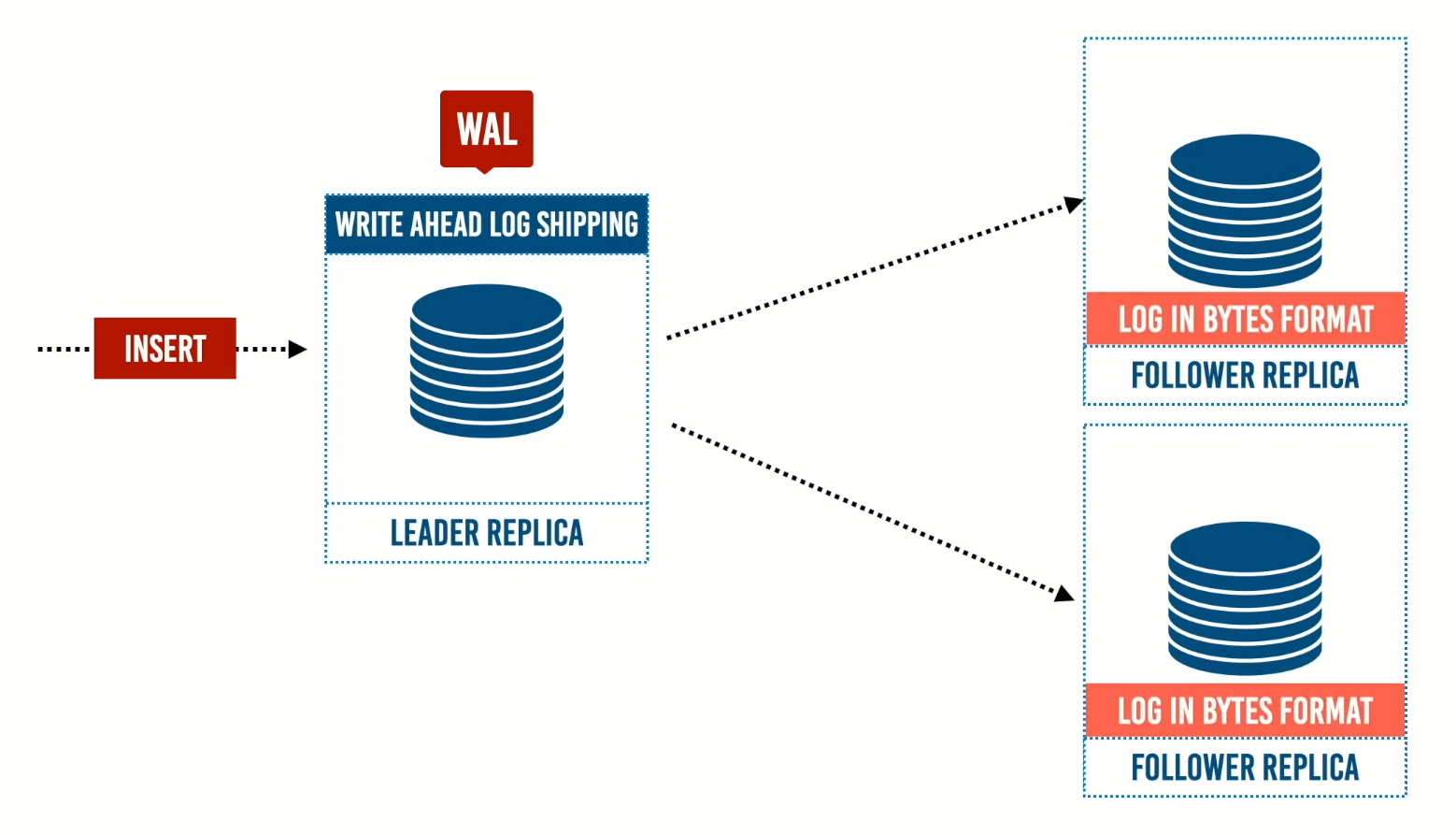
وهذه الطريقة مستخدمة في PostgreSQL وOracle ولكن لديها مشكلة بأنها تعتمد على البيانات وهي في صورتها low level وتعتمد أكثر على storage engine لذلك تسمى physical log replication.
- طريقة الـRow Based Log Replication: تسمى أيضا بـLogical log replication،وهي Logical لأنها لا تعمل على طبقة الـ engine مثل الـ physical ، وهي تعتمد على التحديثات التي تحدث على الـ Raw data بمعنى أن الـLeader يستقبل التحديثات ثم ينشئ الـraw record لديه ثم يرسله إلى الـ Followers Replica في شكل row.
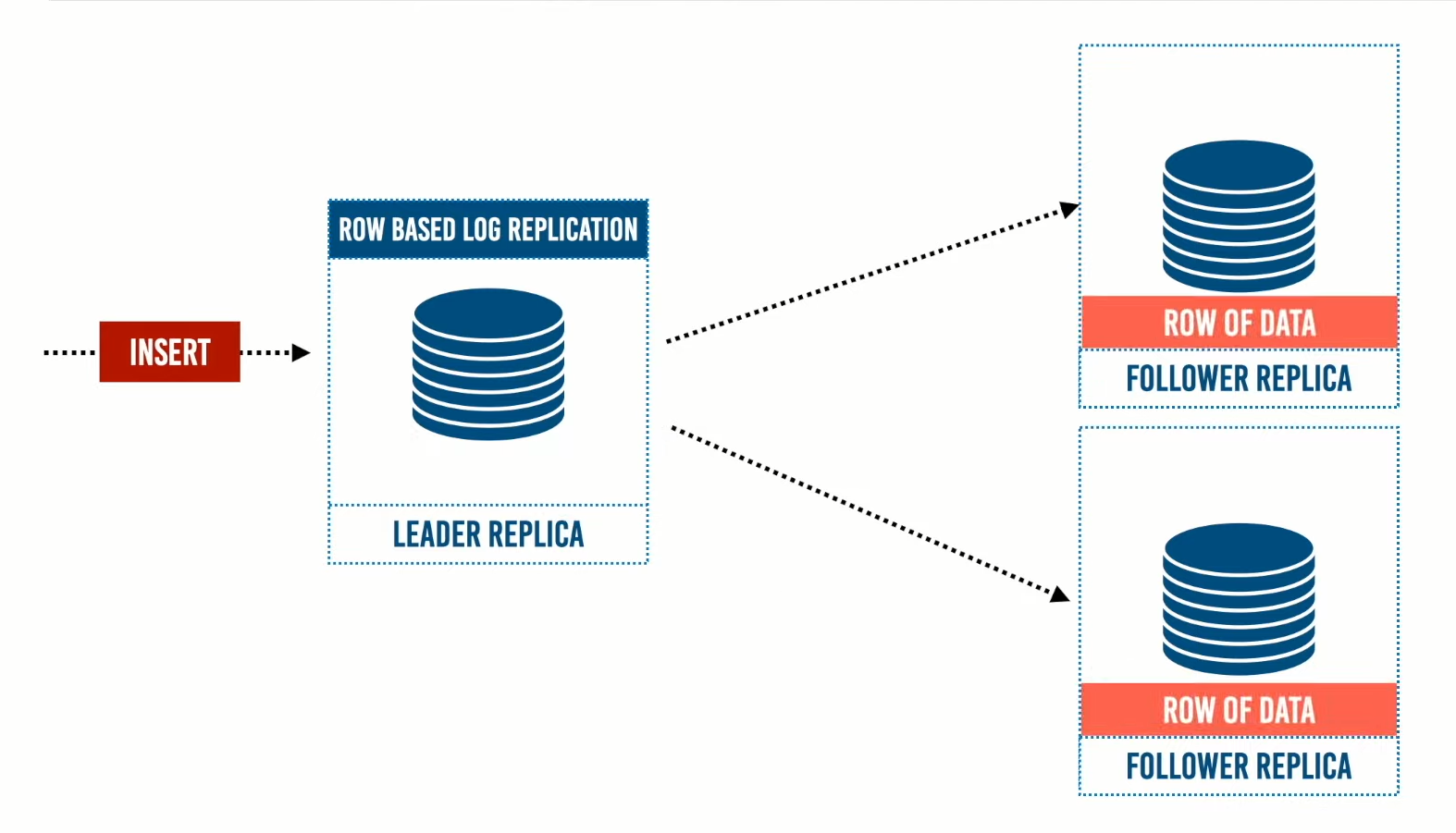
فعند مسح row معين نرسل الـid الخاص به مرفق بنوع العملية من نوع DELETE، فيتم مسحه من الـ Follower Replica، وإذا كانت العملية تحديث فيتم إرسال الـ row id مع البيانات التي تم تغييرها في شكل key value وتقوم النسخة بتغيير البيانات بداخلها.
وتعتبر هذه الطريقة من أفضل الطرق وأسهلها وخاصة عند إرسال البيانات إلى نظام خارجي أو external system مثل إرسال البيانات إلى data warehouse لعمل تحليل على البيانات. وهذه الطريقة مفيدة ايضا عند احتياج البيانات في الـcache أو لبناء custom index.
















Discussion